# 병합시, 두개의 데이터 프레임을 연결컬럼을 설정하기
# 연결컬럼을 key라고 한다,
# outer 방식
result3 = pd.merge(df1, df2, on='id', how='outer')
print(result3)
id stock_name value price name eps \
0 128940 한미약품 59385.666667 421000.0 NaN NaN
1 130960 CJ E&M 58540.666667 98900.0 CJ E&M 6301.333333
2 138250 엔에스쇼핑 14558.666667 13200.0 NaN NaN
3 139480 이마트 239230.833333 254500.0 이마트 18268.166667
4 142280 녹십자엠에스 468.833333 10200.0 NaN NaN
5 145990 삼양사 82750.000000 82000.0 삼양사 5741.000000
6 185750 종근당 40293.666667 100500.0 종근당 3990.333333
7 192400 쿠쿠홀딩스 179204.666667 177500.0 NaN NaN
8 199800 툴젠 -2514.333333 115400.0 NaN NaN
9 204210 모두투어리츠 3093.333333 3475.0 모두투어리츠 85.166667
10 136480 NaN NaN NaN 하림 274.166667
11 138040 NaN NaN NaN 메리츠금융지주 2122.333333
12 161390 NaN NaN NaN 한국타이어 5648.500000
13 181710 NaN NaN NaN NHN엔터테인먼트 2110.166667
14 207940 NaN NaN NaN 삼성바이오로직스 4644.166667
bps per pbr
0 NaN NaN NaN
1 54068.0 15.695091 1.829178
2 NaN NaN NaN
3 295780.0 13.931338 0.860437
4 NaN NaN NaN
5 108090.0 14.283226 0.758627
6 40684.0 25.185866 2.470259
7 NaN NaN NaN
8 NaN NaN NaN
9 5335.0 40.802348 0.651359
10 3551.0 11.489362 0.887074
11 14894.0 6.313806 0.899691
12 51341.0 7.453306 0.820007
13 78434.0 30.755864 0.827447
14 60099.0 89.790059 6.938551
print(result3.columns)
Index(['id', 'stock_name', 'value', 'price', 'name', 'eps', 'bps', 'per',
'pbr'],
dtype='object')
# 변합시 사용되는 키의 이름이 다른 경우
result4 = pd.merge(df1, df2, how='left', left_on='stock_name', right_on='name')
print(result4)
print(result4.columns)
id_x stock_name value price id_y name eps \
0 128940 한미약품 59385.666667 421000 NaN NaN NaN
1 130960 CJ E&M 58540.666667 98900 130960.0 CJ E&M 6301.333333
2 138250 엔에스쇼핑 14558.666667 13200 NaN NaN NaN
3 139480 이마트 239230.833333 254500 139480.0 이마트 18268.166667
4 142280 녹십자엠에스 468.833333 10200 NaN NaN NaN
5 145990 삼양사 82750.000000 82000 145990.0 삼양사 5741.000000
6 185750 종근당 40293.666667 100500 185750.0 종근당 3990.333333
7 192400 쿠쿠홀딩스 179204.666667 177500 NaN NaN NaN
8 199800 툴젠 -2514.333333 115400 NaN NaN NaN
9 204210 모두투어리츠 3093.333333 3475 204210.0 모두투어리츠 85.166667
bps per pbr
0 NaN NaN NaN
1 54068.0 15.695091 1.829178
2 NaN NaN NaN
3 295780.0 13.931338 0.860437
4 NaN NaN NaN
5 108090.0 14.283226 0.758627
6 40684.0 25.185866 2.470259
7 NaN NaN NaN
8 NaN NaN NaN
