from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
iris = load_iris()
dt_clf = DecisionTreeClassifier()
train_data = iris.data
train_label = iris.target
# 학습 fit
dt_clf.fit(train_data, train_label)
# 학습 데이터 셋으로 예측 수행
pred = dt_clf.predict(train_data)
print('예측 정확도:',accuracy_score(train_label,pred))
# 예측 정확도 1.0 : 100% => 잘못된 결과 => train_data 학습 후 예측도 동일 데이터
# 좋은 모델, 좋은 실력은 학습, 테스트 내용이 달라도 결과가 거의 동일해야 함
# 예측 정확도: 1.0
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
dt_clf = DecisionTreeClassifier( )
iris_data = load_iris()
# x feature, y label
# 학습, 테스트 분리 함수 train_test_split(featureset, target, 학7:테3, 시드번호)
X_train, X_test,y_train, y_test= train_test_split(iris_data.data, iris_data.target,
test_size=0.3, random_state=121)
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_))
# refit=True로 설정된 GridSearchCV 객체가 fit()을 수행 시 학습이 완료된 Estimator를 내포하고 있으므로 predict()를 통해 예측도 가능.
pred = grid_dtree.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
# GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
# GridSearchCV 최고 정확도: 0.9750
# 테스트 데이터 세트 정확도: 0.9667
# GridSearchCV의 refit으로 이미 학습이 된 estimator 반환
estimator = grid_dtree.best_estimator_ #
# GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
# 테스트 데이터 세트 정확도: 0.9667
피처feature는 데이터 세트의 일반 속성(attribute) 머신러닝은 2차원이상의 다차원 데이터에서도 많이 사용되므로 넓은, 범용의 타겟값을 제외한 나머지 속성을 모두 피처로 지칭
target(value), decision(value) - 지도학습시 학습위한 정답데이터 label, class은 지도학습 중 분류의 경우 결정 값을 레이블 또는 클래스로 지칭
분류(classfication)는 다양한 피처와 결정값, 레이블을 모델로 학습한뒤, 별도의 테스트 데이터 세트에서 미지의 레이블 예측 // 학습데이터 세트 & 테스트 데이터세트(성능평가용)
1) 데이터 세트분리 - 학습, 테스트 데이터 분리
2) 모델학습 - 학습 데이터 기반 학습
3) 예측수행 - 학습된 모델을 이용해 테스트 데이터의 분류(붓꽃 종류) 예측 4) 평가 - 예측된 결과값, 테스트 데이터의 실제 결과값 비교해 평가
# 사이킷런 버전 확인
import sklearn
print(sklearn.__version__)
# 0.23.2
** 붓꽃 예측을 위한 사이킷런 필요 모듈 로딩 **
from sklearn.datasets import load_iris # 내장 데이터 셋 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split # 테스트데이터 분리 함수
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, # X 피처, Y 타겟 test, train분리
test_size=0.2, random_state=11)
** 학습 데이터 세트로 학습(Train) 수행 **
# DecisionTreeClassifier 객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 학습 수행
dt_clf.fit(X_train, y_train)
# DecisionTreeClassifier(random_state=11)
** 테스트 데이터 세트로 예측(Predict) 수행 ** 별도의 데이터로 수행
# 학습이 완료된 DecisionTreeClassifier 객체에서 테스트 데이터 세트로 예측 수행.
pred = dt_clf.predict(X_test)
print(type(titanic_groupby))
print(titanic_groupby.shape) # 원래는 col이 12개인데 pclass가 index가 되면서 col이 11개가 됨
print(titanic_groupby.index) # index는 name 이 pclass
# <class 'pandas.core.frame.DataFrame'>
# (3, 11)
# Int64Index([1, 2, 3], dtype='int64', name='Pclass')
titanic_groupby = titanic_df.groupby(by='Pclass')[['PassengerId', 'Survived']].count() # 또 특정 col 만 모으기 가능 브레이킷
titanic_groupby
PassengerId Survived
Pclass
1 216 216
2 184 184
3 491 491
titanic_df[['Pclass','PassengerId', 'Survived']].groupby('Pclass').count()
# 순서 상관없음 // col 먼저 따지면 메모리 최소화하기도 // 기존이 된 pclass는 무조건 넣어줘야함
PassengerId Survived
Pclass
1 216 216
2 184 184
3 491 491
RDBMS의 group by는 select 절에 여러개의 aggregation 함수를 적용할 수 있음.
