import pandas as pd
url = "http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/"
red = pd.read_csv(url+'winequality-red.csv',sep=';')
white = pd.read_csv(url+'winequality-white.csv',sep=';')
# 임의의 데이터를 이미지로 출력
import matplotlib.pyplot as plt
import numpy as np
sample_size = 9
# 난수 생성 0 ~ 59999 중 9개
random_idx = np.random.randint(60000, size = sample_size)
plt.figure(figsize = (5, 5))
for i, idx in enumerate(random_idx) :
plt.subplot(3,3, i + 1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[idx], cmap = 'gray')
plt.xlabel(class_names[y_train[idx]])
plt.show()
# 학습데이터 테스트 데이터 정규화 0~1
x_train[:10]
x_train = x_train / 255
x_test = x_test / 255
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(x_train, y_train, test_size=0.3, random_state = 777)
print('훈련데이터 :',X_train.shape,', 레이블 :',Y_train.shape)
print('검증데이터 :',X_val.shape,', 레이블 :',Y_val.shape)
# 훈련데이터 : (42000, 28, 28) , 레이블 : (42000, 10)
# 검증데이터 : (18000, 28, 28) , 레이블 : (18000, 10)
# mnist : 숫자학습 인식
from tensorflow.keras.datasets.mnist import load_data
(x_train, y_train),(x_test, y_test) = load_data(path='mnist.npz')
# 데이터 형태
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
import matplotlib.pyplot as plt
import numpy as np
random_idx = np.random.randint(60000, size = 3)
for idx in random_idx :
img = x_train[idx, :]
label = y_train[idx]
plt.figure()
plt.imshow(img) # 이미지출력
plt.title('%d-th data, label is %d'%(idx,label), fontsize=15)
# 검증데이터
from sklearn.model_selection import train_test_split
X_train, X_val, Y_train, Y_val = train_test_split(x_train, y_train, test_size=0.3, random_state = 777)
print('훈련데이터 :',X_train.shape,', 레이블 :',Y_train.shape)
print('검증데이터 :',X_val.shape,', 레이블 :',Y_val.shape)
훈련데이터 : (42000, 28, 28) , 레이블 : (42000,)
검증데이터 : (18000, 28, 28) , 레이블 : (18000,)
# 활성화 함수 결정 : SOFTMAX => 다중분류시 사용
x = np.arange(-5.0, 5.0, 0.1)
y = np.exp(x) / np.sum(np.exp(x))
# 지수함수 x 를 합계로 나눈다
plt.plot(x, y)
plt.title("softmax Function")
plt.show()
# 절대 1이 넘지 않음
# 결과값의 합이 1
# 학습 결과 확인
# loss, acc, val_loss, val_acc를 그래프로 출력
# 훈련 및 검증데이터의 손실값을 그래프로 출력
import matplotlib.pyplot as plt
his_dict = history.history # dict : loss학습손실값 acc학습정확도 // val_ 검증
loss = his_dict['loss'] # 학습데이터의 손실함수값
val_loss = his_dict['val_loss'] # 검증데이터의 손실함수값
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize = (10, 5))
# 훈련 및 검증 손실 그리기
ax1 = fig.add_subplot(1,2,1)
ax1.plot(epochs, loss, color = 'blue', label = 'train_loss')
ax1.plot(epochs, val_loss, color = 'orange', label = 'val_loss')
ax1.set_title('train and val loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
acc = his_dict['acc'] # 정확도
val_acc = his_dict['val_acc'] # 검증데이터의 정확도
# 훈련 및 검증 손실 그리기
ax2 = fig.add_subplot(1,2,2)
ax2.plot(epochs, acc, color = 'blue', label = 'train_acc')
ax2.plot(epochs, val_acc, color = 'orange', label = 'val_acc')
ax2.set_title('train and val acc')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
plt.show()