9 5335.0 40.802348 0.651359
Index(['id_x', 'stock_name', 'value', 'price', 'id_y', 'name', 'eps', 'bps',
'per', 'pbr'],
dtype='object')
# df2 데이터셋의 내용을 모두 조회되도록,
pd.set_option('display.max_columns', 10)
pd.set_option('display.max_colwidth', 20)
result5 = pd.merge(df1, df2, how = 'right', left_on = 'stock_name', right_on = 'name')
print(result5)
id_x stock_name value price id_y name \
0 130960.0 CJ E&M 58540.666667 98900.0 130960 CJ E&M
1 NaN NaN NaN NaN 136480 하림
2 NaN NaN NaN NaN 138040 메리츠금융지주
3 139480.0 이마트 239230.833333 254500.0 139480 이마트
4 145990.0 삼양사 82750.000000 82000.0 145990 삼양사
5 NaN NaN NaN NaN 161390 한국타이어
6 NaN NaN NaN NaN 181710 NHN엔터테인먼트
7 185750.0 종근당 40293.666667 100500.0 185750 종근당
8 204210.0 모두투어리츠 3093.333333 3475.0 204210 모두투어리츠
9 NaN NaN NaN NaN 207940 삼성바이오로직스
eps bps per pbr
0 6301.333333 54068 15.695091 1.829178
1 274.166667 3551 11.489362 0.887074
2 2122.333333 14894 6.313806 0.899691
3 18268.166667 295780 13.931338 0.860437
4 5741.000000 108090 14.283226 0.758627
5 5648.500000 51341 7.453306 0.820007
6 2110.166667 78434 30.755864 0.827447
7 3990.333333 40684 25.185866 2.470259
8 85.166667 5335 40.802348 0.651359
9 4644.166667 60099 89.790059 6.938551
# embarktown 컬럼의 결측값은 컬럼의 값 중 빈도수가 가장 많은 값으로 치환하기
# most_freq = df['embark_town'].value_counts(dropna = True)
most_freq = df['embark_town'].value_counts(dropna = True).idxmax() # 가장 많은 것 출력
print(most_freq)
# Southampton
# 인구구조 알고싶은 동 입력
import numpy as np
import csv
import matplotlib.pyplot as plt
f = open('./age1_utf.csv',encoding="utf8")
# 스트림 : 데이터의 이동 통로
# 한번 읽으면 사라짐, 그래서 문제가 될지도, 또 쓰고 싶으면, 별도로 저장해야 함.
data = csv.reader(f)
next(data) # 헤더 제거, 첫줄 읽어버리기
name = input('지역의 이름(읍면동 단위) 입력')
for row in data :
if name in row[0] :
name = row[0]
print(name)
row = list(map((lambda x : x.replace(',', '')), row)) # 문자열 제거 숫자내부 m 제거해서 정수값 변경가능
home = np.array(row[3:], dtype = int)
plt.style.use('ggplot')
plt.figure(figsize = (10, 5), dpi = 100)
plt.rc('font', family = 'Malgun Gothic')
plt.title(name + ' 지역의 인구 구조')
plt.plot(home)
plt.show()
# 지역의 이름(읍면동 단위) 입력강남구
# 서울특별시 강남구 (1168000000)
가장 비슷한 인구구조를 가진 그래플와 지역 출력
# 가장 비슷한 인구구조를 가진 그래플와 지역 출력
import numpy as np
import csv
import matplotlib.pyplot as plt
import re
f = open('./age1_utf.csv',encoding="utf8")
