Upsampling
1. Nearest Neighbor
- N배 만큼 이미지를 키운다고 했을 때 Input 이미지에서 각 값에서 늘어난 부분에 가장 가까운 값을 채워 넣는다
2. Bed of Nails
- N배 만큼 이미지를 키운다고 했을 때 Input 이미지에서 늘어난 부분에 0값을 채워 넣는다
- ZFNet의 unpooling은 bed of nails의 일종이다

x = tf.reshape(tf.range(24), (1,2,3,4))
x
# <tf.Tensor: shape=(1, 2, 3, 4), dtype=int32, numpy=
# array([[[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
#
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]]], dtype=int32)>tf.keras.layers.UpSampling2D((1,2))(x)
# <tf.Tensor: shape=(1, 2, 6, 4), dtype=int32, numpy=
# array([[[[ 0, 1, 2, 3],
# [ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [ 8, 9, 10, 11]],
#
# [[12, 13, 14, 15],
# [12, 13, 14, 15],
# [16, 17, 18, 19],
# [16, 17, 18, 19],
# [20, 21, 22, 23],
# [20, 21, 22, 23]]]], dtype=int32)>from scipy import ndimage, signal
x = tf.reshape(tf.range(9), (3,3))
f = tf.ones((2,2))
ndimage.convolve(x,f,mode='nearest') # 마지막 픽셀의 값을 복사하여 채워 넣고 연산한다
# array([[ 8, 12, 14],
# [20, 24, 26],
# [26, 30, 32]], dtype=int32)Convolution vs Transpose convolution vs Deconvolution
1. Convolution
- 이미지에서 특징을 추출하기 위한 연산 방법
- 보통 이미지에서 중요한 특징을 추출하고 연산량을 줄이기 위해 downsampling이 된다
- 데이터를 상하, 좌우 반전후 correlation연산을 하는 방법
2. Convolution transpose
- Learnable upsampling (보간법을 활용하여 값을 채우는 것과 비슷하다)
- convolution 연산과 전혀 다르지만 연산 결과가 같을 수 있다
- 보간법과 다르게 학습할 수 있는 파라미터가 있는 방법이다
3. Deconvolution
- convolution의 역연산
Transpose convolution
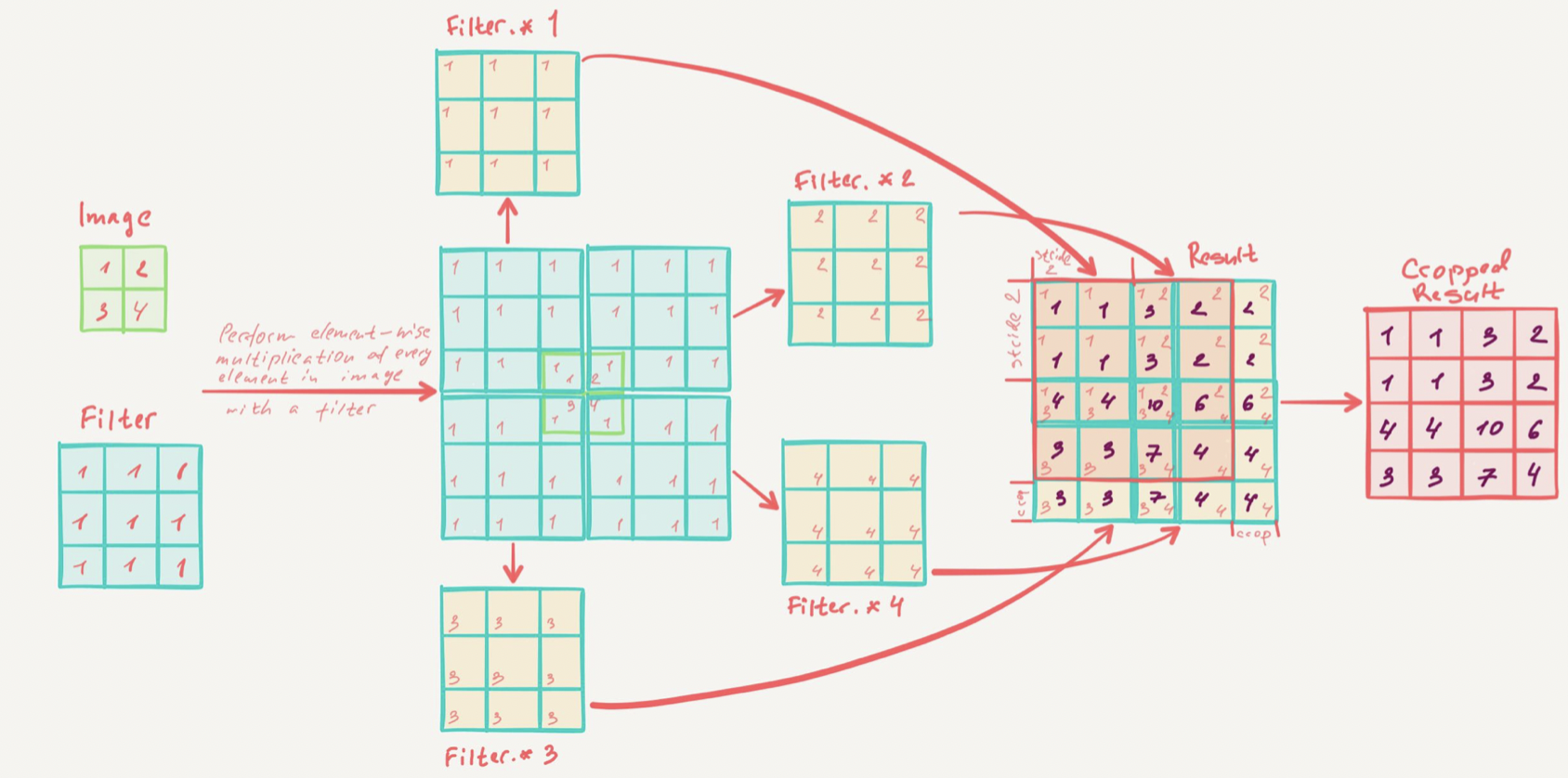