Select max(Age), min(Age) from titanic_table group by Pclass
판다스는 여러개의 aggregation 함수를 적용할 수 있도록 agg( )함수를 별도로 제공
titanic_df.groupby('Pclass')['Age'].agg([max, min]) # 여러개를 .max().min()이 안되서 agg([ , ])로 수행
max min
Pclass
1 80.0 0.92
2 70.0 0.67
3 74.0 0.42
딕셔너리를 이용하여 다양한 aggregation 함수를 적용
agg_format={'Age':'max', 'SibSp':'sum', 'Fare':'mean'} # 각컬럼에 각기 다른 함수를 부여하고 싶다면 dict으로 key 부여
titanic_df.groupby('Pclass').agg(agg_format)
Age SibSp Fare
Pclass
1 80.0 90 84.154687
2 70.0 74 20.662183
3 74.0 302 13.675550
Missing 데이터 처리하기
DataFrame의 isna( ) 메소드는 모든 컬럼값들이 NaN인지 True/False값을 반환함(NaN이면 True)
titanic_df.isna().head(3) # 모든 COL에 T/F 출력
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 False False False False False False False False False False True False
1 False False False False False False False False False False False False
2 False False False False False False False False False False True False
아래와 같이 isna( ) 반환 결과에 sum( )을 호출하여 컬럼별로 NaN 건수를 구할 수 있습니다.
titanic_df.isna( ).sum( ) # NULL의 개수를 계산 VS COUNT와 반대
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
** fillna( ) 로 Missing 데이터를 인자로 대체하기 **
titanic_df['Cabin'] = titanic_df['Cabin'].fillna('C000') #NULL 이면 COOO으로 채워주줘
titanic_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.2500 C000 S
1 2 1 1 Cumings, Mr... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, ... female 26.0 0 0 STON/O2. 31... 7.9250 C000 S
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
titanic_df['Embarked'] = titanic_df['Embarked'].fillna('S')
titanic_df.isna().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
apply lambda // 함수 식으로 데이터 가공
파이썬 lambda 식 기본 // apply 함수에 lambda 결합, df, series에 레코드별 데이터 가공 기능,
보통은 일괄 데이터 가공이 속도면에서 빠르지만, 복잡한데이터 가공시 행별 apply lambda 이용
lambda x(입력 인자) : x**2(입력인자를 기반으로한 계산식이며 호출 시 계산 결과가 반환됨)
titanic_df = pd.read_csv('titanic_train.csv')
print('titanic 변수 type:',type(titanic_df))
# titanic 변수 type: <class 'pandas.core.frame.DataFrame'>
head() DataFrame의 맨 앞 일부 데이터만 추출
titanic_df.head(5)
# col, row 모든 값이 ndarray 2차원이니깐 // index는 차원에 포함 안됨
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
** DataFrame의 생성 **
dic1 = {'Name': ['Chulmin', 'Eunkyung','Jinwoong','Soobeom'],
'Year': [2011, 2016, 2015, 2015],
'Gender': ['Male', 'Female', 'Male', 'Male']
}
# 딕셔너리를 DataFrame으로 변환 // key 값이 col 나머지가 value로들어감
data_df = pd.DataFrame(dic1)
print(data_df)
print("#"*30)
# 새로운 컬럼명을 추가
data_df = pd.DataFrame(dic1, columns=["Name", "Year", "Gender", "Age"])
print(data_df)
print("#"*30)