# 모델평가 : 평가데이터로 평가
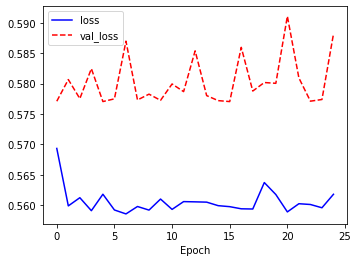
# 현재 특징 : 학습데이터 성능 좋다. 단, 검증데이터, 테스트데이터는 성능이 학습데이터 성능보다 낮다.
# => 과대적합 => 그래프를 보니 5번에서 갈라짐 => 5번 만 하고 확인해야한다.
# => epochs 줄이기나, random_state 조절, test_data 조절
model.evaluate(x_test, y_test) #
# [0.12191680818796158, 0.9718999862670898] # 검증데이터랑 비슷하게 나옴
313/313 [==============================] - 0s 1ms/step - loss: 0.1437 - acc: 0.9696
[0.14366137981414795, 0.9696000218391418]
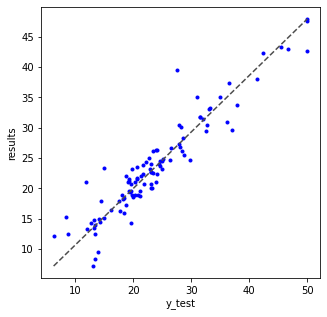
# 예측값 확인
np.set_printoptions(precision=7)
results = model.predict(x_test) # 예측값
import matplotlib.pyplot as plt
# argmax = results 데이터 중 가장 큰 값 가지는 인덱스 저장
arg_results = np.argmax(results, axis = -1)
idx = 6
plt.imshow(x_test[idx].reshape(28, 28))
plt.title('predicted value of the first image : '+str(arg_results[idx]), fontsize=15)
plt.show()
기존 and x1 | x2 | y 0 | 0 | 0 0 | 1 | 0 1 | 0 | 0 1 | 1 | 1 b + x1*w1 + ... = y b 편향 b 보다 작으면 0, 크면 1 이라고 하면 and 알고리즘을 알수있다 x1, x2 입력값 w1, w2 가중치 y = 0 : if x1w1 + x2w2 <=b y = 1 : if x1w1 + x2w2 > b
# and게이트
import numpy as np
def AND (x1, x2) :
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.5 # -0.8이되어도 영향 별로 없음
tmp = np.sum(w*x) + b
if tmp <= 0 :
return 0
else :
return 1
# 퍼셉트론 알고리즘
for xs in [(0,0),(1,0),(0,1),(1,1)] :
y = AND(xs[0], xs[1])
print(str(xs) + "=>" + str(y))
# 가중치와 편향을 찾아가는 방법
# 모든것의 최적의 가중치와 편향을 찾음
(0, 0)=>0
(1, 0)=>0
(0, 1)=>0
(1, 1)=>1
# OR게이트
import numpy as np
def OR (x1, x2) :
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.2 # -0.8이되어도 영향 별로 없음
tmp = np.sum(w*x) + b
if tmp <= 0 :
return 0
else :
return 1
# 퍼셉트론 알고리즘
for xs in [(0,0),(1,0),(0,1),(1,1)] :
y = OR(xs[0], xs[1])
print(str(xs) + "=>" + str(y))
# -0.2로 바뀌었을 뿐 => 이걸로 조합이 OR이 ㅣㅗㄷㅁ
(0, 0)=>0
(1, 0)=>1
(0, 1)=>1
(1, 1)=>1
# nand게이트
import numpy as np
def NAND (x1, x2) :
x = np.array([x1, x2])
w = np.array([-0.5, -0.5])
b = 0.8 # -0.8이되어도 영향 별로 없음
tmp = np.sum(w*x) + b
if tmp <= 0 :
return 0
else :
return 1
# 퍼셉트론 알고리즘
for xs in [(0,0),(1,0),(0,1),(1,1)] :
y = NAND(xs[0], xs[1])
print(str(xs) + "=>" + str(y))
(0, 0)=>1
(1, 0)=>1
(0, 1)=>1
(1, 1)=>0
# XOR게이트
다중 신경망
import numpy as np
def XOR (x1, x2) :
s1 = NAND(x1, x2)
s2 = OR(x1, x2)
y = AND(s1, s2) # 2층 구조
return y
# 퍼셉트론 알고리즘
for xs in [(0,0),(1,0),(0,1),(1,1)] :
y = XOR(xs[0], xs[1])
print(str(xs) + "=>" + str(y))
(0, 0)=>1
(1, 0)=>0
(0, 1)=>0
(1, 1)=>1
# 같으면 1 다르면 0 # 10 # 선형 표현불가 # 01 x1을 다중 퍼셉트론
# 활성화 함수 : 비선형데이터로 변환
# 계단 함수 : 0, 1로 리턴
import matplotlib.pyplot as plt
def step_function (x):
return np.array(x > 0,dtype = np.int)
# 0보다 크면 실수 출력
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
# 시그모이드함수 0 ~ 1.0
def sigmoid(x) :
return 1 / (1 + np.exp(-x)) # 분류
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x,y)
plt.ylim(-0.1, 1.1)
plt.show()
# ReLU : 0 ~ 이상의 값
def relu(x) :
return np.maximum(0,x) # 회귀분석에서
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.show()
# cost function (loss functin) # 어떻게 최적의 값으로 접근하지? # 미분값이 최소
batch gd
stochastic
mini batch gc
# 오차역전파 수식을 통해 알고리즘을 통해 정답과 예측을 손실함수로 비교하고 다시 구함 =>
import numpy as np
import tensorflow as tf
print(tf.__version__)
2.4.1