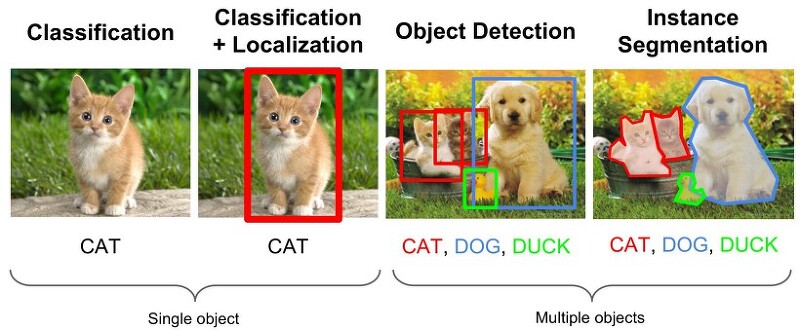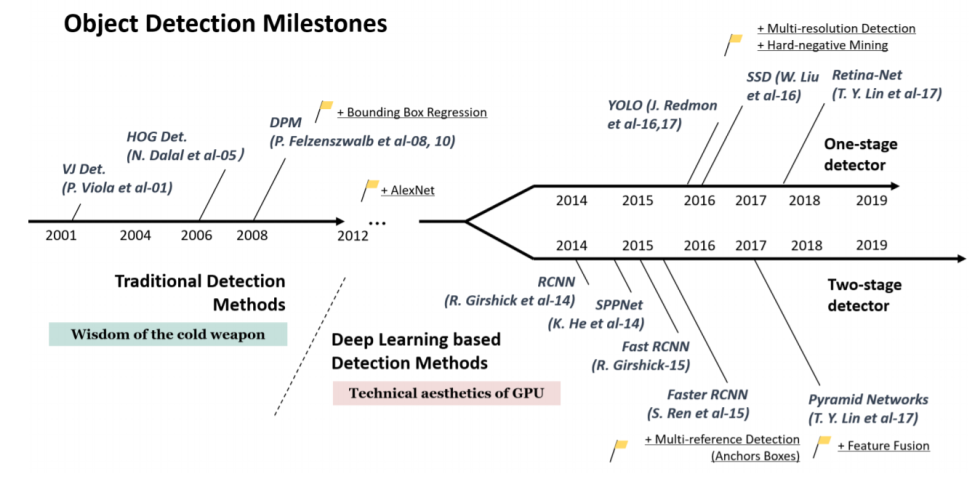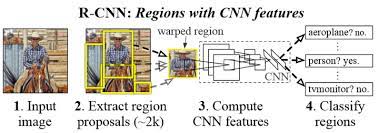
1. object detection의 주요 구성 요소
1) 영역 추정
Region Propsosal
bounding box를 예측
object 위치를 추정 : regression, bounding box 내 object가 뭔지 인지하는게 : classification
초기엔 딥러닝이 알아서 찾아주지 않을까 했는데, 예측 성능이 형편없더라
loss도 커지고, 성능도 낮았다.
object가 있을만한 위치를 제대로 알려줘야 한다. 정확히 매칭을 시켜주기 위해,
있을만한 영역에 대한 힌트를 주어야한다 => 영역 추정
2) Detection을 위한 Deep Learning 네트웍 구성
- Feature Extraction + Classification
: back born
작은 object를 만듬, resNet
- Feature Pyramid Network
: neck
만들어낸 object를 체계적으로 구성함
- Network Prediction + classification + regression
: head
object를 classification 함
3) etc
- IOU
- NMS : 어떤 처리를 하는지
- mAP
- Anchor Box
2. 왜 어려운가?
1) classification과 regression을 동시에 수행
보통은 단일식을 이용하는데, 동시에 수행하고, 동시에 성능, loss 가 좋아야 함.
2) 다양한 크기와 유형의 오브젝트가 섞임
크기가 크고 작고, 길고 뭉뚝하고, 다양한 오브젝트모양
feature map을 detect 해야함
3) 중요한 detect 시간
시간도 중요함, 예를 들어 cctv, 자율주행 등 알고리즘 딜레마가 있음
수행시간 vs 성능
4) 명확하지 않은 이미지
작은 object, background를 잘못 detecting 하는 경우
5) 데이터 세트의 부족
annotation을 만들어 줘야함, 생성하기가 상대적으로 어려움
'Computer_Science > Computer Vision Guide' 카테고리의 다른 글
| 1-7. IoU 성능평가 [colab] (0) | 2021.09.11 |
|---|---|
| 1-6. selective search 시각화 [colab] (0) | 2021.09.11 |
| 1-4~5. Region Proposal(영역추정) (0) | 2021.09.11 |
| 1-3. Object Localization과 Detection의 이해 (0) | 2021.09.11 |
| 1-1. object detection 개요 [딥러닝 컴퓨터 비전 완벽가이드 필기] (0) | 2021.09.09 |