# 인덱스를 새로운 값으로 할당.
data_df = pd.DataFrame(dic1, index=['one','two','three','four'])
# index 마음 대로 가능 //보통은 arange형인데
print(data_df)
print("#"*30)
Name Year Gender
0 Chulmin 2011 Male
1 Eunkyung 2016 Female
2 Jinwoong 2015 Male
3 Soobeom 2015 Male
##############################
Name Year Gender Age
0 Chulmin 2011 Male NaN
1 Eunkyung 2016 Female NaN
2 Jinwoong 2015 Male NaN
3 Soobeom 2015 Male NaN
##############################
Name Year Gender
one Chulmin 2011 Male
two Eunkyung 2016 Female
three Jinwoong 2015 Male
four Soobeom 2015 Male
##############################
새로운 컬럼에 값을 할당하려면 DataFrame [ ] 내에 새로운 컬럼명을 입력하고 값을 할당해주기만 하면 됨
titanic_df['Age_0']=0 # 추가
titanic_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_0
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 0
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 0
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 0
titanic_df['Age_by_10'] = titanic_df['Age']*10
titanic_df['Family_No'] = titanic_df['SibSp'] + titanic_df['Parch']+1 # 기존 컬럼을 통해 새로 생성
titanic_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_0 Age_by_10 Family_No
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 0 220.0 2
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 0 380.0 2
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 0 260.0 1
기존 컬럼에 값을 업데이트 하려면 해당 컬럼에 업데이트값을 그대로 지정하면 됨
titanic_df['Age_by_10'] = titanic_df['Age_by_10'] + 100
titanic_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_0 Age_by_10 Family_No
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 0 320.0 2
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 0 480.0 2
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 0 360.0 1
DataFrame 데이터 삭제
** axis에 따른 삭제**
titanic_drop_df = titanic_df.drop('Age_0', axis=1 )
titanic_drop_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_by_10 Family_No
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 320.0 2
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 480.0 2
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 360.0 1
drop( )메소드의 inplace인자의 기본값은 False 임
이 경우 drop( )호출을 한 DataFrame은 아무런 영향이 없으며
drop( )호출의 결과가 해당 컬럼이 drop 된 DataFrame을 반환함
titanic_df.head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked Age_0 Age_by_10 Family_No
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 0 320.0 2
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 0 480.0 2
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 0 360.0 1
여러개의 컬럼들의 삭제는 drop의 인자로 삭제 컬럼들을 리스트로 입력함
inplace=True 일 경우 호출을 한 DataFrame에 drop이 반영됨
이 때 반환값은 None임
drop_result = titanic_df.drop(['Age_0', 'Age_by_10', 'Family_No'], axis=1, inplace=True)
print(' inplace=True 로 drop 후 반환된 값:',drop_result)
titanic_df.head(3)
# inplace=True 로 drop 후 반환된 값: None
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
axis=0 일 경우 drop()은 row 방향으로 데이터를 삭제함
titanic_df = pd.read_csv('titanic_train.csv')
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 15)
print('#### before axis 0 drop ####')
print(titanic_df.head(6))
titanic_df.drop([0,1,2], axis=0, inplace=True)
print('#### after axis 0 drop ####')
print(titanic_df.head(3))
#### before axis 0 drop ####
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mr... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, ... female 26.0 0 0 STON/O2. 31... 7.9250 NaN S
3 4 1 1 Futrelle, M... female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. ... male 35.0 0 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. ... male NaN 0 0 330877 8.4583 NaN Q
#### after axis 0 drop ####
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
3 4 1 1 Futrelle, M... female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. ... male 35.0 0 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. ... male NaN 0 0 330877 8.4583 NaN Q
print('Fair Series max 값:', series_fair.max())
print('Fair Series sum 값:', series_fair.sum())
print('sum() Fair Series:', sum(series_fair))
print('Fair Series + 3:\n',(series_fair + 3).head(3) )
# index 로 의미있는값이 나오는 경우가 있음, 그럼 인덱스를 컬럼으로 만들수 없을까? reset index
# Fair Series max 값: 512.3292
# Fair Series sum 값: 28693.9493
# sum() Fair Series: 28693.949299999967
# Fair Series + 3:
# 0 10.2500
# 1 74.2833
# 2 10.9250
# Name: Fare, dtype: float64
DataFrame 및 Series에 reset_index( ) 메서드를 수행하면 새롭게 인덱스를 연속 숫자 형으로 할당하며 기존 인덱스는 ‘index’라는 새로운 컬럼 명으로 추가함
