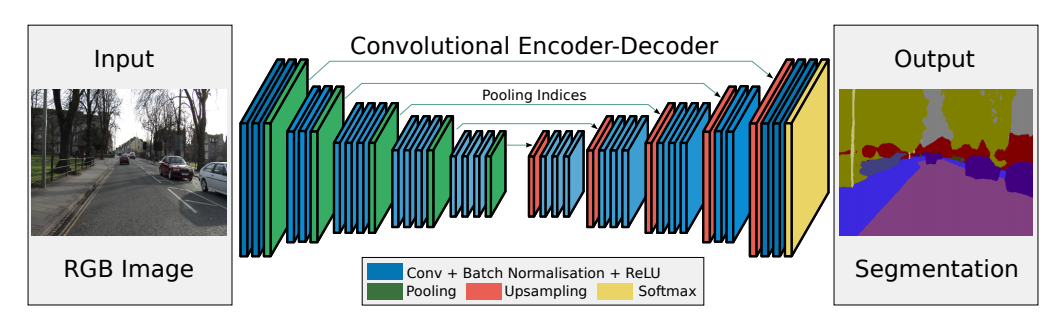
MASK RCNN
instance segmentation의 대표적인 모델
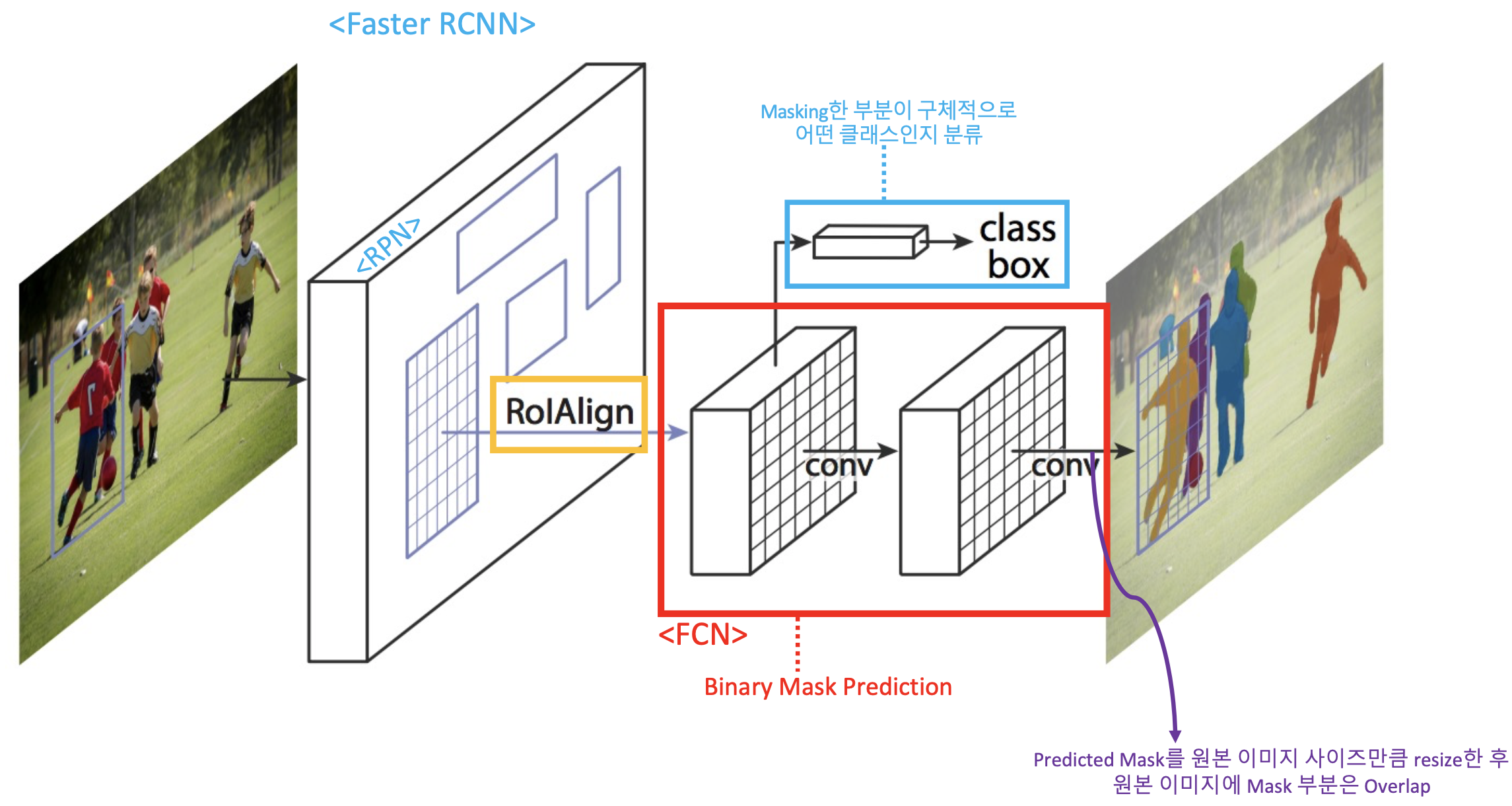
- Faster RCNN과 FCN 기법 개선 및 결합
* ROI-Align
* 기존 bounding box regression과 classification에 binary mask prediction 추가
- 비교적 빠른 detection 시간과 높은 정확도
- 직관적이고 상대적이고 쉬운 구현
