728x90
반응형
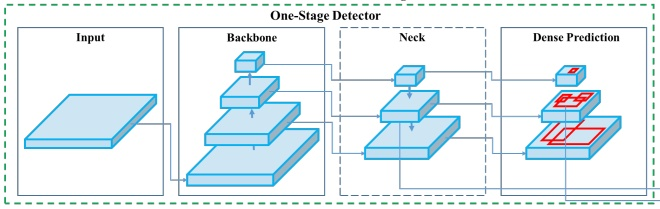
- Feature Extractor Network
VGG, RESNET, INCEPTION 등
보통 imageNet dataset 기반으로 pretrained 됨
img classification model 은 원본 img보다는 size가 적지만 상대적으로는 큰 feature map이 만들어지고,
size는 점점 줄어들지만 channel(depth)의 수는 늘어남, feature map이 작아질수록 핵심적인 feature로만 추상화됨
- object detection network
pascal VOC / MS-COCO
Dataset 기반으로 pretrained 됨
별도의 network로 구성됨
scale 맞누는 것이나 bounding box 맞추는 것이나, classification을 하는 것
그래서 fully connected 여부나 bounding box regression를 어떻게 할건지를 조절
multiscale, feature pyramid 등 고려
# image Resolution, FPS, Detection 성능 상관 관계
높은 image Resolution => 높은 detection 성능 => 낮은 FPS
배열이 크기 때문에 제한된 성능으로 오랜기간 탐색
mAP <> 1/ FPS
FPS가 빨라야 하는 요구사항 => 낮은 Detection 성능
=> 상황에 맞게 조절해야 한다.
빠른 속도를 요구하면 precision과 fps로
맞추는게 중요하면 recall과 성능으로
반응형
'Computer_Science > Computer Vision Guide' 카테고리의 다른 글
| 3-2. RCNN Training과 Loss (0) | 2021.09.24 |
|---|---|
| 3-1. RCNN - region proposal 기반 OD (0) | 2021.09.24 |
| 2-6. OpenCV 영상처리 (0) | 2021.09.23 |
| 2-4~5. OpenCV 개요 (0) | 2021.09.21 |
| 2-3. MS-COCO DATASETS (0) | 2021.09.21 |