YOLO (You Only Look Once)
import tensorflow as tfvgg = tf.keras.applications.VGG16()
vgg.layers[2].get_config()
{'activation': 'relu',
'activity_regularizer': None,
'bias_constraint': None,
'bias_initializer': {'class_name': 'Zeros', 'config': {}},
'bias_regularizer': None,
'data_format': 'channels_last',
'dilation_rate': (1, 1),
'dtype': 'float32',
'filters': 64,
'groups': 1,
'kernel_constraint': None,
'kernel_initializer': {'class_name': 'GlorotUniform',
'config': {'seed': None}},
'kernel_regularizer': None,
'kernel_size': (3, 3),
'name': 'block1_conv2',
'padding': 'same',
'strides': (1, 1),
'trainable': True,
'use_bias': True}layer = tf.keras.layers.Dense(2)
layer.build((None,2))
layer.weights
# [<tf.Variable 'kernel:0' shape=(2, 2) dtype=float32, numpy=
# array([[-0.9223565 , -0.76073015],
# [-0.94507563, 0.25733256]], dtype=float32)>,
# <tf.Variable 'bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>]layer2 = tf.keras.layers.Dense(2) # __call__는 build가 되어 있는지 확인하고 되어 있으면 call 연산
layer2(tf.constant([[1,2,3],[4,5,6]])) # build가 되어 있지 않으면 build후 call 연산
# <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
# array([[ 2.7301223, -2.2875605],
# [ 5.7739477, -3.6619558]], dtype=float32)>model = tf.keras.models.Sequential([
tf.keras.layers.Dense(2, input_shape(2,)) # (None,2) => 요소가 2개인 데이터 N개
])model(tf.constant([[1,2,3],[4,5,6]]))
# <tf.Tensor: shape=(2, 2), dtype=float32, numpy=
# array([[ 5.3184466, 3.66491 ],
# [12.929317 , 7.4551005]], dtype=float32)>model.input_shape # build 하지 않으면 input_shape을 알 수 없다
# (2, 3)model.weights
# [<tf.Variable 'dense_3/kernel:0' shape=(3, 2) dtype=float32, numpy=
# array([[ 0.6508478 , -0.3525918 ],
# [ 0.99072933, 0.830464 ],
# [ 0.89538 , 0.7855246 ]], dtype=float32)>,
# <tf.Variable 'dense_3/bias:0' shape=(2,) dtype=float32, numpy=array([0., 0.], dtype=float32)>]Build의 의미
ex) layer = tf.keras.layer.Dense(2)
1. layer를 만들때 내부적으로 __init__가 실행되며 unit을 인자로 받는다
2. 구조적으로 인자로 받은 unit수 만큼 perceptron을 생성한다
3. input의 인자 개수에 따라 자동적으로 weight metrix의 크기가 결정된다
4. unit수 만큼 output으로 나온다
build는 weight metrix의 크기를 정하고 만드는 작업을 의미한다 + 초기화
Custom layer (YOLO)
class YoloReshape(tf.keras.layers.Layer):
def __init__(self, shape_):
super().__init__()
self.shape_ = tuple(shape_)
def call(self, input_):
S = [self.shape_[0], self.shape_[1]]
C = 20
B = 2
S[0]*S[1]*C
ix = S[0]*S[1]*C
ix2 = S[0]*S[1]*B
boxs = tf.reshape(input_[:,:ix2], tuple(input_.shape[0],S[0],S[1],B*4))
boxs = tf.nn.sigmoid(boxs)
confidence = tf.reshape(input_[:,ix2:ix1], tuple(input_.shape[0],S[0],S[1],B))
confidence = tf.nn.sigmoid(confidence)
class_prob = tf.reshape(input_[:,ix1:], tuple(input_.shape[0],S[0],S[1],C)) # input_.shape[0] + tuple(S[0],S[1],C) / 10,20
class_prob = tf.nn.softmax(class_prob) # 확률로 강제시킨다
return tf.concat([boxs, confidence, class_prob])
def build(self):
pass
def get_config(self):
config = super().get_config().copy()
config.update({
'target_shape':self.shape_
})
return configRepresentation learning
- 어떤 task를 수행하기에 적절하게 데이터의 representation을 변형하는 방법을 학습하는 것
- 어떤 task를 더 쉽게 수행할 수 있는 다른 형태로 표현을 만드는 것 예) PCA
AutoEncoder
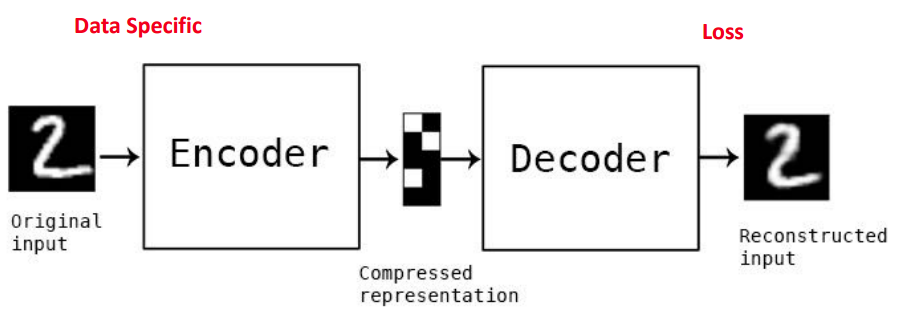
Unsupervised learning
Self-supervised learning
Manifold learning (N차원의 공간을 N보다 작은 저차원의 특성으로 표현하여 학습하는 방법)
Feature extraction
Autoencoder는 내 자신을 작은 차원으로 표현하는 encoder와 작은 차원을 그대로 복원하는 decoder로 구성되어 있는 하나의 모델
Autoencoder를 이상치 제거에서 활용한다고 했을 때
Encoder를 거쳐 차원이 줄어들면 핵심 특징을 제외한 것들은 자연스럽게 사라지게 되므로
noise가 포함된 데이터가 autoencoder를 통과하면 noise는 사라지게 될 것이다
비용절감 차원에서 좋은 모델
self-supervised: 자기 자신의 데이터가 target이 된다
AutoEncoder 구현
import tensorflow as tf(X_train, _), (X_test, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train.reshape(60000,28*28)
X_train = X_train/255
X_test = X_test.reshape(10000,28*28)
X_test = X_test/255input_ = tf.keras.Input((784,)) # 28x28 image이기 때문에
encoder = tf.keras.layers.Dense(32)(input_) # layer는 encoder와 decoder가 대칭이 되도록 설계 해야 한다
encoder = tf.keras.layers.ReLU()(encoder)
decoder = tf.keras.layers.Dense(784, activation='sigmoid')(encoder) # Mnist
autoencoder = tf.keras.models.Model(input_, decoder)
autoencoder.compile(loss=tf.keras.losses.BinaryCrossentropy(), optimizer='adam')autoencoder.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 784)] 0
_________________________________________________________________
dense (Dense) (None, 32) 25120
_________________________________________________________________
re_lu (ReLU) (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 784) 25872
=================================================================
Total params: 50,992
Trainable params: 50,992
Non-trainable params: 0
_________________________________________________________________history = autoencoder.fit(X_train, X_train, epochs=50)
Epoch 1/50
1875/1875 [==============================] - 5s 2ms/step - loss: 0.1629