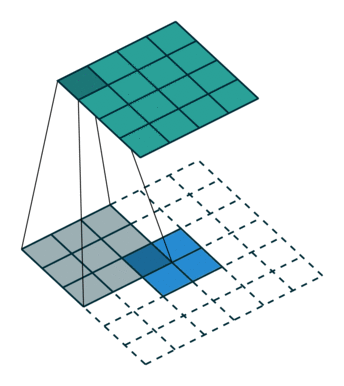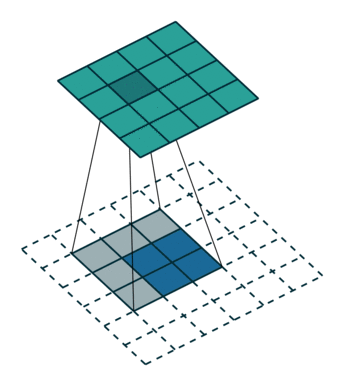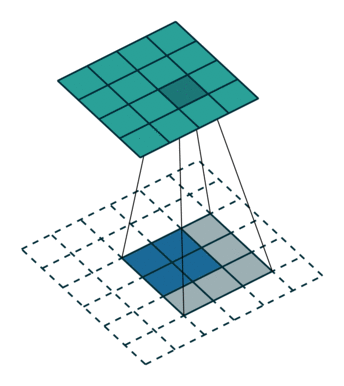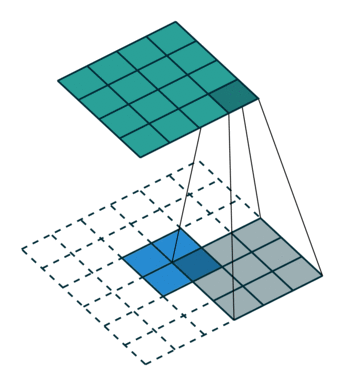
ROI align

segmentation에서 roi pooling 문제점 : masking을 해야해서 아주 정확해야 함
- roi pooling에서 quantization을 하면서 문제 발생
