
* tensorflow는 VGG대신 Resnet, inception을 씀, 혹은 mobilenet을 써서 detection 시간 줄이기도 함
# 각 다른 scale의 feature map에서 classifier를 구성하고 각 classifiers를 최종적으로 종합하는 구조임.
- object detecting 할 수 있는 Default box정보를 전달함
=> faster RCNN의 anchor box와 동일함
# anchor box 정보를 학습하는 방법
- 각각 feature map에서 3x3 cnn연산을 함
=> (4 : 개별 anchor box가 채워야하는 정보(class 개수 pascal 20개), 좌표 3개 ) x (4 : anchor box 개수) // * faster rcnn은 9개
# NMS
- 결과적으로 8732가 모였는데 너무 많으니 non-maximum suppression으로 가장 유력한 것만 남김
# Anchor box를 활용해서 convolution predictor for detection
(512, 38, 38) 으로 3x3 연산을 하는데 20여개의 class + bg 1개 object 확률(cs), 4개 좌표

# SSD의 multi scale Feature Map과 Anchor box 적용
8x8 feature map
- 4개의 anchorbox 중에 ground box와 매칭되는게 2개
- 매칭기준은 iou가 몇 이상인가
- 큰 개는 anchor box 내에 안들어와서 매칭이 안됨
4x4 feature map
- feature map이 추상화되어 scale이 작아지니 anchorbox가 매칭할 수 있게 됨.
feature map이 줄어드는 과정에서 anchor box와 ground box의 간격을 줄여나가는 계산을 함.
SSD Training

n : matched anchorbox 개수,
Matching 전략
- bounding box와 겹치는 IOU가 0.5dltkddls anchor box 들의 classification과 bounding box Regression을 최적화 학습 수행.
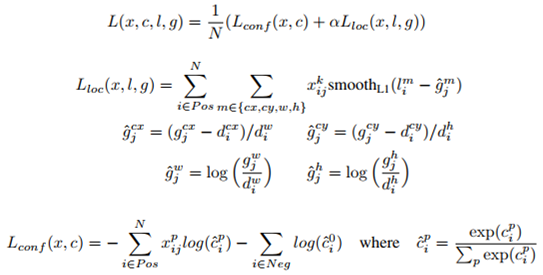
위치 offset을 줄이도록 계속 weight를 갱신하여 줄여 냄.
# performance
- Data augmentation의 영향이 큼
- one-stage detector는 작은 object에 대한 성능이 떨어짐 => feature pyramid, retinanet로 개선
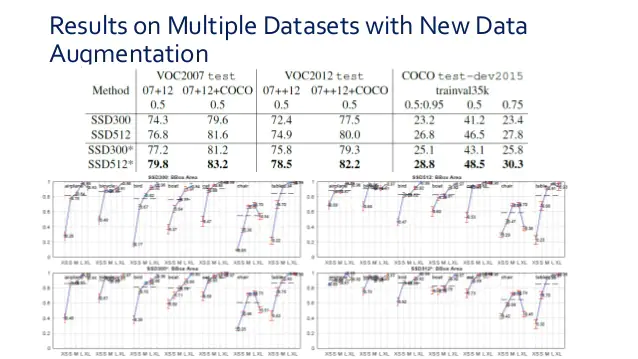
augmentation을 하고나서 작은 데이터에 대한 성능이 높아졌다.
- 큰 화면, 선명도 좋은 이미지 등
'Computer_Science > Computer Vision Guide' 카테고리의 다른 글
| 6-5. opencv를 이용한 SSD Inference 실습2 (0) | 2021.10.22 |
|---|---|
| 6-4. openCV SSD Inference 1/2 (0) | 2021.10.20 |
| 6-2. MultiScale feature map, Default(feature) map (0) | 2021.10.19 |
| 6-1.Single Shot Detector (0) | 2021.10.19 |
| 5-11~12. coco형태 BCCD데이터 학습 - 테스트 데이터 세트 inference, evaluation (0) | 2021.10.19 |