titanic_reset_df = titanic_df.reset_index(inplace=False)
titanic_reset_df.head(3)
index PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.2500 NaN S
1 1 2 1 1 Cumings, Mr... female 38.0 1 0 PC 17599 71.2833 C85 C
2 2 3 1 3 Heikkinen, ... female 26.0 0 0 STON/O2. 31... 7.9250 NaN S
titanic_reset_df.shape
# (891, 13)
print('### before reset_index ###')
value_counts = titanic_df['Pclass'].value_counts() # vc는 series => 고유 칼럼값이 필요한데
print(value_counts)
print('value_counts 객체 변수 타입:',type(value_counts))
new_value_counts = value_counts.reset_index(inplace=False)
print('### After reset_index ###')
print(new_value_counts)
print('new_value_counts 객체 변수 타입:',type(new_value_counts))
### before reset_index ###
# 3 491
# 1 216
# 2 184
# Name: Pclass, dtype: int64
# value_counts 객체 변수 타입: <class 'pandas.core.series.Series'>
### After reset_index ###
# index Pclass
# 0 3 491
# 1 1 216
# 2 2 184
# new_value_counts 객체 변수 타입: <class 'pandas.core.frame.DataFrame'>
데이터 Selection 및 Filtering
DataFrame의 [ ] 연산자
넘파이에서 [ ] 연산자는 행의 위치, 열의 위치, 슬라이싱 범위 등을 지정해 데이터를 가져올 수 있음
하지만 DataFrame 바로 뒤에 있는 ‘[ ]’ 안에 들어갈 수 있는 것은 컬럼 명 문자(또는 컬럼 명의 리스트 객체), 또는 인덱스로 변환 가능한 표현식임
titanic_df = pd.read_csv('titanic_train.csv')
print('단일 컬럼 데이터 추출:\n', titanic_df[ 'Pclass' ].head(3))
print('\n여러 컬럼들의 데이터 추출:\n', titanic_df[ ['Survived', 'Pclass'] ].head(3))
print('[ ] 안에 숫자 index는 KeyError 오류 발생:\n', titanic_df[0]) # 숫자형 x 직접 칼럼명 넣어주는게 좋다
단일 컬럼 데이터 추출:
0 3
1 1
2 3
Name: Pclass, dtype: int64
여러 컬럼들의 데이터 추출:
Survived Pclass
0 0 3
1 1 1
2 1 3
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2894 try:
-> 2895 return self._engine.get_loc(casted_key)
2896 except KeyError as err:
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 0
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
<ipython-input-35-16b79a4adf85> in <module>
2 print('단일 컬럼 데이터 추출:\n', titanic_df[ 'Pclass' ].head(3))
3 print('\n여러 컬럼들의 데이터 추출:\n', titanic_df[ ['Survived', 'Pclass'] ].head(3))
----> 4 print('[ ] 안에 숫자 index는 KeyError 오류 발생:\n', titanic_df[0]) # 숫자형 x 직접 칼럼명 넣어주는게 좋다
~\anaconda3\lib\site-packages\pandas\core\frame.py in __getitem__(self, key)
2900 if self.columns.nlevels > 1:
2901 return self._getitem_multilevel(key)
-> 2902 indexer = self.columns.get_loc(key)
2903 if is_integer(indexer):
2904 indexer = [indexer]
~\anaconda3\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2895 return self._engine.get_loc(casted_key)
2896 except KeyError as err:
-> 2897 raise KeyError(key) from err
2898
2899 if tolerance is not None:
KeyError: 0
앞에서 DataFrame의 [ ] 내에 숫자 값을 입력할 경우 오류가 발생한다고 했는데, Pandas의 Index 형태로 변환가능한 표현식은 [ ] 내에 입력할 수 있음 가령 titanic_df의 처음 2개 데이터를 추출하고자 titanic_df [ 0:2 ] 와 같은 슬라이싱을 이용하였다면 정확히 원하는 결과를 반환해 줌
titanic_df[0:2] #허용은 해주지만 비추
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mr... female 38.0 1 0 PC 17599 71.2833 C85 C
[ ] 내에 조건식을 입력하여 불린 인덱싱을 수행할 수 있음
(DataFrame 바로 뒤에 있는 []안에 들어갈 수 있는 것은 컬럼명과 불린인덱싱으로 범위를 좁혀서 코딩을 하는게 도움이 됨)
titanic_df[ titanic_df['Pclass'] == 3].head(3)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr.... male 22.0 1 0 A/5 21171 7.250 NaN S
2 3 1 3 Heikkinen, ... female 26.0 0 0 STON/O2. 31... 7.925 NaN S
4 5 0 3 Allen, Mr. ... male 35.0 0 0 373450 8.050 NaN S
* DataFrame iloc[ ] 연산자** 위치기반 인덱싱을 제공함
data_df.head()
Name Year Gender
one Chulmin 2011 Male
two Eunkyung 2016 Female
three Jinwoong 2015 Male
four Soobeom 2015 Male
data_df.iloc[0, 0]
# 'Chulmin'
# 아래 코드는 오류를 발생함
data_df.iloc[0, 'Name']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _has_valid_tuple(self, key)
701 try:
--> 702 self._validate_key(k, i)
703 except ValueError as err:
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _validate_key(self, key, axis)
1368 else:
-> 1369 raise ValueError(f"Can only index by location with a [{self._valid_types}]")
1370
ValueError: Can only index by location with a [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array]
The above exception was the direct cause of the following exception:
ValueError Traceback (most recent call last)
<ipython-input-60-ab5240d8ed9d> in <module>
1 # 아래 코드는 오류를 발생합니다.