# 스트림 : 데이터의 이동 통로
# 한번 읽으면 사라짐, 그래서 문제가 될지도, 또 쓰고 싶으면, 별도로 저장해야 함.
data = csv.reader(f)
next(data) # 헤더 제거, 첫줄 읽어버리기
# name = input('지역의 이름(읍면동 단위) 입력')
data =list(data)
name = '상록'
mn = 1 # 파라미터 초기화, 최소차이 저장
result_name = ''
result = 0
for row in data :
if name in row[0]:
row = list(map((lambda x : x.replace(',', '')), row)) # 문자열 제거 숫자내부 m 제거해서 정수값 변경가능
home = np.array(row[3:], dtype =int) / int(row[2])
for row in data :
row = list(map((lambda x : x.replace(',', '')), row))
away = np.array(row[3:], dtype =int) / int(row[2])
s = np.sum((home - away)**2) # 차이가 마이너스가 될수도, 절대값 개념
if s < mn and name not in row[0] :
mn = s # mn 저장
result_name = row[0]
result = away
plt.style.use('ggplot')
plt.figure(figsize = (10, 5), dpi = 100)
plt.rc('font', family = 'Malgun Gothic')
plt.title(name + ' 지역의 인구 구조')
plt.plot(home, label = name) # 선택지역
plt.plot(result, label = result_name) # 가장 비슷한 지역
plt.legend()
plt.show()
import seaborn as sns
print(sns.get_dataset_names())
tips = sns.load_dataset('tips')
print(tips.head())
# ['anagrams', 'anscombe', 'attention', 'brain_
['anagrams', 'anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights', 'fmri', 'gammas', 'geyser', 'iris', 'mpg', 'penguins', 'planets', 'tips', 'titanic']
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
print(titanic.head())
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
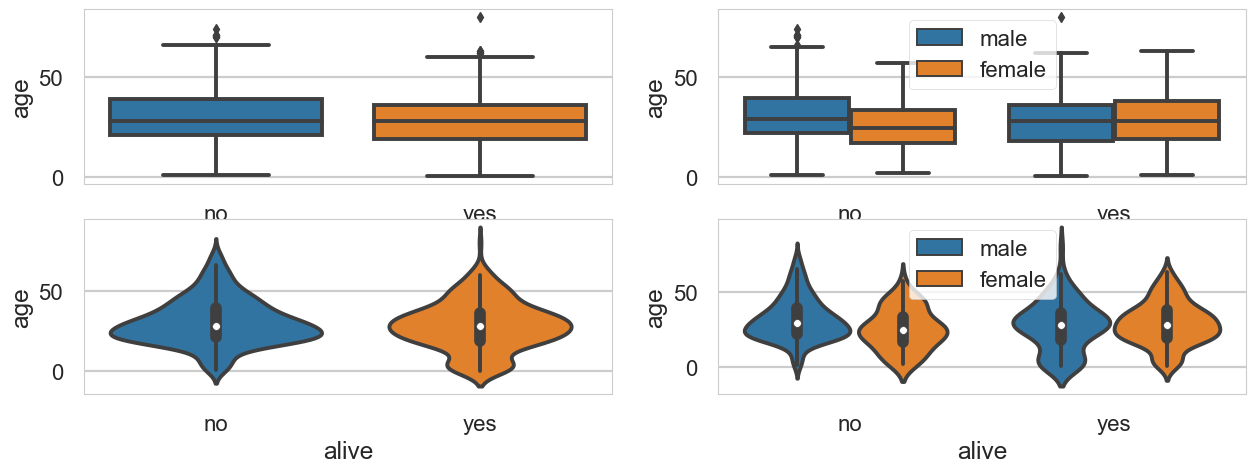
sns.set_style('darkgrid')
# darkgrid, whitegrid, dark, white, ticks 등
fig = plt.figure(figsize = (15, 5)) # fig 크기
