import os
import sys
import tensorflow.compat.v1 as tf
sys.path.append('/content/automl/efficientdet')
# /content/automl/efficient 으로 library path가 정상적으로 잡히면 아래 모듈 import가 되어야함.
import hparams_config
from tf2 import anchors # keras folder가 tf2로 변경됨
from model_inspect import ModelInspector
COCO 데이터로 Pretrained된 efficientdet-d0 모델을 다운로드
MODEL = 'efficientdet-d0'
def download(m):
if m not in os.listdir():
!wget https://storage.googleapis.com/cloud-tpu-checkpoints/efficientdet/coco/{m}.tar.gz
!tar zxf {m}.tar.gz
ckpt_path = os.path.join(os.getcwd(), m)
return ckpt_path
# Download checkpoint.
ckpt_path = download(MODEL)
print('Use model in {}'.format(ckpt_path))
Use model in /content/efficientdet-d0
Pretrained efficientdet 모델로 Inference 를 수행하기 위한 환경 설정
hparams_config.Config 객체를 통해 모델 환경 설정.
class INFER_CFG:
model_name = 'efficientdet-d0' # efficientdet 모델명
model_dir = '/content/efficientdet-d0' # pretrained checkpoint 파일이 있는 디렉토리
hparams = '' # csv 형식의 k=v 쌍 또는 yaml file
import numpy as np
from PIL import Image
import tensorflow as tf
import hparams_config
import inference
from tf2 import efficientdet_keras # keras 를 tf2로 변경
from PIL import Image
import cv2
# image는 4차원 array, Tensor 모두 가능.
imgs = [np.array(Image.open('/content/data/img01.png'))]
imgs = tf.convert_to_tensor(imgs, dtype=tf.uint8)
### 아래와 같이 numpy array도 모델에 입력되는 이미지 값으로 가능.
'''
img = cv2.cvtColor(cv2.imread('/content/data/img01.png'), cv2.COLOR_BGR2RGB)
imgs= img[np.newaxis, ...]
boxes, scores, classes, valid_len = model(imgs, training=False, post_mode='global')
'''
print()
import time
# Inference 수행하고 수행 시간을 측정.
start_time = time.time()
boxes, scores, classes, valid_len = model(imgs, training=False, post_mode='global')
print('elapsed time:', time.time() - start_time)
/content/automl/efficientdet/utils.py:255: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
for u in self.updates:
elapsed time: 7.936372518539429
Inference 반환 결과 살펴보고 API로 시각화 하기
inference model에 image tensor를 입력하여 반환된 결과는 모두 tensor이며, bounding box의 좌표, confidence score, class id 값, valid한 갯수가 반환됨.
config에 max_instances_per_image이 100으로 설정되었으므로 기본적으로 inference결과는 100개의 object들의 Detection 결과를 가지게 됨.
이들 중 valid한 갯수(valid_len)은 이들중 의미있는 object detection 갯수를 의미함.(0 부터 valid_len-1 까지의 index를 가진 array결과가 의미있는 detection 결과임)
for i, img in enumerate(imgs):
length = valid_len[i]
img = inference.visualize_image(
img,
boxes[i].numpy()[:length],
classes[i].numpy().astype(np.int)[:length],
scores[i].numpy()[:length],
label_map=config.label_map,
min_score_thresh=config.nms_configs.score_thresh,
max_boxes_to_draw=config.nms_configs.max_output_size)
output_image_path = os.path.join('/content/data_output', str(i) + '.jpg')
Image.fromarray(img).save(output_image_path)
print('writing annotated image to %s' % output_image_path)
writing annotated image to /content/data_output/0.jpg
Static Graph mode(Non eager mode)로 Inference 수행 성능 향상 시키기
@tf.function을 이용하여 static mode로 inference를 수행할 수 있도록 ExportModel 클래스 생성
inference 수행 시 ExportModel의 @tf.function이 적용된 메소드를 호출할 수 있도록 함.
import time
class ExportModel(tf.Module):
def __init__(self, model):
super().__init__()
self.model = model
@tf.function
def f(self, imgs):
#model(imgs, training=False, post_mode='global')
return self.model(imgs, training=False, post_mode='global')
export_model = ExportModel(model)
# p100에서 image 1920x1280일 경우 74ms, v100에서 image 512x512일 경우 24ms
start_time = time.time()
boxes, scores, classes, valid_len = export_model.f(imgs)
print('elapsed time:', time.time() - start_time)
/content/automl/efficientdet/utils.py:23: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
from tensorflow.python.tpu import tpu_function # pylint:disable=g-direct-tensorflow-import
/content/automl/efficientdet/utils.py:255: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
for u in self.updates:
elapsed time: 8.002159118652344
def get_detected_img(export_model, img_array, is_print=True):
# automl efficent은 반환 bbox 좌표값이 원본 이미지 좌표값으로 되어 있으므로 별도의 scaling작업 필요 없음.
'''
height = img_array.shape[0]
width = img_array.shape[1]
'''
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img_array.copy()
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# cv2로 만들어진 numpy image array를 tensor로 변환
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.uint8)[tf.newaxis, ...]
