Convolutional Neural Network
합성곱 신경망


Conv2D
- feature를 뽑아내는 3x3 filter
- filter 개수는 32개
- neural network에서 perceptron이 32개있는 것과 유사하다
- 3x3 filter는 처음에 랜덤하게 숫자가 정해진다
- linear연산이기 때문에 다양한 조합을 만들수가 없다
- Hyperparameter: filter 개수, filter 모양, padding, strides
- 3차원 연산

Activation
- ReLU - 0보다 작은 값은 0으로 0보다 큰 값은 값 그대로 출력한다
- non-linear한 함수를 활용하여 다양한 조합을 만든다

Conv2D
- filter를 다시 한번 더 통과 시킨다
- 원본 데이터에서 filter를 적용하면서 특징을 배워간다
- 가장 특징이 잘 나타내도록 변화 하는 작업을 수행한다

Activation
- filter 하나당 9개 weight를 갖고 총 32개 filter가 있기 때문에 총 288개 weight가 생긴다

MaxPooling2D
- 계산 복잡도를 줄이기 위해서 Maxpooling을 사용하여 크기를 줄인다
- 숫자 데이터에 대한 서로 다른 32가지 관점으로 해석을 한 후 데이터를 만들어 낸다

Dropout
- dropout을 사용하게 되면 좀 더 의미 있는 특징을 추출하게 된다
- 노드들을 무작위로 생략시키면서 학습을 하게되면 parameter들의 co-adaptation되는 것을 막을 수 있다
※ co-adaptation : 학습하는 도중 같은 층에서 두 개 이상의 노드의 입력 및 연결강도가 같아지게 되면,
아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생기는 문제

Flatten
- 특징이 잘 나타나도록 변경된 데이터 셋을 학습시키기 위해 1차원 데이터로 변환한다

최종적으로 0-9까지의 특징을 가장 잘 파악할 수 있는 32가지 filter를 학습하게 된다

CNN의 문제점 중 하나는 사람의 얼굴 특징이 모두 있지만 분리되어 있는 사진인 경우에도 얼굴이라고 인식하는 오류를 범한다
3차원 연산
CNN은 color이미지 일때 R,G,B 체널로 분리시켜 3차원 연산을 한다
CNN에서는 흑백 이미지일때에도 차원을 증가시켜 3차원 연산을 한다 (채널 데이터를 갖고 있어야 한다)
CNN에서 이미지를 변화시키는 이유는 구분시키는 특징을 잘 파악하는 데이터로 변화시키기 위해서 이다
서로 분리된 채널에 의한 이미지들은 element wise 연산을 통해 하나의 데이터에 대한 특징을 파악할 수 있다