----> 2 data_df.iloc[0, 'Name']
~\anaconda3\lib\site-packages\pandas\core\indexing.py in __getitem__(self, key)
871 # AttributeError for IntervalTree get_value
872 pass
--> 873 return self._getitem_tuple(key)
874 else:
875 # we by definition only have the 0th axis
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _getitem_tuple(self, tup)
1441 def _getitem_tuple(self, tup: Tuple):
1442
-> 1443 self._has_valid_tuple(tup)
1444 try:
1445 return self._getitem_lowerdim(tup)
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _has_valid_tuple(self, key)
702 self._validate_key(k, i)
703 except ValueError as err:
--> 704 raise ValueError(
705 "Location based indexing can only have "
706 f"[{self._valid_types}] types"
ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] types
# 아래 코드는 오류를 발생합니다.
data_df.iloc['one', 0]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _has_valid_tuple(self, key)
701 try:
--> 702 self._validate_key(k, i)
703 except ValueError as err:
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _validate_key(self, key, axis)
1368 else:
-> 1369 raise ValueError(f"Can only index by location with a [{self._valid_types}]")
1370
ValueError: Can only index by location with a [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array]
The above exception was the direct cause of the following exception:
ValueError Traceback (most recent call last)
<ipython-input-61-0fe0a94ee06c> in <module>
1 # 아래 코드는 오류를 발생합니다.
----> 2 data_df.iloc['one', 0]
~\anaconda3\lib\site-packages\pandas\core\indexing.py in __getitem__(self, key)
871 # AttributeError for IntervalTree get_value
872 pass
--> 873 return self._getitem_tuple(key)
874 else:
875 # we by definition only have the 0th axis
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _getitem_tuple(self, tup)
1441 def _getitem_tuple(self, tup: Tuple):
1442
-> 1443 self._has_valid_tuple(tup)
1444 try:
1445 return self._getitem_lowerdim(tup)
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _has_valid_tuple(self, key)
702 self._validate_key(k, i)
703 except ValueError as err:
--> 704 raise ValueError(
705 "Location based indexing can only have "
706 f"[{self._valid_types}] types"
ValueError: Location based indexing can only have [integer, integer slice (START point is INCLUDED, END point is EXCLUDED), listlike of integers, boolean array] types
data_df_reset.head()
old_index Name Year Gender
1 one Chulmin 2011 Male
2 two Eunkyung 2016 Female
3 three Jinwoong 2015 Male
4 four Soobeom 2015 Male
data_df_reset.iloc[0, 1]
# 'Chulmin'
DataFrame loc[ ] 연산자 명칭기반 인덱싱을 제공함
data_df
Name Year Gender
one Chulmin 2011 Male
two Eunkyung 2016 Female
three Jinwoong 2015 Male
four Soobeom 2015 Male
# 아래 코드는 오류를 발생합니다. (단, 0없음)
data_df_reset.loc[0, 'Name']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\anaconda3\lib\site-packages\pandas\core\indexes\range.py in get_loc(self, key, method, tolerance)
354 try:
--> 355 return self._range.index(new_key)
356 except ValueError as err:
ValueError: 0 is not in range
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
<ipython-input-67-d3c58a57c329> in <module>
1 # 아래 코드는 오류를 발생합니다. (단, 0없음)
----> 2 data_df_reset.loc[0, 'Name']
~\anaconda3\lib\site-packages\pandas\core\indexing.py in __getitem__(self, key)
871 # AttributeError for IntervalTree get_value
872 pass
--> 873 return self._getitem_tuple(key)
874 else:
875 # we by definition only have the 0th axis
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _getitem_tuple(self, tup)
1042 def _getitem_tuple(self, tup: Tuple):
1043 try:
-> 1044 return self._getitem_lowerdim(tup)
1045 except IndexingError:
1046 pass
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _getitem_lowerdim(self, tup)
784 # We don't need to check for tuples here because those are
785 # caught by the _is_nested_tuple_indexer check above.
