728x90
반응형
SSD+Mobilenet v3 Object Detection 수행.
- https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API 에 다운로드 URL 있음.
- weight파일은 http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v2_coco_2018_03_29.tar.gz 에서 다운로드
- SSD + Mobilenet v3 backbone은 opencv dnn 모듈이 아니라 dnn_DetectionModel() 함수로 생성 가능하며, 이를 사용하기 위해서는 Opencv의 버전을 Upgrade해야함.
!mkdir ./pretrained
!wget -O ./pretrained/ssd_mobilenet_v3_large_coco_2020_01_14.tar.gz http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v3_large_coco_2020_01_14.tar.gz
!wget -O ./pretrained/ssd_config_02.pbtxt https://gist.githubusercontent.com/dkurt/54a8e8b51beb3bd3f770b79e56927bd7/raw/2a20064a9d33b893dd95d2567da126d0ecd03e85/ssd_mobilenet_v3_large_coco_2020_01_14.pbtxt
!!tar -xvf ./pretrained/ssd_mobilenet*.tar.gz -C ./pretrainedimport cv2
print(cv2.__version__)
# 4.1.2opencv의 버전을 Upgrade한 후 dnn_DetectionModel() 사용.
- https://github.com/opencv/opencv/pull/16760
- dnn_DetectionModel()은 dnn_Model 객체 반환
- 해당 SSD 모델은 image pixel값을 -1 ~ 1 사이로 정규화하고 image size는 320, 320으로 설정.
!pip install opencv-python==4.5.2.54import cv2
cv_net_m = cv2.dnn_DetectionModel('/content/pretrained/ssd_mobilenet_v3_large_coco_2020_01_14/frozen_inference_graph.pb',
'/content/pretrained/ssd_config_02.pbtxt')
cv_net_m.setInputSize(320, 320)
cv_net_m.setInputScale(1.0 / 127.5)
cv_net_m.setInputMean((127.5, 127.5, 127.5))
cv_net_m.setInputSwapRB(True)dnn_Model 객체의 detect() 메소드는 입력 이미지를 받아서 특정 confidence threshold 이상의 모든 object inference 결과를 반환.
- class id값, confidence score값, bbox 좌표값이 arrary로 반환됨.
- bbox 좌표값의 경우 0~1사이 값이 아니라 정수형의 위치값이 반환됨. 단 xmin, ymin, width, height 형태로 반환되므로 유의 필요.
img = cv2.imread('/content/data/beatles01.jpg')
draw_img = img.copy()
classes, confidences, boxes = cv_net_m.detect(img, confThreshold=0.5)classes, confidences, boxes
(array([[1],
[1],
[1],
[1],
[3],
[3],
[3],
[3],
[3],
[3],
[1]], dtype=int32), array([[0.7795709 ],
[0.7573837 ],
[0.75332576],
[0.71246046],
[0.6756758 ],
[0.6396257 ],
[0.5794208 ],
[0.5773531 ],
[0.553491 ],
[0.5314793 ],
[0.50632125]], dtype=float32), array([[ 48, 258, 154, 291],
[213, 252, 158, 298],
[386, 266, 167, 300],
[560, 251, 153, 322],
[496, 226, 80, 67],
[451, 227, 28, 21],
[472, 226, 43, 35],
[375, 219, 17, 17],
[415, 220, 18, 17],
[314, 227, 38, 23],
[258, 259, 101, 268]], dtype=int32))classes.shape, confidences.shape, boxes.shape
# ((11, 1), (11, 1), (11, 4))labels_to_names = {1:'person',2:'bicycle',3:'car',4:'motorcycle',5:'airplane',6:'bus',7:'train',8:'truck',9:'boat',10:'traffic light',
11:'fire hydrant',12:'street sign',13:'stop sign',14:'parking meter',15:'bench',16:'bird',17:'cat',18:'dog',19:'horse',20:'sheep',