소수점이 생겨서 들어오는 사이즈가 정확하게 매칭이 되지 않음

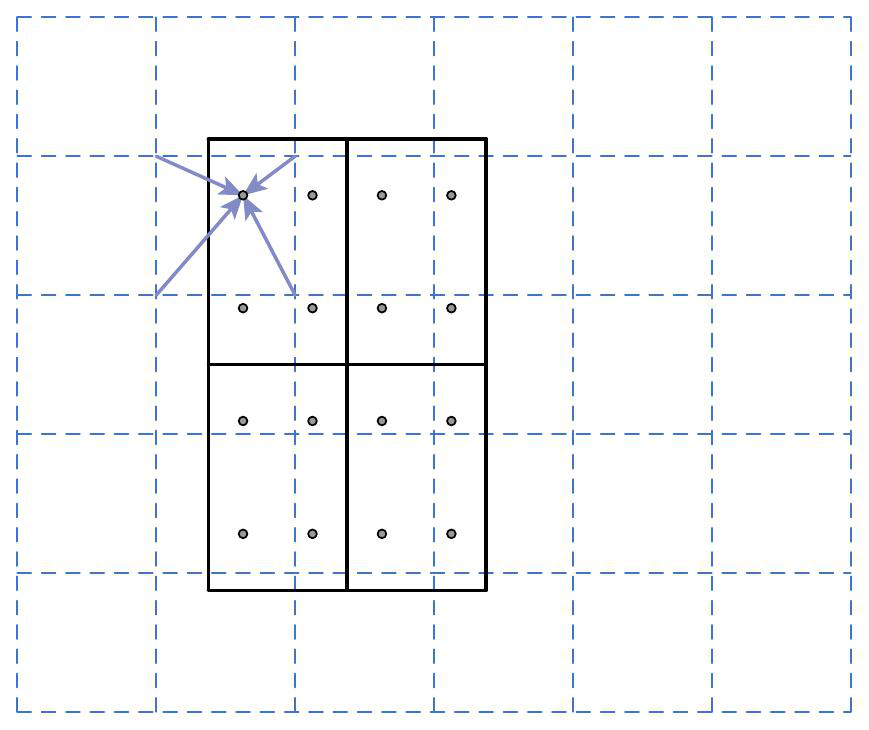
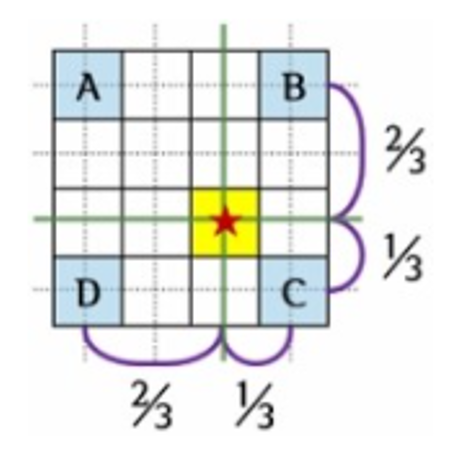
- ROI를 소수점 그대로 매핑하고 roi의 개별 grid에 4개의 point를 균등하게 배열
- 개별 point에서 가장 가까운 feature map Grid를 고려하면서 포인트를 weighted sum으로 계산
- 계산된 포인트를 기반으로 max pooling 수행
영상처리 bilinear interpolation 예제