--> 786 section = self._getitem_axis(key, axis=i)
787
788 # We should never have a scalar section here, because
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _getitem_axis(self, key, axis)
1108 # fall thru to straight lookup
1109 self._validate_key(key, axis)
-> 1110 return self._get_label(key, axis=axis)
1111
1112 def _get_slice_axis(self, slice_obj: slice, axis: int):
~\anaconda3\lib\site-packages\pandas\core\indexing.py in _get_label(self, label, axis)
1057 def _get_label(self, label, axis: int):
1058 # GH#5667 this will fail if the label is not present in the axis.
-> 1059 return self.obj.xs(label, axis=axis)
1060
1061 def _handle_lowerdim_multi_index_axis0(self, tup: Tuple):
~\anaconda3\lib\site-packages\pandas\core\generic.py in xs(self, key, axis, level, drop_level)
3489 loc, new_index = self.index.get_loc_level(key, drop_level=drop_level)
3490 else:
-> 3491 loc = self.index.get_loc(key)
3492
3493 if isinstance(loc, np.ndarray):
~\anaconda3\lib\site-packages\pandas\core\indexes\range.py in get_loc(self, key, method, tolerance)
355 return self._range.index(new_key)
356 except ValueError as err:
--> 357 raise KeyError(key) from err
358 raise KeyError(key)
359 return super().get_loc(key, method=method, tolerance=tolerance)
KeyError: 0
print('위치기반 iloc slicing\n', data_df.iloc[0:1, 0],'\n')
print('명칭기반 loc slicing\n', data_df.loc['one':'two', 'Name'])
# 위치기반 iloc slicing
# one Chulmin
# Name: Name, dtype: object
# 명칭기반 loc slicing
# one Chulmin
# two Eunkyung
# Name: Name, dtype: object
헷갈리는 위치기반, 명칭기반 인덱싱을 사용할 필요없이 조건식을 [ ] 안에 기입하여 간편하게 필터링을 수행.
titanic_df = pd.read_csv('titanic_train.csv')
titanic_boolean = titanic_df[titanic_df['Age'] > 60] # 불리언[ 불리언[] 연산자]
print(type(titanic_boolean))
titanic_boolean
# <class 'pandas.core.frame.DataFrame'>
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
33 34 0 2 Wheadon, Mr... male 66.0 0 0 C.A. 24579 10.5000 NaN S
54 55 0 1 Ostby, Mr. ... male 65.0 0 1 113509 61.9792 B30 C
96 97 0 1 Goldschmidt... male 71.0 0 0 PC 17754 34.6542 A5 C
116 117 0 3 Connors, Mr... male 70.5 0 0 370369 7.7500 NaN Q
170 171 0 1 Van der hoe... male 61.0 0 0 111240 33.5000 B19 S
252 253 0 1 Stead, Mr. ... male 62.0 0 0 113514 26.5500 C87 S
275 276 1 1 Andrews, Mi... female 63.0 1 0 13502 77.9583 D7 S
280 281 0 3 Duane, Mr. ... male 65.0 0 0 336439 7.7500 NaN Q
326 327 0 3 Nysveen, Mr... male 61.0 0 0 345364 6.2375 NaN S
438 439 0 1 Fortune, Mr... male 64.0 1 4 19950 263.0000 C23 C25 C27 S
456 457 0 1 Millet, Mr.... male 65.0 0 0 13509 26.5500 E38 S
483 484 1 3 Turkula, Mr... female 63.0 0 0 4134 9.5875 NaN S
493 494 0 1 Artagaveyti... male 71.0 0 0 PC 17609 49.5042 NaN C
545 546 0 1 Nicholson, ... male 64.0 0 0 693 26.0000 NaN S
555 556 0 1 Wright, Mr.... male 62.0 0 0 113807 26.5500 NaN S
570 571 1 2 Harris, Mr.... male 62.0 0 0 S.W./PP 752 10.5000 NaN S