21:'cow',22:'elephant',23:'bear',24:'zebra',25:'giraffe',26:'hat',27:'backpack',28:'umbrella',29:'shoe',30:'eye glasses',
31:'handbag',32:'tie',33:'suitcase',34:'frisbee',35:'skis',36:'snowboard',37:'sports ball',38:'kite',39:'baseball bat',40:'baseball glove',
41:'skateboard',42:'surfboard',43:'tennis racket',44:'bottle',45:'plate',46:'wine glass',47:'cup',48:'fork',49:'knife',50:'spoon',
51:'bowl',52:'banana',53:'apple',54:'sandwich',55:'orange',56:'broccoli',57:'carrot',58:'hot dog',59:'pizza',60:'donut',
61:'cake',62:'chair',63:'couch',64:'potted plant',65:'bed',66:'mirror',67:'dining table',68:'window',69:'desk',70:'toilet',
71:'door',72:'tv',73:'laptop',74:'mouse',75:'remote',76:'keyboard',77:'cell phone',78:'microwave',79:'oven',80:'toaster',
81:'sink',82:'refrigerator',83:'blender',84:'book',85:'clock',86:'vase',87:'scissors',88:'teddy bear',89:'hair drier',90:'toothbrush',
91:'hair brush'}import matplotlib.pyplot as plt
green_color=(0, 255, 0)
red_color=(0, 0, 255)
for class_id, confidence_score, box in zip(classes.flatten(), confidences.flatten(), boxes):
if confidence_score > 0.5:
caption = "{}: {:.4f}".format(labels_to_names[class_id], confidence_score)
# box 반환 좌표값은 정수형 위치 좌표임. xmin, ymin, width, height임에 유의
cv2.rectangle(draw_img, (box[0], box[1]), (box[0]+box[2], box[1]+box[3]), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (box[0], box[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.6, red_color, 2)
print(caption, class_id, box)
draw_img = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(draw_img)
person: 0.7796 1 [ 48 258 154 291]
person: 0.7574 1 [213 252 158 298]
person: 0.7533 1 [386 266 167 300]
person: 0.7125 1 [560 251 153 322]
car: 0.6757 3 [496 226 80 67]
car: 0.6396 3 [451 227 28 21]
car: 0.5794 3 [472 226 43 35]
car: 0.5774 3 [375 219 17 17]
car: 0.5535 3 [415 220 18 17]
car: 0.5315 3 [314 227 38 23]
person: 0.5063 1 [258 259 101 268]
<matplotlib.image.AxesImage at 0x7fbc190c4950>
단일 이미지의 object detection을 함수로 생성
import time
def get_detected_img_renew(cv_net, img_array, score_threshold, is_print=True):
draw_img = img_array.copy()
start = time.time()
classes, confidences, boxes = cv_net.detect(img_array, confThreshold=0.5)
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for class_id, confidence_score, box in zip(classes.flatten(), confidences.flatten(), boxes):
if confidence_score > 0.5:
caption = "{}: {:.4f}".format(labels_to_names[class_id], confidence_score)
cv2.rectangle(draw_img, (box[0], box[1]), (box[0]+box[2], box[1]+box[3]), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (box[0], box[1]), cv2.FONT_HERSHEY_SIMPLEX, 0.6, red_color, 2)
print(caption)
if is_print:
print('Detection 수행시간:',round(time.time() - start, 2),"초")