https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=dic1224&logNo=220882679460&categoryNo=0&parentCategoryNo=207&viewDate=¤tPage=1&postListTopCurrentPage=1&from=search
Bilinear Interpolation을 이용한 ROI-align
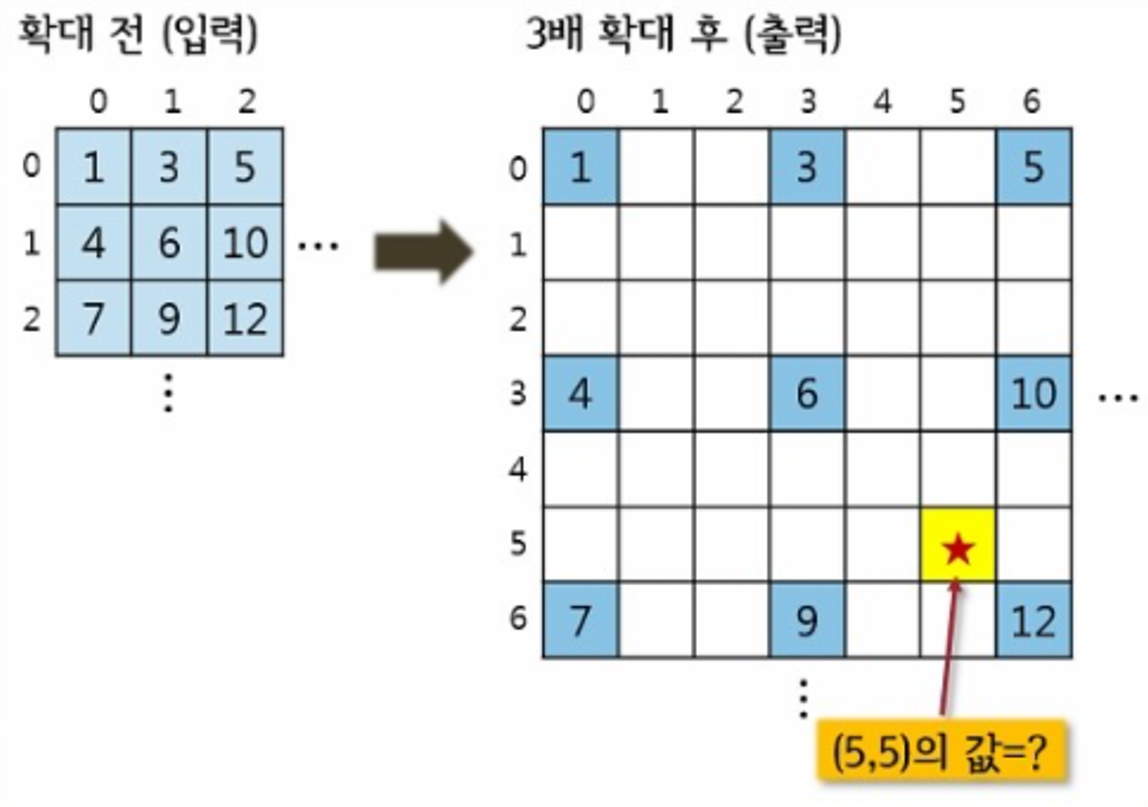
확대하면 깨지게 됨, 대신 빈공간을 유추해서 보정함