#img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)[tf.newaxis, ...]
# efficientdet 모델을 다운로드 한 뒤 inference 수행.
start_time = time.time()
# automl efficientdet 모델은 boxes, score, classes, num_detections를 각각 Tensor로 반환.
boxes, scores, classes, valid_len = export_model.f(img_tensor)
# Tensor값을 시각화를 위해 numpy 로 변환.
boxes = boxes.numpy()
scores = scores.numpy()
classes = classes.numpy()
valid_len = valid_len.numpy()
# detected 된 object들을 iteration 하면서 정보 추출. detect된 object의 갯수는 100개
for i in range(valid_len[0]):
# detection score를 iteration시 마다 높은 순으로 추출하고 SCORE_THRESHOLD보다 낮으면 loop 중단.
score = scores[0, i]
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
box = boxes[0, i]
''' **** 주의 ******
box는 ymin, xmin, ymax, xmax 순서로 되어 있음. 또한 원본 좌표값으로 되어 있음. '''
left = box[1]
top = box[0]
right = box[3]
bottom = box[2]
# class id 추출하고 class 명으로 매핑
class_id = classes[0, i]
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
if is_print:
print('Detection 수행시간:',round(time.time() - start_time, 2),"초")
return draw_img
import cv2
img_array = cv2.cvtColor(cv2.imread('/content/data/beatles01.jpg'), cv2.COLOR_BGR2RGB)
print(img_array.shape)
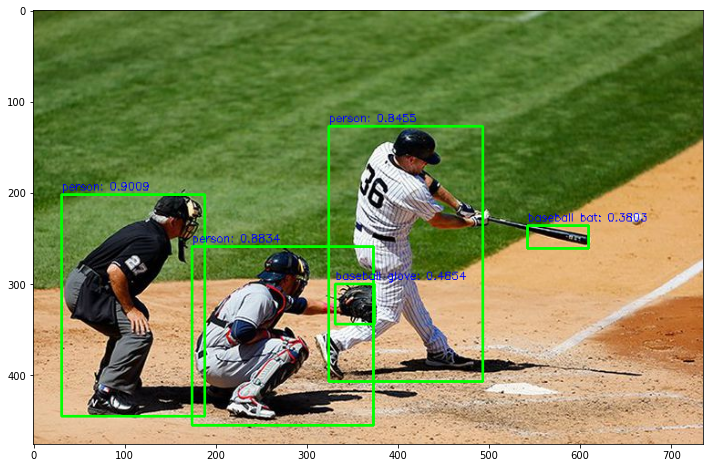
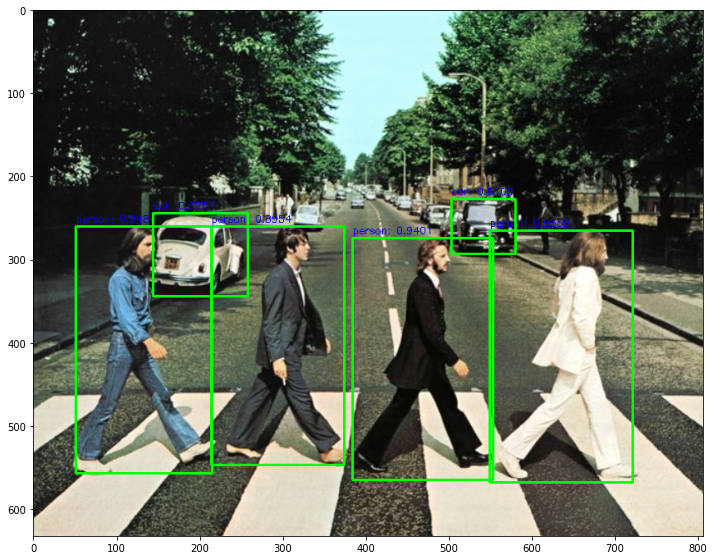
draw_img = get_detected_img(export_model, img_array, is_print=True)
plt.figure(figsize=(12, 12))
plt.imshow(draw_img)
(633, 806, 3)
/content/automl/efficientdet/utils.py:23: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
from tensorflow.python.tpu import tpu_function # pylint:disable=g-direct-tensorflow-import
/content/automl/efficientdet/utils.py:255: UserWarning: `layer.updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
for u in self.updates:
person: 0.9486
person: 0.9406
person: 0.9362
person: 0.8914
car: 0.6025
car: 0.5251
Detection 수행시간: 4.61 초
def get_detected_img_automl(model, img_array, score_threshold, object_show_count=100, is_print=True):