Reference
!pip install mglearn초기값의 중요성
import mglearn
# dtype이 uint8일 때 최대값은 255, 최소값은 0
# MinMaxScaler로 정규화 할 경우 0과 1사이로 값이 바뀌기 때문에 정사각형 형태로 데이터가 분포한다
# 따라서 방향에 대한 크기변화가 없기 때문에 빠른 학습속도와 정확한 학습결과를 기대할 수 있다
mglearn.plot_scaling.plot_scaling()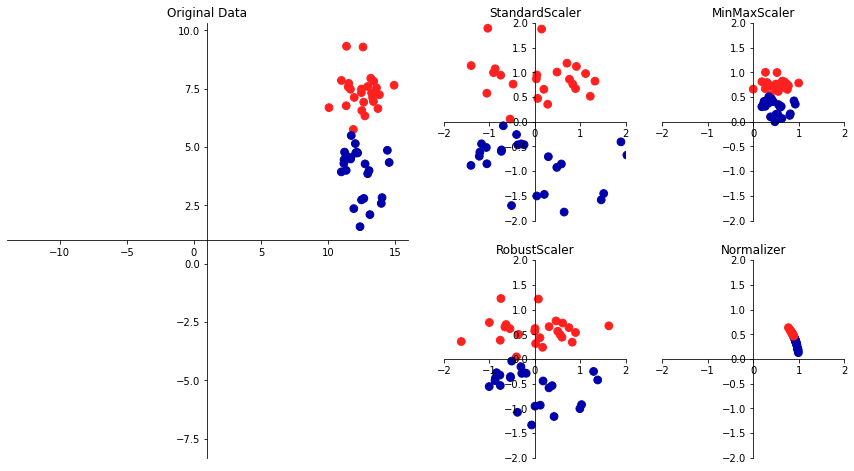
왜 convolution 연산에 대해서 합을 할까?
convolution 연산을 할때 element wise 연산을 하게되면(분리된 채널에서 합쳐질 때)특성을 알 수 없을 수도 있다
물론 depth wise convolution은 각각의 특성만 독립적으로 연산하는 경우도 있다
그러나 더하는 것이 성능이 더 좋고, convolution 연산 결과가 원본 이미지의 의미가 변하는 경우는 거의 나오지 않는다
왜 그런 경우가 나오지 않을까?
weight와 bias는 학습을 통해서 찾기 때문에 채널별로 서로 다른 결과가 나올수 있도록 학습이 되기 때문이다
(kernel은 특성을 잘 파악하도록 학습이 된다)
합하는 것이 왜 좋을까?
전통적인 NN에 영향을 받아서 hierarchy한 것을 고려했기 때문에 hierarchy 특징을 학습할 수 있다
중간 결과 및 filter 이미지 확인하기
import tensorflow as tf
import numpy as np
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
data = load_digits()
data.data[0]
array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13., 15., 10.,
15., 5., 0., 0., 3., 15., 2., 0., 11., 8., 0., 0., 4.,
12., 0., 0., 8., 8., 0., 0., 5., 8., 0., 0., 9., 8.,
0., 0., 4., 11., 0., 1., 12., 7., 0., 0., 2., 14., 5.,
10., 12., 0., 0., 0., 0., 6., 13., 10., 0., 0., 0.])
data.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])plt.imshow(data.images[0], cmap='gray')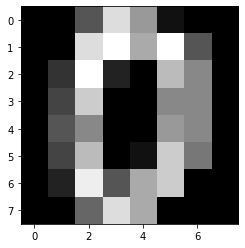
data.images.shape
# (1797, 8, 8)image = data.images.reshape(1797,8,8,1) # CNN에서 사용하는 연산하기 위해서 데이터 하나가 3차원이 되도록 데이터를 변화 시켰다
layer1 = tf.keras.layers.Conv2D(2, (3,3)) # filter 개수, filter 모양(단축 표현 가능 (3,3)=>3)
layer1.built # 일시키기 전까지 초기화가 안된다 => lazy Evaluation / 내부적으로 im2col
# Falselayer1(image[0]) # 동시에 여러개 연산하기 때문에 안된다 / 데이터를 하나 연산하더라도 4차원 형태로 만들어 줘야 한다
# ValueError: Input 0 of layer conv2d_1 is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: (8, 8, 1)layer1(image[0][tf.newaxis])
<tf.Tensor: shape=(1, 6, 6, 2), dtype=float32, numpy=
array([[[[-10.622592 , 0.6645769 ],
...
[ -3.2092843 , -0.36533844]]]], dtype=float32)>layer1.weights # weight를 xavier glorot uniform방식으로 초기화 하고 연산을 한다
# [<tf.Variable 'conv2d_1/kernel:0' shape=(3, 3, 1, 2) dtype=float32, numpy=
# array([[[[ 0.06324342, 0.15853754]],
# [[-0.14388585, -0.19692683]],
# [[-0.40798104, 0.04143384]]],
# [[[-0.24675035, -0.07410842]],
# [[-0.3730538 , 0.22583339]],
# [[-0.22161803, 0.13686094]]],
# [[[ 0.11666891, 0.40331647]],
# [[-0.17990309, 0.3350769 ]],
# [[-0.34412956, -0.15513435]]]], dtype=float32)>,
# <tf.Variable 'conv2d_1/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>]len(layer1.weights)
# 2
layer1.weights[0] # filter / kernel은 (3,3,1)가 2개 있다로 해석해야 한다
# <tf.Variable 'conv2d_1/kernel:0' shape=(3, 3, 1, 2) dtype=float32, numpy=
# array([[[[ 0.06324342, 0.15853754]],
# [[-0.14388585, -0.19692683]],
# [[-0.40798104, 0.04143384]]],
# [[[-0.24675035, -0.07410842]],
# [[-0.3730538 , 0.22583339]],
# [[-0.22161803, 0.13686094]]],
# [[[ 0.11666891, 0.40331647]],
# [[-0.17990309, 0.3350769 ]],
# [[-0.34412956, -0.15513435]]]], dtype=float32)>layer1.weights[0][...,0] # 첫번째 filter
<tf.Tensor: shape=(3, 3, 1), dtype=float32, numpy=
array([[[ 0.06324342],
[-0.14388585],
[-0.40798104]],
[[-0.24675035],
[-0.3730538 ],
[-0.22161803]],
[[ 0.11666891],
[-0.17990309],
[-0.34412956]]], dtype=float32)>
layer1.weights[0][...,1] # 두번째 filter
<tf.Tensor: shape=(3, 3, 1), dtype=float32, numpy=
array([[[ 0.15853754],
[-0.19692683],
[ 0.04143384]],
[[-0.07410842],
[ 0.22583339],
[ 0.13686094]],
[[ 0.40331647],
[ 0.3350769 ],
[-0.15513435]]], dtype=float32)>
np.squeeze(layer1.weights[0][...,1])
array([[ 0.15853754, -0.19692683, 0.04143384],
[-0.07410842, 0.22583339, 0.13686094],
[ 0.40331647, 0.3350769 , -0.15513435]], dtype=float32)
tf.reshape((np.squeeze(layer1.weights[0][...,1])),(3,3))
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[ 0.15853754, -0.19692683, 0.04143384],
[-0.07410842, 0.22583339, 0.13686094],
[ 0.40331647, 0.3350769 , -0.15513435]], dtype=float32)>plt.imshow(np.squeeze(layer1.weights[0][...,1]), cmap='gray')
plt.imshow(np.squeeze(layer1.weights[0][...,0]), cmap='gray')
layer1.weights[1] # bias
# <tf.Variable 'conv2d_1/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>
layer1_result = layer1(image[0][tf.newaxis])
layer1_result.shape
# TensorShape([1, 6, 6, 2])
layer1_result[0,...,0]
# <tf.Tensor: shape=(6, 6), dtype=float32, numpy=
array([[-10.622592 , -17.233952 , -14.855642 , -15.18894 , -13.4780655,
-5.6591477],
[-14.596352 , -16.461687 , -8.46327 , -12.294258 , -13.634556 ,
-5.975335 ],
[-14.3555565, -9.104046 , -1.3667734, -9.231415 , -13.976131 ,
-5.8030467],
[-13.614567 , -7.204097 , -0.2758534, -9.567868 , -13.996439 ,
-5.7096176],
[-13.090911 , -9.931416 , -5.137371 , -12.04954 , -11.825691 ,
-4.75425 ],
[-10.976872 , -13.707218 , -12.3282795, -12.9457 , -10.296714 ,
-3.2092843]], dtype=float32)>
plt.imshow(layer1_result[0,...,0], cmap='gray') # 8x8 이미지에서 3x3 filter를 썻기 때문에 8-3+1 = 6 => 6x6 결과가 나온다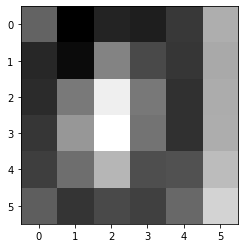
Convolution layer를 통과한 데이터
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.reshape(-1,28,28,1)
input_ = tf.keras.Input(shape=(28,28,1))
x = tf.keras.layers.Conv2D(10,3)(input_)
model = tf.keras.models.Model(input_,x)
plt.imshow(model(X_train)[0][...,0], cmap='gray')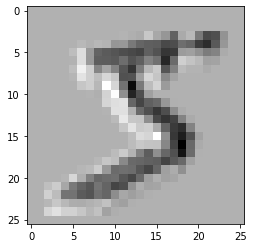
plt.imshow(model(X_train)[0][...,1], cmap='gray')
plt.imshow(model(X_train)[0][...,2], cmap='gray')
Convolution layer -> ReLU를 통과한 데이터
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.reshape(-1,28,28,1)
input_ = tf.keras.Input(shape=(28,28,1))
x = tf.keras.layers.Conv2D(10,3)(input_)
x = tf.keras.layers.ReLU()(x)
model = tf.keras.models.Model(input_,x)
plt.imshow(model(X_train)[0][...,0], cmap='gray')
plt.imshow(model(X_train)[0][...,0], cmap='binary')
plt.imshow(model(X_train)[0][...,1], cmap='gray')
plt.imshow(model(X_train)[0][...,1], cmap='binary')
plt.imshow(model(X_train)[0][...,2], cmap='gray')
plt.imshow(model(X_train)[0][...,2], cmap='binary')
LeNet-5
Gradient-Based Learning Applied to Document Recognition
Yann LeCun, Yoshua Bengio 등..
최초의 Convolutional Neural network가 상업적으로 성공한 논문
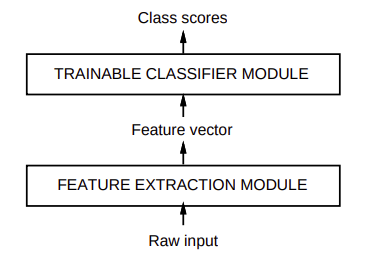
Feature extracion module은 trainable classifier module의 성능을 높이기 위한 수단이었다
나중에 Feature extracion module와 trainable classifier module를 결합해서 End-to-End로 만들었다