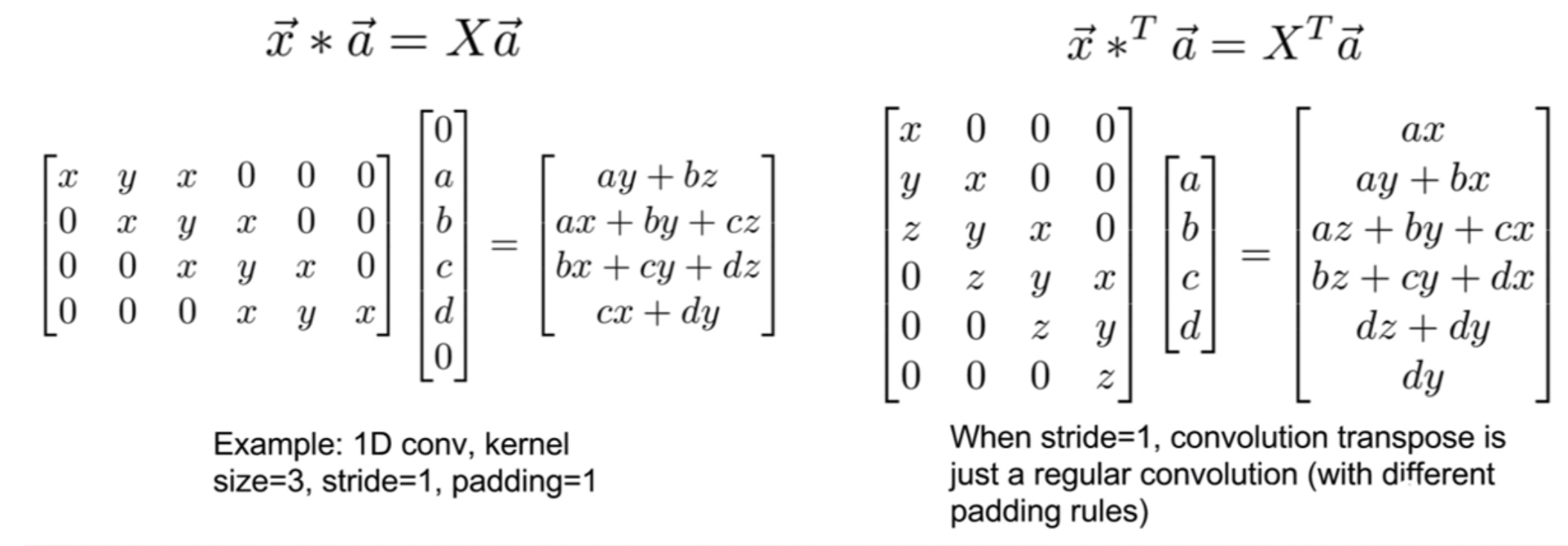
import tensorflow as tf
import numpy as npa = np.array([1,2,3])
b = np.array([-1,1])
signal.convolve(a,b) # convolution transpose 연산결과가 같다
# array([-1, -1, -1, 3])convolution transpose
1 -1 -1
2 -1 => -2 + 1 => -1
3 1 -3 + 2 -1
3 3
Variational AutoEncoder
내가 아는 확률 분포(정규분포)와 찾기 힘든분포를 가능한 근사적으로 하여 확률 분포를 찾아내는 방법
(사후확률 분포를 보다 단순한 확률분포(정규분포)로 근사하는 방법)

