728x90
반응형
import pandas as pd
data = pd.read_csv('academy1.csv')
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32 entries, 0 to 31
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 학번 32 non-null int64
1 국어점수 32 non-null int64
2 영어점수 32 non-null int64
dtypes: int64(3)
memory usage: 896.0 bytes
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3)
km.fit(data.iloc[:,1:])
aaa = km.fit_predict(data.iloc[:,1:])
import mglearn
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family = 'Malgun Gothic')
mglearn.plots.plot_kmeans_algorithm()
plt.show()
mglearn.plots.plot_kmeans_boundaries()
plt.show()
mglearn.discrete_scatter(data.iloc[:,1], data.iloc[:,2], km.labels_)
plt.legend(["클러스터 0","클러스터 1","클러스터 2"], loc='best')
plt.xlabel("국어점수")
plt.ylabel("영어점수")
plt.show()
# 국어점수 100점, 영어점수 80점인 학생은 몇번 클러스터?
km.predict([[100, 80]])
# 0번 클러스터
# array([0])
data = pd.read_csv('academy2.csv')
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 18 entries, 0 to 17
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 학번 18 non-null int64
1 국어점수 18 non-null int64
2 영어점수 18 non-null int64
3 수학점수 18 non-null int64
4 과학점수 18 non-null int64
5 학업성취도 18 non-null int64
dtypes: int64(6)
memory usage: 992.0 bytes
km = KMeans(n_clusters = 3)
km.fit(data.iloc[:,1:])
aaa = km.fit_predict(data.iloc[:,1:])
mglearn.plots.plot_kmeans_algorithm()
plt.show()
mglearn.plots.plot_kmeans_boundaries()
plt.show()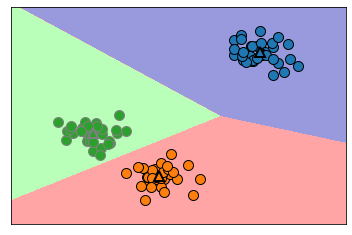
mglearn.discrete_scatter(data.iloc[:,1], data.iloc[:,2], km.labels_)
plt.legend(["클러스터 0","클러스터 1","클러스터 2"], loc='best')
plt.xlabel("국어점수")
plt.ylabel("영어점수")
plt.show()
km.predict([[100, 80, 70, 70, 70]])
# array([0])
km.labels_
# array([0, 0, 2, 0, 0, 2, 0, 0, 2, 1, 0, 2, 1, 0, 2, 1, 0, 2])
for no, cla in enumerate(km.labels_) :
print(data.iloc[no].tolist(), cla)
[1, 90, 80, 80, 80, 80] 0
[2, 90, 75, 75, 75, 75] 0
[3, 65, 90, 90, 90, 90] 2
[4, 90, 80, 80, 80, 80] 0
[5, 90, 75, 75, 75, 75] 0
[6, 65, 90, 90, 90, 90] 2
[7, 90, 80, 80, 80, 80] 0
[8, 90, 75, 75, 75, 75] 0
[9, 65, 90, 60, 88, 80] 2
[10, 90, 80, 60, 30, 40] 1
[11, 90, 75, 85, 60, 70] 0
[12, 65, 90, 60, 88, 80] 2
[13, 90, 30, 40, 30, 40] 1
[14, 90, 60, 70, 60, 70] 0
[15, 65, 88, 80, 88, 80] 2
[16, 90, 30, 40, 30, 40] 1
[17, 90, 60, 70, 60, 70] 0
[18, 65, 88, 80, 88, 80] 2
from sklearn.cluster import DBSCAN
model = DBSCAN()
model.fit(data.iloc[:,1:])
clusters = model.fit_predict(data.iloc[:,1:])
mglearn.discrete_scatter(data.iloc[:,1], data.iloc[:,2], model.labels_)
plt.legend(['클러스터 0','클러스터 1','클러스터 2'], loc = 'best')
plt.xlabel('국어점수')
plt.ylabel('영어점수')
plt.show()
# kmeans
# 성능이좋다. 군집에 많이 사용됨
랜덤으로 만들고 하나하나 만들어감
원 형일 때 좋음
클러스터개수 수동설정
dbscan 밀집도 기준으로 구분
클러스터 자동
반응형
'Data_Science > Data_Analysis_Py' 카테고리의 다른 글
| 40. Tensorflow를 통한 논리구현 (0) | 2021.11.25 |
|---|---|
| 39. Tensorflow 구현 (0) | 2021.11.25 |
| 37. iris || Kmeans (0) | 2021.11.25 |
| 36. 강남역 고기집 후기분석 || 감성분석 (0) | 2021.11.25 |
| 35. 강남역 고기집 감성분석 || 감성분석, TF-IDF (0) | 2021.11.25 |