32x32를 한 이유는 정 중앙에 숫자를 넣기 위해서 조금 더 크게 만들었다
=> 제약 조건을 만들었다
성능을 높이기 위해서 가정을 추가한 것이다
이미지 크기가 크면 클수록 연산해야 할것이 많아지고, 많은 데이터가 필요하다
그런데 subsampling을 한다는 것은 줄이는 것이기 때문에 정보의 손실이 발생한다
이 지점에서 trade off가 발생한다
데이터가 많을 경우 pooling을 안하는 것이 성능이 더 좋다 하지만, 데이터가 적을 경우는 pooling을 하는 것이 더 좋다
subsampling으로 계산 복잡도를 줄였기 때문에 특징을 더 늘려야 한다 (이미지 피라미드)
데이터가 많으면 많을 수록 column이 많이 있는 것이 좋다(풍부한 nuance를 갖기 때문에)
특징이 있는지 없는 데이터 형태로 변환 시킨다
Subsampling
전체에서 일부만 뽑아서 줄이는 것 ex) pooling
'Computer_Science > Visual Intelligence' 카테고리의 다른 글
| 18일차 - 논문 수업 (CNN) (0) | 2021.10.08 |
|---|---|
| 17일차 - 논문 수업 (CNN) (0) | 2021.10.04 |
| 15일차 - CNN (0) | 2021.10.04 |
| 14일차 - 딥러닝 (Tensorflow) (3) (0) | 2021.10.04 |
| 13일차 - 딥러닝 (Tensorflow) (2) (0) | 2021.09.28 |