625 626 0 1 Sutton, Mr.... male 61.0 0 0 36963 32.3208 D50 S
630 631 1 1 Barkworth, ... male 80.0 0 0 27042 30.0000 A23 S
672 673 0 2 Mitchell, M... male 70.0 0 0 C.A. 24580 10.5000 NaN S
745 746 0 1 Crosby, Cap... male 70.0 1 1 WE/P 5735 71.0000 B22 S
829 830 1 1 Stone, Mrs.... female 62.0 0 0 113572 80.0000 B28 NaN
851 852 0 3 Svensson, M... male 74.0 0 0 347060 7.7750 NaN S
titanic_df['Age'] > 60
var1 = titanic_df['Age'] > 60 # []없이 하면 series 형태로 나옴 vs dataframe
print(type(var1))
# <class 'pandas.core.series.Series'>
titanic_df[titanic_df['Age'] > 60][['Name','Age']].head(3) #age > 60 인 data중에 name, age col로 3개 // SQL 느낌
Name Age
33 Wheadon, Mr... 66.0
54 Ostby, Mr. ... 65.0
96 Goldschmidt... 71.0
titanic_df[['Name','Age']][titanic_df['Age'] > 60].head(3) # 거꾸로해도 가능 : 유연성
Name Age
33 Wheadon, Mr... 66.0
54 Ostby, Mr. ... 65.0
96 Goldschmidt... 71.0
titanic_df.loc[titanic_df['Age'] > 60, ['Name','Age']].head(3) # loc 만으로 불린연산
Name Age
33 Wheadon, Mr... 66.0
54 Ostby, Mr. ... 65.0
96 Goldschmidt... 71.0
논리 연산자로 결합된 조건식도 불린 인덱싱으로 적용 가능함
titanic_df[ (titanic_df['Age'] > 60) & (titanic_df['Pclass']==1) & (titanic_df['Sex']=='female')] #논리연산자사용
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
275 276 1 1 Andrews, Mi... female 63.0 1 0 13502 77.9583 D7 S
829 830 1 1 Stone, Mrs.... female 62.0 0 0 113572 80.0000 B28 NaN
조건식은 변수로도 할당 가능함
복잡한 조건식은 변수로 할당하여 가득성을 향상 할 수 있음
cond1 = titanic_df['Age'] > 60
cond2 = titanic_df['Pclass']==1
cond3 = titanic_df['Sex']=='female'
titanic_df[ cond1 & cond2 & cond3] # 가독성을 위해 각각 - 효과적으로 사용
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
275 276 1 1 Andrews, Mi... female 63.0 1 0 13502 77.9583 D7 S
829 830 1 1 Stone, Mrs.... female 62.0 0 0 113572 80.0000 B28 NaN
array1.reshape(4,3)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-2ff703983fd4> in <module>
1 # 변환할 수 없는 shape구조를 입력하면 오류 발생.
----> 2 array1.reshape(4,3)
NameError: name 'array1' is not defined
# reshape()에 -1 인자값을 부여하여 특정 차원으로 고정된 가변적인 ndarray형태 변환
array1 = np.arange(10)
print(array1)
# -1은 나머지 ROW || COLUMN 을 기준으로 설정하겠다는 마인드
#컬럼 axis 크기는 5에 고정하고 로우 axis크기를 이에 맞춰 자동으로 변환. 즉 2x5 형태로 변환
array2 = array1.reshape(-1,5)
print('array2 shape:',array2.shape)
print('array2:\n', array2)
#로우 axis 크기는 5로 고정하고 컬럼 axis크기는 이에 맞춰 자동으로 변환. 즉 5x2 형태로 변환
array3 = array1.reshape(5,-1)
print('array3 shape:',array3.shape)
print('array3:\n', array3)
# [0 1 2 3 4 5 6 7 8 9]
# array2 shape: (2, 5)
# array2:
# [[0 1 2 3 4]
# [5 6 7 8 9]]
# array3 shape: (5, 2)
# array3:
# [[0 1]
# [2 3]
# [4 5]
# [6 7]
# [8 9]]
# reshape()는 (-1, 1), (-1,)와 같은 형태로 주로 사용됨. // 이러면 1차원으로 만들어버림 # 1차원 ndarray를 2차원으로 또는 2차원 ndarray를 1차원으로 변환 시 사용.
array1 = np.arange(10)
array4 = array1.reshape(-1,4)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-23-a27748faa610> in <module>
1 # -1 을 적용하여도 변환이 불가능한 형태로의 변환을 요구할 경우 오류 발생.