ax1 = fig.add_subplot(1,2,1) # 위
ax2 = fig.add_subplot(1,2,2) # 아래
# 선형회귀, 산점도
sns.regplot(x='age',
y='fare',
data = titanic,
ax = ax1)
sns.regplot(x='age',
y='fare',
data = titanic,
ax = ax2,
fit_reg=False)
plt.show()
히스토그램
distplot 두개 다
kedplot 선형 분포
histplot 막대 분포
fig = plt.figure(figsize = (15, 5)) # fig 크기
ax1 = fig.add_subplot(1,3,1) # 위
ax2 = fig.add_subplot(1,3,2) # 아래
ax3 = fig.add_subplot(1,3,3) # 아래
# distplot : 합친 것
sns.distplot(titanic['fare'], ax=ax1)
# kdeplot : 커널 밀도
sns.kdeplot(x='fare', data =titanic, ax=ax2)
# sns.distplot(titanic['fare'], hist = False, ax=ax1)
# histplot : 히스토그램
sns.histplot(x='fare', data =titanic, ax=ax3)
# sns.distplot(titanic['fare'], kde = False, ax=ax1)
ax1.set_title('titanic fare - distplot')
ax2.set_title('titanic fare - kdeplot')
ax3.set_title('titanic fare - histplot')
plt.show()
히트맵
sns.set_style('darkgrid')
# 피벗테이블로 범주현 변수를 각각 행, 열로 재구분하여 정리
table = titanic.pivot_table(index = ['sex'], columns = ['class'], aggfunc='size')
# 성별이 인덱스, 컬럼이 탑승등급, aggdfunc 건수 표시
# 피벗테이블 : 범위를 가지는 값 별로 건수로 출력되는 테이블
# 히트맵 그리기
sns.heatmap(table, # 데이터 프레임
annot = True, fmt = 'd', # 데이터 값 표시, 정수형 포맷
cmap='YlGnBu', # 컬러맵
linewidth=5, # 구분선
cbar=True) # 컬러 바 표시 여부
plt.show()
# 산점도
sns.set_style('whitegrid')
fig = plt.figure(figsize = (15,5))
ax1 = fig.add_subplot(1,2,1) # 위
ax2 = fig.add_subplot(1,2,2) # 아래
# 이산형 변수 의 분포 데이터 분산 미고려
sns.stripplot(x = 'class',
y = 'age',
data = titanic,
ax = ax1)