# automl efficent은 반환 bbox 좌표값이 원본 이미지 좌표값으로 되어 있으므로 별도의 scaling작업 필요 없음.
'''
height = img_array.shape[0]
width = img_array.shape[1]
'''
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img_array.copy()
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# cv2로 만들어진 numpy image array를 tensor로 변환
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.uint8)[tf.newaxis, ...]
#img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)[tf.newaxis, ...]
# efficientdet 모델을 다운로드 한 뒤 inference 수행.
start_time = time.time()
# automl efficientdet 모델은 boxes, score, classes, num_detections를 각각 Tensor로 반환.
boxes, scores, classes, num_detections = model(img_tensor)
# Tensor값을 시각화를 위해 numpy 로 변환.
boxes = boxes.numpy()
scores = scores.numpy()
classes = classes.numpy()
num_detections = num_detections.numpy()
# detected 된 object들을 iteration 하면서 정보 추출. detect된 object의 갯수는 100개
for i in range(num_detections[0]):
# detection score를 iteration시 마다 높은 순으로 추출하고 SCORE_THRESHOLD보다 낮으면 loop 중단.
score = scores[0, i]
if score < score_threshold:
break
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
box = boxes[0, i]
''' **** 주의 ******
box는 ymin, xmin, ymax, xmax 순서로 되어 있음. 또한 원본 좌표값으로 되어 있음. '''
left = box[1]
top = box[0]
right = box[3]
bottom = box[2]
# class id 추출하고 class 명으로 매핑
class_id = classes[0, i]
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
if is_print:
print('Detection 수행시간:',round(time.time() - start_time, 2),"초")
return draw_img
TF Hub에서 EfficientDet d0 Inference 모델 다운로드 후 Inference 수행.
원하는 모델명은 TF Hub에서 검색해서 hub.lod()로 다운로드 후 tensorflow로 사용 가능할 수 있도록 로딩됨
EfficientDet Tensorflow Object Detection API로 구현된 모델로 Download
로딩된 모델은 바로 원본 이미지로 Object Detection이 가능. 입력 값으로 numpy array, tensor 모두 가능하며 uint8로 구성 필요.
module_handle = "https://tfhub.dev/tensorflow/efficientdet/d0/1"
detector_model = hub.load(module_handle)
WARNING:absl:Importing a function (__inference___call___32344) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_97451) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_77595) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_103456) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_93843) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_107064) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_75975) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
def get_detector(module_handle="https://tfhub.dev/tensorflow/efficientdet/d0/1"):
detector = hub.load(module_handle)
return detector
detector_model = get_detector()
WARNING:absl:Importing a function (__inference___call___32344) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_97451) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_77595) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_103456) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_93843) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D0_layer_call_and_return_conditional_losses_107064) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_75975) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
import cv2
img_array = cv2.cvtColor(cv2.imread('/content/data/beatles01.jpg'), cv2.COLOR_BGR2RGB)
# scaling된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
height = img_array.shape[0]
width = img_array.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img_array.copy()
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# cv2로 만들어진 numpy image array를 tensor로 변환
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.uint8)[tf.newaxis, ...]
#img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)[tf.newaxis, ...]