2 array1 = np.arange(10)
----> 3 array4 = array1.reshape(-1,4)
ValueError: cannot reshape array of size 10 into shape (4)
# 반드시 -1 값은 1개의 인자만 입력해야 함. 모두가 불확정이 되어버림
array1.reshape(-1, -1)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-24-da23572df4ae> in <module>
1 # 반드시 -1 값은 1개의 인자만 입력해야 함.
----> 2 array1.reshape(-1, -1)
ValueError: can only specify one unknown dimension
ndarray의 데이터 세트 선택하기 – 인덱싱(Indexing)
특정 위치의 단일값 추출
# 1에서 부터 9 까지의 1차원 ndarray 생성
array1 = np.arange(start=1, stop=10)
print('array1:',array1)
# index는 0 부터 시작하므로 array1[2]는 3번째 index 위치의 데이터 값을 의미
value = array1[2]
print('value:',value)
print(type(value))
# array1: [1 2 3 4 5 6 7 8 9]
# value: 3
# <class 'numpy.int32'>
print('맨 뒤의 값:',array1[-1], ', 맨 뒤에서 두번째 값:',array1[-2])
# 맨 뒤의 값: 9 , 맨 뒤에서 두번째 값: 8
array1d = np.arange(start=1, stop=10)
array2d = array1d.reshape(3,3)
print(array2d)
print('(row=0,col=0) index 가리키는 값:', array2d[0,0] )
print('(row=0,col=1) index 가리키는 값:', array2d[0,1] )
print('(row=1,col=0) index 가리키는 값:', array2d[1,0] )
print('(row=2,col=2) index 가리키는 값:', array2d[2,2] )
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
# (row=0,col=0) index 가리키는 값: 1
# (row=0,col=1) index 가리키는 값: 2
# (row=1,col=0) index 가리키는 값: 4
# (row=2,col=2) index 가리키는 값: 9
def word_tokenization(text) :
stop_words = ['는','을','를','이','가','의','던','고','하','다','은','에','들','지','게','도']
return [word for word in okt.morphs(text) if word not in stop_words]
def word_tokenization(text) :
# 한글 불용어
stop_words = ['는','을','를','이','가','의','던','고','하','다','은','에','들','지','게','도']
return [word for word in okt.morphs(text) if word not in stop_words]
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence
import pad_sequences
tokenizer = Tokenizer() tokenizer.fit_on_texts(data)
print("총 단어 갯수:", len(tokenizer.word_index))
# 총 단어 갯수: 122402
5회 이상만 vocab_size 에 포함
def get_vocab_size(threshold) :
cnt = 0
for x in tokenizer.word_counts.values() :
if x >=threshold :
cnt += 1
return cnt
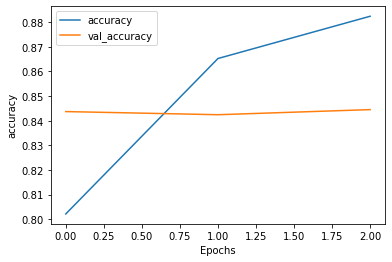
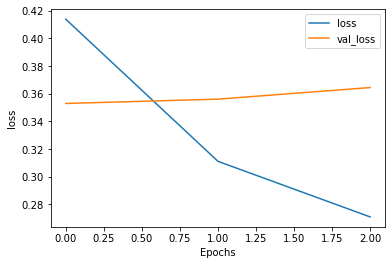
딥러닝 모델의 구조가 복잡하고, 데이터 크기가 클수록 학습시간이 오래걸림. => 오랜시간 학습한 모델을 저장할 필요가 있음. modelcheckpoint 함수 이용 save_weights_only=True : weight 만저장 save_weights_only=False : 모델 레이터와 weight 모두 저장 save_best_only = True : 좋은 가중치만 저장 save_best_only = False : 모든 가중치 저장