return draw_imgdnn_Model을 만드는 함수 생성
## dnn_Model을 만드는 함수 생성.
def get_cv_detection_model(pretrained_path, config_path):
cv_net = cv2.dnn_DetectionModel(pretrained_path, config_path)
cv_net.setInputSize(320, 320)
cv_net.setInputScale(1.0 / 127.5)
cv_net.setInputMean((127.5, 127.5, 127.5))
cv_net.setInputSwapRB(True)
return cv_net
cv_net_m = get_cv_detection_model('/content/pretrained/ssd_mobilenet_v3_large_coco_2020_01_14/frozen_inference_graph.pb',
'/content/pretrained/ssd_config_02.pbtxt')img = cv2.imread('./data/beatles01.jpg')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img_renew(cv_net_m, img, score_threshold=0.5, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)
# person: 0.7796
person: 0.7574
person: 0.7533
person: 0.7125
car: 0.6757
car: 0.6396
car: 0.5794
car: 0.5774
car: 0.5535
car: 0.5315
person: 0.5063
Detection 수행시간: 0.17 초
!wget -O ./data/baseball01.jpg https://raw.githubusercontent.com/chulminkw/DLCV/master/data/image/baseball01.jpg
img = cv2.imread('./data/baseball01.jpg')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img_renew(cv_net_m, img, score_threshold=0.5, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)
person: 0.8579
person: 0.8535
person: 0.8509
baseball glove: 0.6942
sports ball: 0.5895
baseball bat: 0.5015
Detection 수행시간: 0.12 초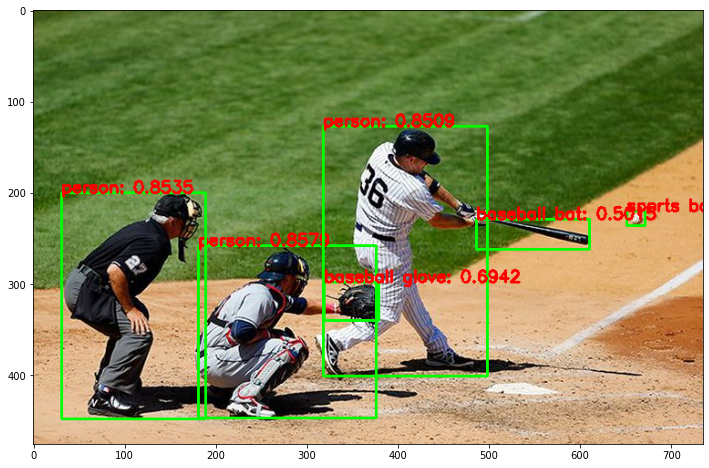
Video Inferece 수행.
!wget -O ./data/Jonh_Wick_small.mp4 https://github.com/chulminkw/DLCV/blob/master/data/video/John_Wick_small.mp4?raw=truedef do_detected_video_renew(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt, )
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
returned_frame = get_detected_img_renew(cv_net, img_frame, score_threshold=score_threshold, is_print=True)
vid_writer.write(returned_frame)
# end of while loop
vid_writer.release()
cap.release()do_detected_video_renew(cv_net_m, '/content/data/Jonh_Wick_small.mp4', './data/John_Wick_small_m3.mp4', 0.2, False)
Detection 수행시간: 0.12 초
person: 0.7723
car: 0.7415
car: 0.6630
person: 0.6345
person: 0.5755
person: 0.5379
person: 0.5283
car: 0.5281
person: 0.5165
car: 0.5078
person: 0.5013
Detection 수행시간: 0.11 초
person: 0.7713
car: 0.7474
car: 0.6665
person: 0.6326
person: 0.5710
person: 0.5382
person: 0.5300
car: 0.5279
person: 0.5178
person: 0.5146
car: 0.5085
Detection 수행시간: 0.11 초
person: 0.7318
car: 0.7291
car: 0.7254
person: 0.7085
car: 0.6152
person: 0.5985
car: 0.5417
person: 0.5402
Detection 수행시간: 0.11 초
person: 0.7599
car: 0.7229
car: 0.7176
person: 0.6913
person: 0.6340
car: 0.5954
car: 0.5493
car: 0.5431
bicycle: 0.5312
person: 0.5130
Detection 수행시간: 0.11 초
person: 0.7522
car: 0.7364
car: 0.7213
car: 0.6430
person: 0.6416
person: 0.6216
car: 0.5797
bicycle: 0.5395
person: 0.5202
car: 0.5138
bicycle: 0.5034
Detection 수행시간: 0.12 초
더 이상 처리할 frame이 없습니다.
반응형
'Computer_Science > Computer Vision Guide' 카테고리의 다른 글
| 6-7~8. TF hub pretrained model SSD Inference (0) | 2021.10.22 |
|---|---|
| 6-6. TensorFlow hub (0) | 2021.10.22 |
| 6-4. openCV SSD Inference 1/2 (0) | 2021.10.20 |
| 6-3. SSD 네트웤 구조, Multi scale Feature Map, Anchor box (0) | 2021.10.19 |
| 6-2. MultiScale feature map, Default(feature) map (0) | 2021.10.19 |