# pretrained 모델을 다운로드 한 뒤 inference 수행.
result = detector_model(img_tensor)
# result 내부의 value를 numpy 로 변환.
result = {key:value.numpy() for key,value in result.items()}
SCORE_THRESHOLD = 0.3
OBJECT_DEFAULT_COUNT = 100
# detected 된 object들을 iteration 하면서 정보 추출. detect된 object의 갯수는 100개
for i in range(min(result['detection_scores'][0].shape[0], OBJECT_DEFAULT_COUNT)):
# detection score를 iteration시 마다 높은 순으로 추출하고 SCORE_THRESHOLD보다 낮으면 loop 중단.
score = result['detection_scores'][0, i]
if score < SCORE_THRESHOLD:
break
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
box = result['detection_boxes'][0, i]
''' **** 주의 ******
box는 ymin, xmin, ymax, xmax 순서로 되어 있음. '''
left = box[1] * width
top = box[0] * height
right = box[3] * width
bottom = box[2] * height
# class id 추출하고 class 명으로 매핑
class_id = result['detection_classes'][0, i]
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
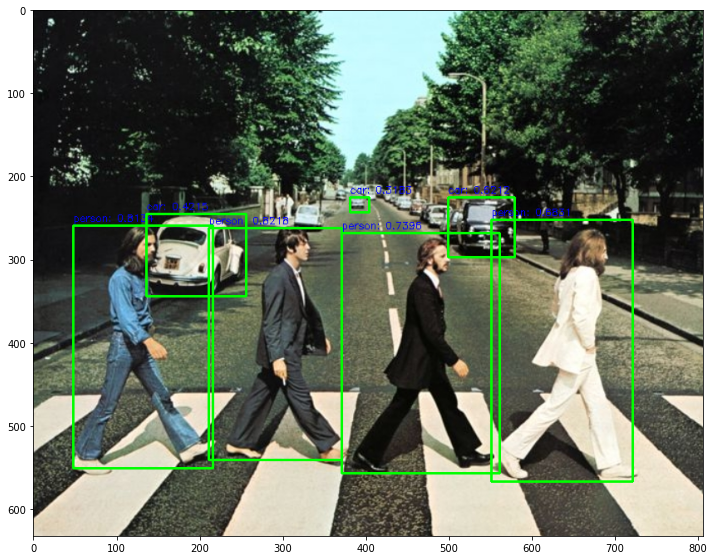
plt.figure(figsize=(12, 12))
plt.imshow(draw_img)
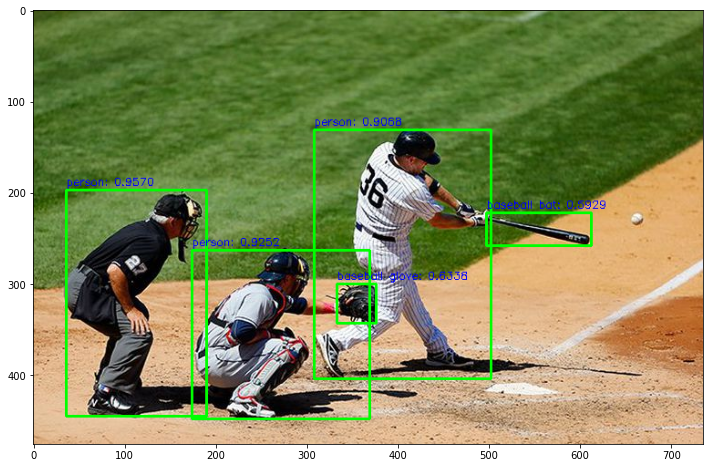
person: 0.9484
person: 0.9401
person: 0.9359
person: 0.8954
car: 0.6267
car: 0.5109
truck: 0.3303
car: 0.3149
import time
def get_detected_img(model, img_array, score_threshold, object_show_count=100, is_print=True):
# scaling된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
height = img_array.shape[0]
width = img_array.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img_array.copy()
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# cv2로 만들어진 numpy image array를 tensor로 변환
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.uint8)[tf.newaxis, ...]
#img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)[tf.newaxis, ...]
# efficientdet모델로 inference 수행.
start_time = time.time()
# inference 결과로 내부 원소가 Tensor이 Dict 반환
result = model(img_tensor)
# result 내부의 value를 numpy 로 변환.
result = {key:value.numpy() for key,value in result.items()}
# detected 된 object들을 iteration 하면서 정보 추출. detect된 object의 갯수는 100개
for i in range(min(result['detection_scores'][0].shape[0], object_show_count)):