Epoch 2/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1044
Epoch 3/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0966
Epoch 4/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0951
Epoch 5/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0946
Epoch 6/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0942
Epoch 7/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0940
Epoch 8/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0939
Epoch 9/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0938
Epoch 10/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0937
Epoch 11/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0936
Epoch 12/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0935
Epoch 13/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0935
Epoch 14/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0934
Epoch 15/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0934
Epoch 16/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0934
Epoch 17/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0933
Epoch 18/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0933
Epoch 19/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0932
Epoch 20/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0932
Epoch 21/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0932
Epoch 22/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0931
Epoch 23/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0931
Epoch 24/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0931
Epoch 25/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0931
Epoch 26/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0930
Epoch 27/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0930
Epoch 28/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0930
Epoch 29/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0930
Epoch 30/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0929
Epoch 31/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0929
Epoch 32/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0929
Epoch 33/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0929
Epoch 34/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0929
Epoch 35/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 36/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 37/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 38/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 39/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 40/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 41/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0928
Epoch 42/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 43/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 44/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 45/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 46/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0927
Epoch 47/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0926
Epoch 48/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0926
Epoch 49/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0926
Epoch 50/50
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0926import matplotlib.pyplot as plt
img = 7
fig, axs = plt.subplots(1,2)
axs[0].imshow(X_test[img].reshape(28,28))
axs[1].imshow(autoencoder(X_test)[img].numpy().reshape(28,28))
# 대표적인 특징만 표현된다 (섬세하게 재현되지는 않는다)
layer = tf.keras.layers.Dense(1)
layer.get_config()
# activity_regularizer: 레이어 출력에 페널티를 적용하는 정규화 기법 / BN 때문에 더 이상 잘 사용하지 않는다
{'activation': 'linear',
'activity_regularizer': None,
'bias_constraint': None,
'bias_initializer': {'class_name': 'Zeros', 'config': {}},
'bias_regularizer': None,
'dtype': 'float32',
'kernel_constraint': None,
'kernel_initializer': {'class_name': 'GlorotUniform',
'config': {'seed': None}},
'kernel_regularizer': None,
'name': 'dense_2',
'trainable': True,
'units': 1,
'use_bias': True}Convolution 결과 복원
input_ = tf.keras.Input((28,28,1))
x = tf.keras.layers.Conv2D(16,3, padding='same')(input_)
x = tf.keras.layers.Conv2D(8,3, padding='same')(x)
x = tf.keras.layers.Conv2D(16,3, padding='same')(x)
model = tf.keras.models.Model(input_, x)
model.summary()
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 8) 1160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 16) 1168
=================================================================
Total params: 2,488
Trainable params: 2,488
Non-trainable params: 0
_________________________________________________________________Sparse Auto-Encoder
차원을 늘리는 모델

'Computer_Science > Visual Intelligence' 카테고리의 다른 글
| 35일차 - 논문 수업 (Segmentation) (0) | 2021.11.01 |
|---|---|
| 34일차 - 논문 수업 (VAE) (0) | 2021.11.01 |
| 32일차 - 논문 수업 (AE) (0) | 2021.11.01 |
| 31일차 - 논문 수업 (Detection) (0) | 2021.11.01 |
| 30일차 논문 수업 (Detection) (0) | 2021.11.01 |