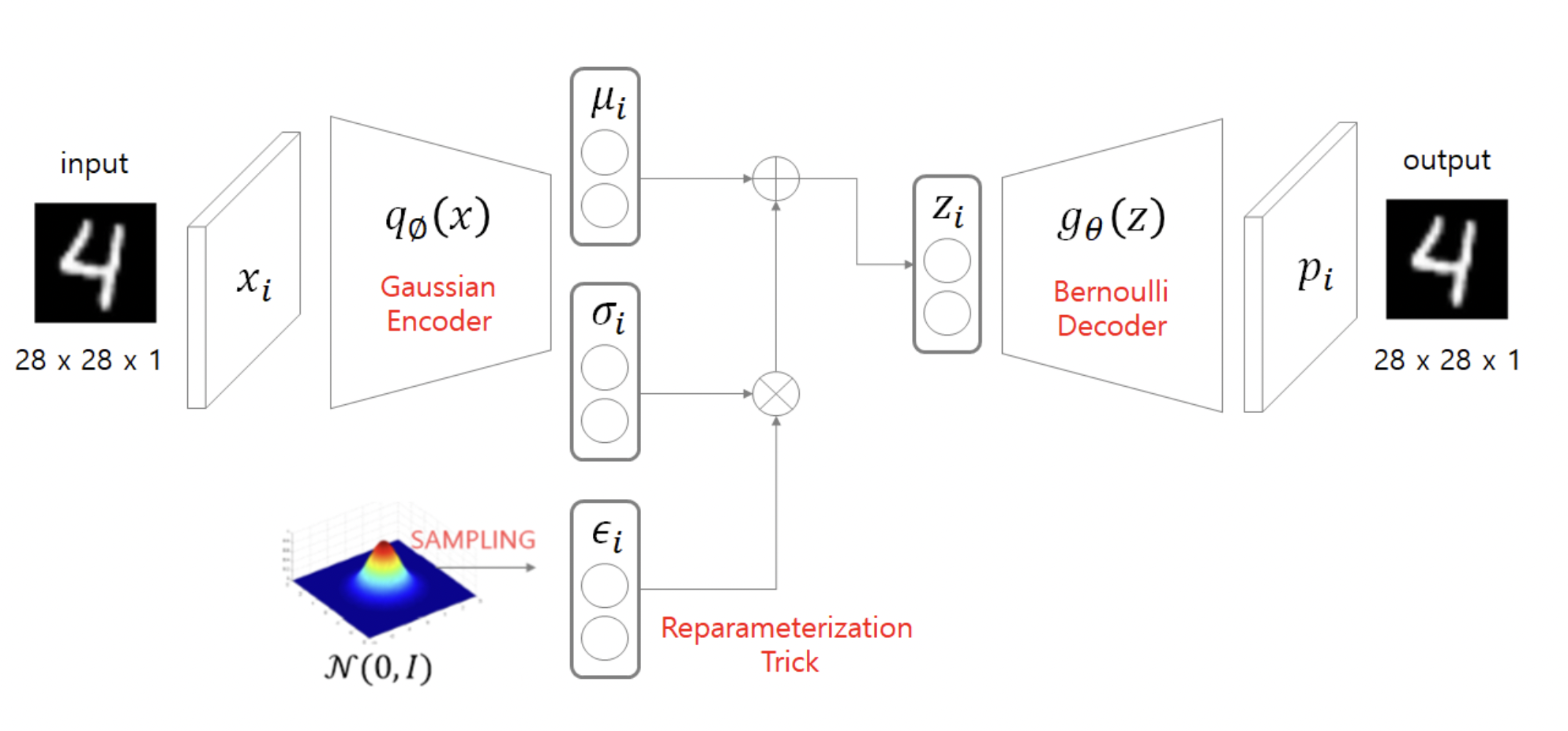
VAE 순서
1. 잠재변수는 다루기 쉬운 확률분포(다차원의 정규분포 등)로 가정한다
2. Encoder 함수를 통해서 평균과 표준편차를 추정한다
3. latent variable에서 sample된 z라는 value(decoder input)를 만든다 (Reparameterization trick)
4. z로부터 sampling을 하여 generator를 생성한다
Decoder network

ELBO(Evidence LowerBOund)



ELBO term을 Φ에 대해 maximize 하면 이상적인 sampling함수를 찾는 것이다
ELBO term을 𝜃에 대해 maximize 하면 MLE 관점에서 Network의 파라미터를 찾는 것이다
출처: https://deepinsight.tistory.com/127 [Steve-Lee's Deep Insight]
AutoEncoder vs Variational AutoEncoder
AutoEncoder와 Variational AutoEncoder 구조가 매우 유사한데
왜 AutoEncoder는 생성모델이 아니고 VAE는 생성 모델일까?
AutoEncoder는 사전 지식에 대한 조건이 없기 때문에 의미 있는 z vector의 latent space가 계속해서 바뀐다
즉 새로운 이미지를 생성할 때 z값이 계속해서 바뀐다
반면 VAE는 사전지식에 대한 조건을 부여 했기 때문에 z vector가 사전지식(내가 아는 분포)를 따른다
따라서 같은 분포에서 sampling을 하기 때문에 생성모델로 볼수 있다
'Computer_Science > Visual Intelligence' 카테고리의 다른 글
| 37일차 - 논문 수업 (Segmentation) (0) | 2021.11.16 |
|---|---|
| 36일차 - 논문 수업 (Segmentation) (0) | 2021.11.16 |
| 34일차 - 논문 수업 (VAE) (0) | 2021.11.01 |
| 33일차 - 논문 수업 (VAE) (0) | 2021.11.01 |
| 32일차 - 논문 수업 (AE) (0) | 2021.11.01 |