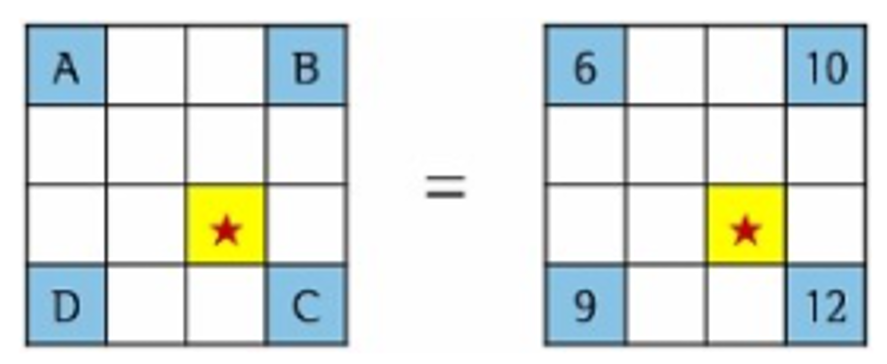
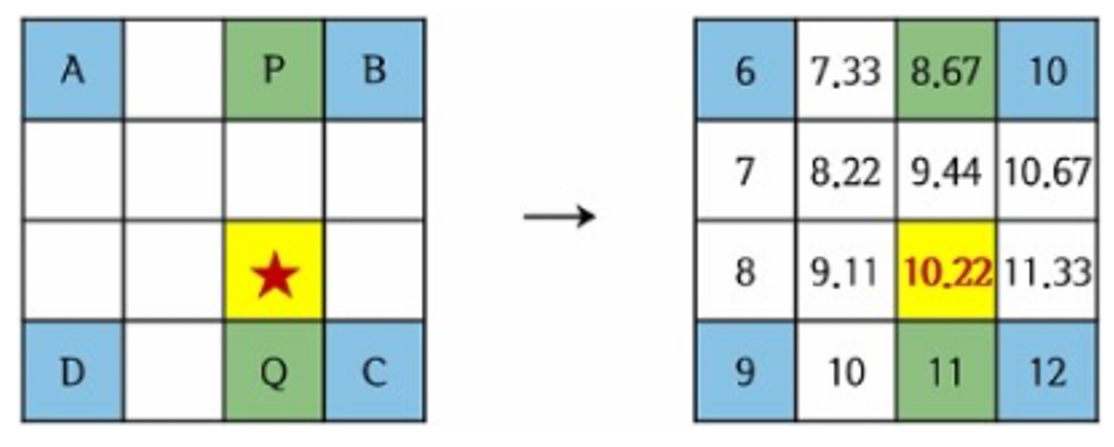
거리에 맞게 계산해서 채워줌
그상태에서 pooling
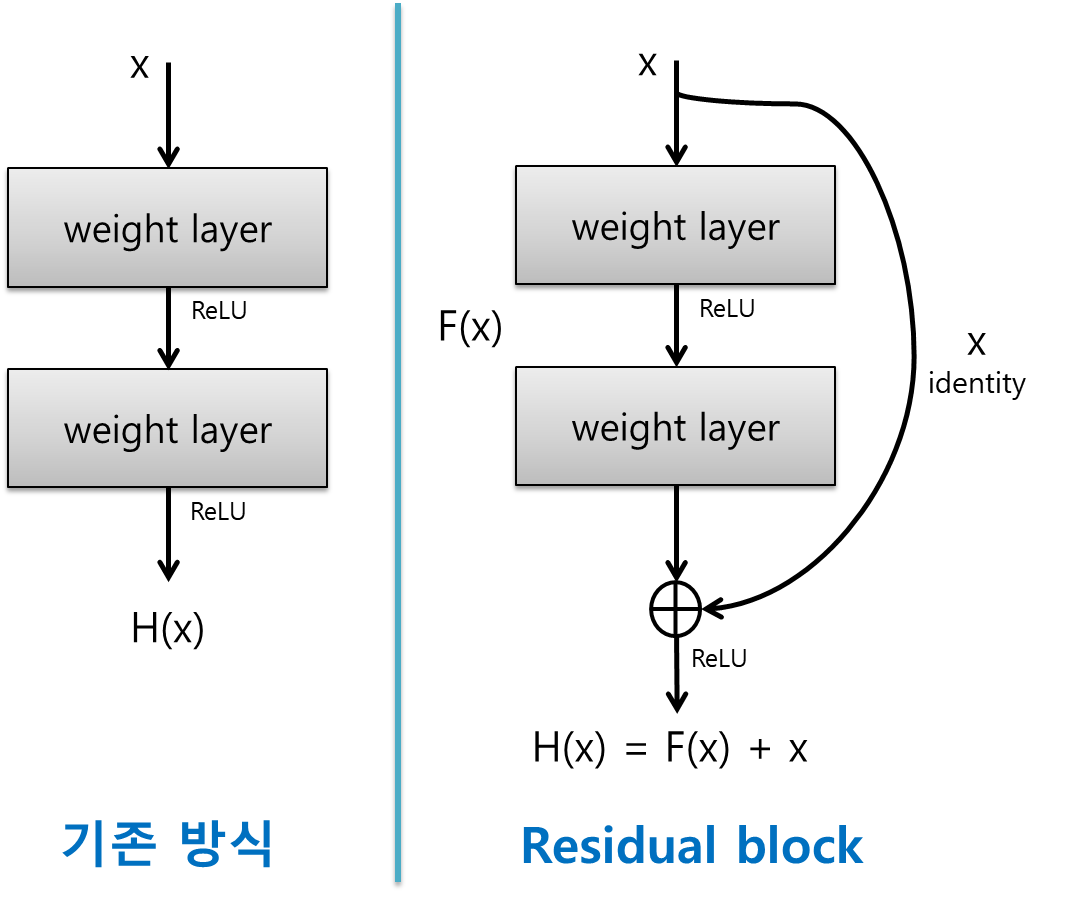
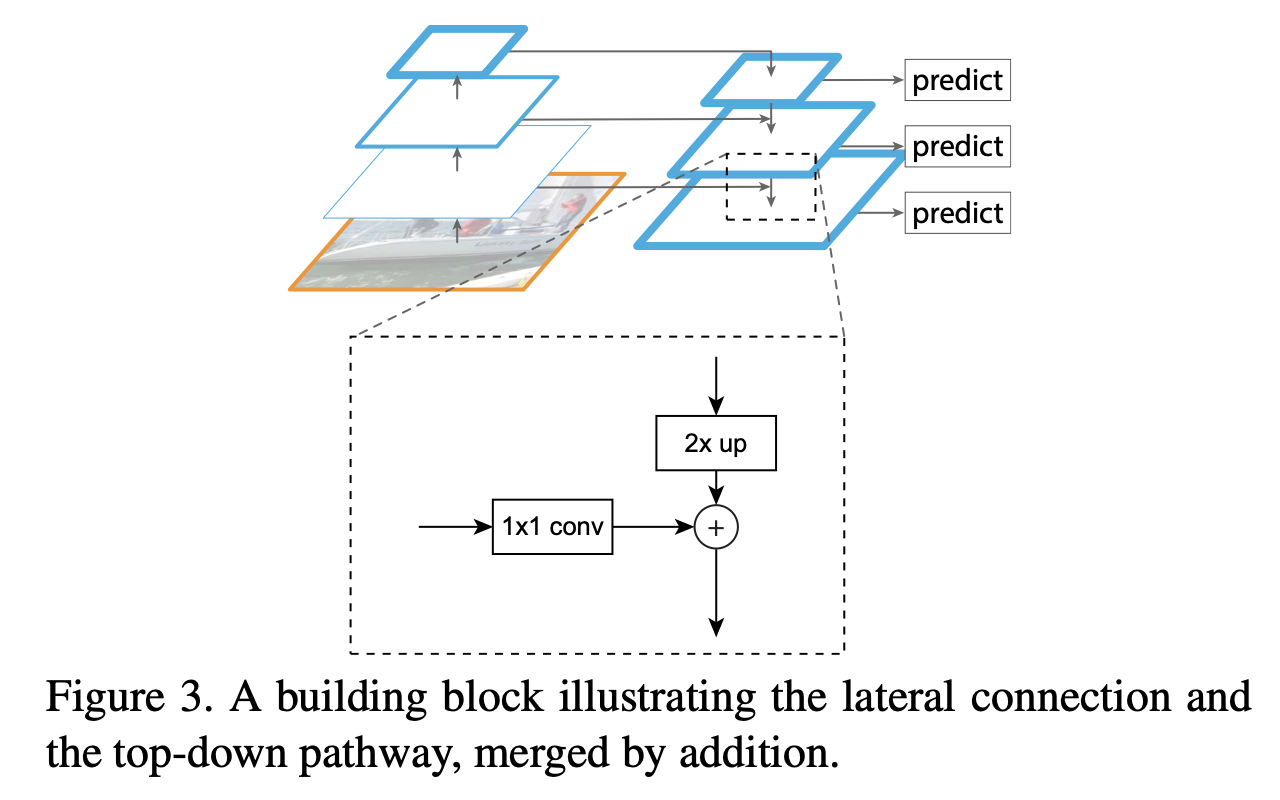
mask rcnn Feature Extractor : Resnet + FPN
Loss function

- k개의 정해진 class에 대해서 그 class에 pixel이 속하는지 그렇지 않은지 sigmoid로 결정 binary-cross-entropy-loss
- mask rcnn에서 mask prediction
- prediction후 resize해서 원본 이미지에 적용
'Computer_Science > Mask RCNN' 카테고리의 다른 글
| 13-2. Semantic Segmentation FCN (0) | 2021.10.31 |
|---|---|
| 13-1. Segmentation (0) | 2021.10.27 |