# detection score를 iteration시 마다 높은 순으로 추출하고 SCORE_THRESHOLD보다 낮으면 loop 중단.
score = result['detection_scores'][0, i]
if score < score_threshold:
break
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
box = result['detection_boxes'][0, i]
''' **** 주의 ******
box는 ymin, xmin, ymax, xmax 순서로 되어 있음. '''
left = box[1] * width
top = box[0] * height
right = box[3] * width
bottom = box[2] * height
# class id 추출하고 class 명으로 매핑
class_id = result['detection_classes'][0, i]
caption = "{}: {:.4f}".format(labels_to_names[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
if is_print:
print('Detection 수행시간:',round(time.time() - start_time, 2),"초")
return draw_img
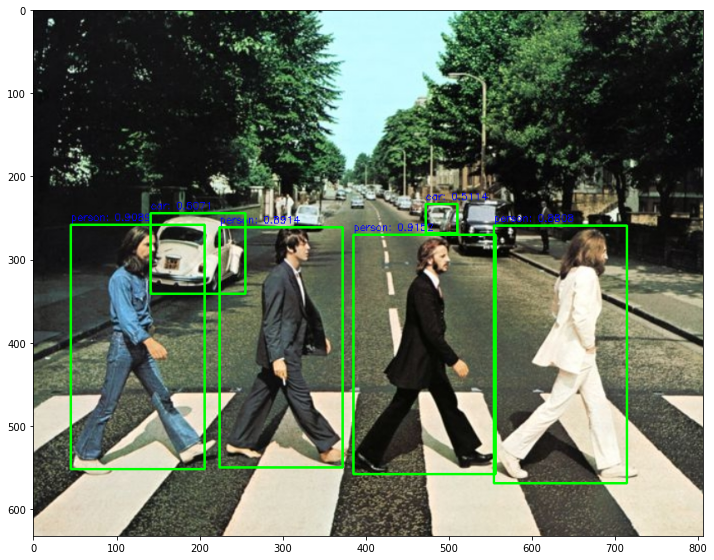
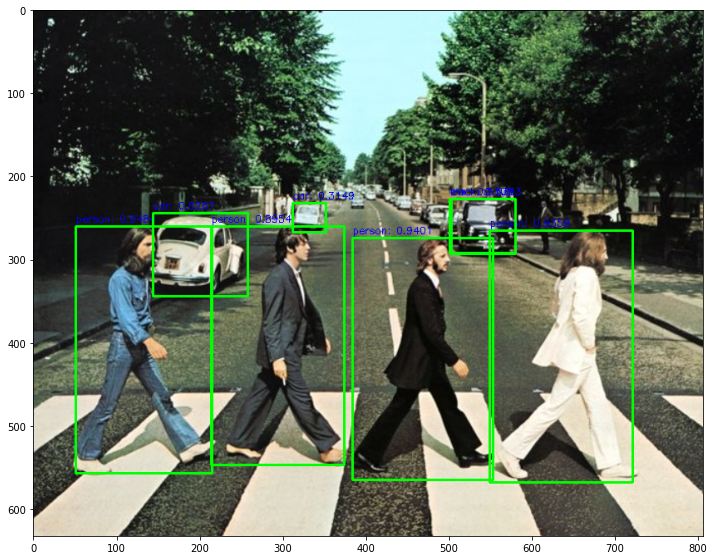
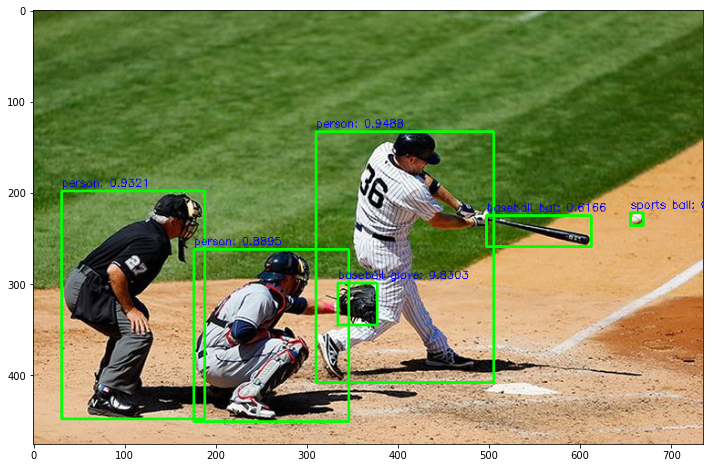
detector_model_d2 = get_detector('https://tfhub.dev/tensorflow/efficientdet/d2/1')
WARNING:absl:Importing a function (__inference_EfficientDet-D2_layer_call_and_return_conditional_losses_130857) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference___call___38449) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D2_layer_call_and_return_conditional_losses_145024) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_99017) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D2_layer_call_and_return_conditional_losses_139687) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_EfficientDet-D2_layer_call_and_return_conditional_losses_125520) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_bifpn_layer_call_and_return_conditional_losses_101605) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.