# 이산형 변수의 분포 : 데이터 분산 고려, 중복 없음, 겹치지 않게 옆으로 밀어냄
sns.swarmplot(x = 'class',
y = 'age',
data = titanic,
ax = ax2)
# 차트제목 표시
ax1.set_title('Strip Plot')
ax2.set_title('Swarm Plot')
plt.show()
# 산점도
sns.set_style('whitegrid')
fig = plt.figure(figsize = (15,5))
ax1 = fig.add_subplot(1,2,1) # 위
ax2 = fig.add_subplot(1,2,2) # 아래
# 이산형 변수 의 분포 데이터 분산 미고려
sns.stripplot(x = 'class',
y = 'age',
data = titanic,
hue = 'sex', # 데이터 구분 컬럼 // 동일 배치에 색깔로 구분
ax = ax1)
# 이산형 변수의 분포 : 데이터 분산 고려, 중복 없음, 겹치지 않게 옆으로 밀어냄
sns.swarmplot(x = 'class',
y = 'age',
data = titanic,
hue = 'sex',
ax = ax2)
# 차트제목 표시
ax1.set_title('Strip Plot')
ax2.set_title('Swarm Plot')
ax1.legend(loc = 'upper right')
ax2.legend(loc = 'upper right')
plt.show()
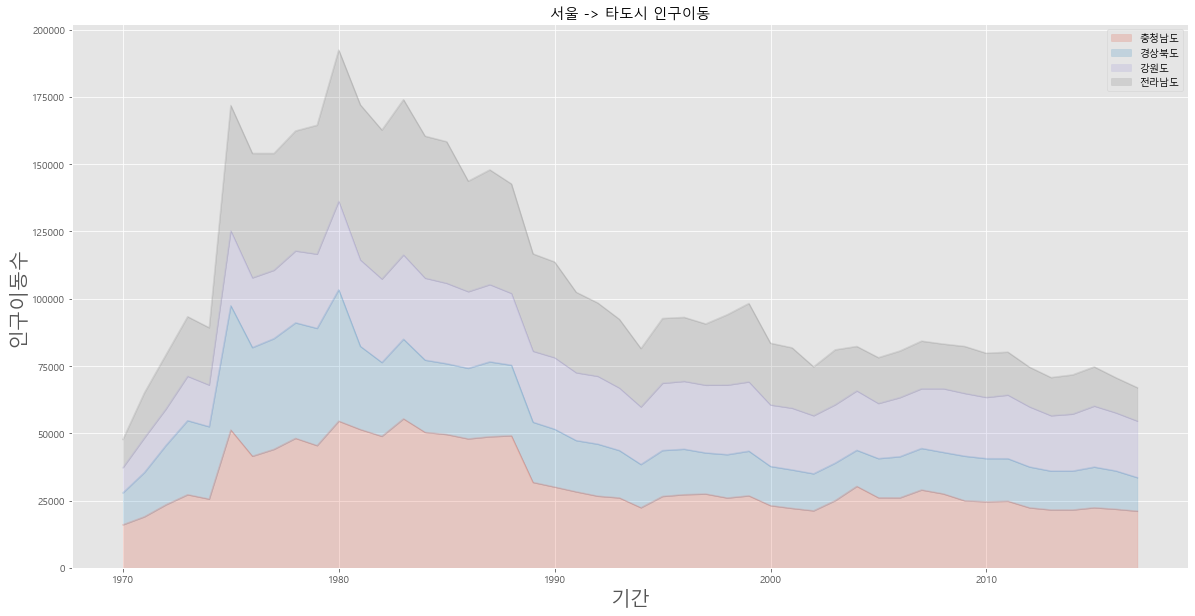
# 면적그래프 area 선그래프 작성시 선과 x축 공간 을 색으로 표시
sr4 = sr3.T
plt.style.use('ggplot')
# T 된 년도가 인덱스
sr4.index = sr4.index.map(int)
# area 그래프 작성 // 메모리 구조 스택 LIFO T 쌓여진 형태 // F 겹쳐진 혀애
sr4.plot(kind = 'area', stacked = True, alpha= 0.2, figsize = (20,10)) # alpha 투명도
plt.title('서울 -> 타도시 인구이동')
plt.ylabel('인구이동수',size = 20)
plt.xlabel('기간',size = 20)
plt.legend(loc='best')
plt.show()
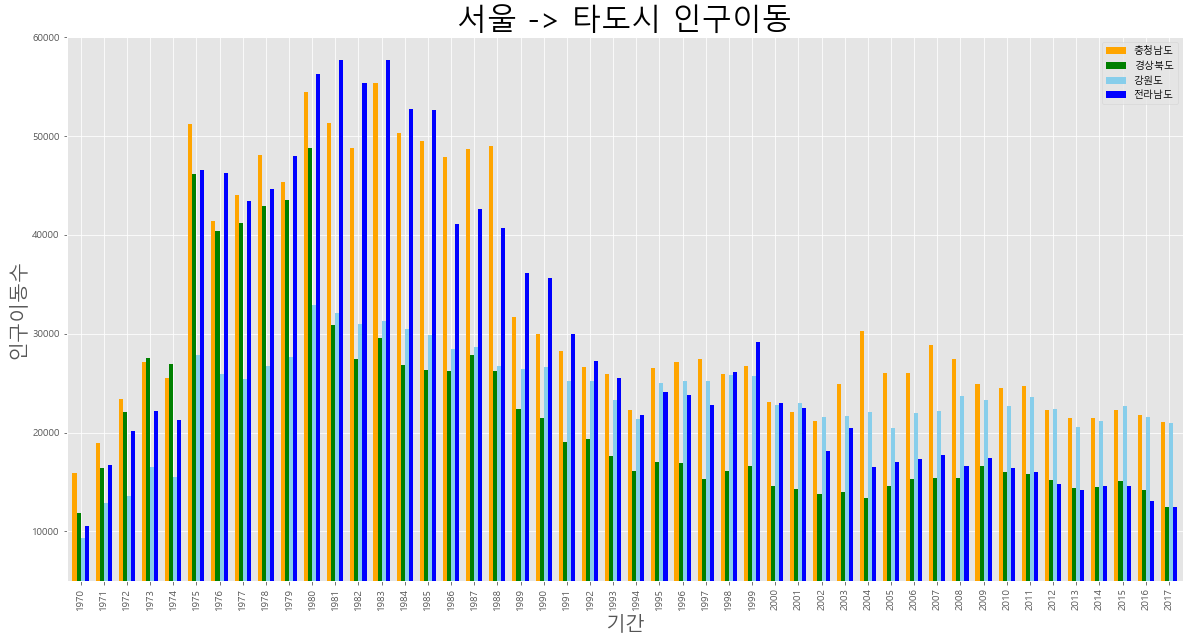
# 막대그래프
plt.style.use('ggplot')
# area 그래프 작성 // 메모리 구조 스택 LIFO T 쌓여진 형태 // F 겹쳐진 혀애
sr4.plot(kind = 'bar', figsize = (20,10), width = 0.7, color=['orange','green','skyblue','blue']) # alpha 투명도
plt.title('서울 -> 타도시 인구이동', size= 30)
plt.ylabel('인구이동수',size = 20)
plt.xlabel('기간',size = 20)
plt.ylim(5000,60000)
plt.legend(loc='best')
plt.show()
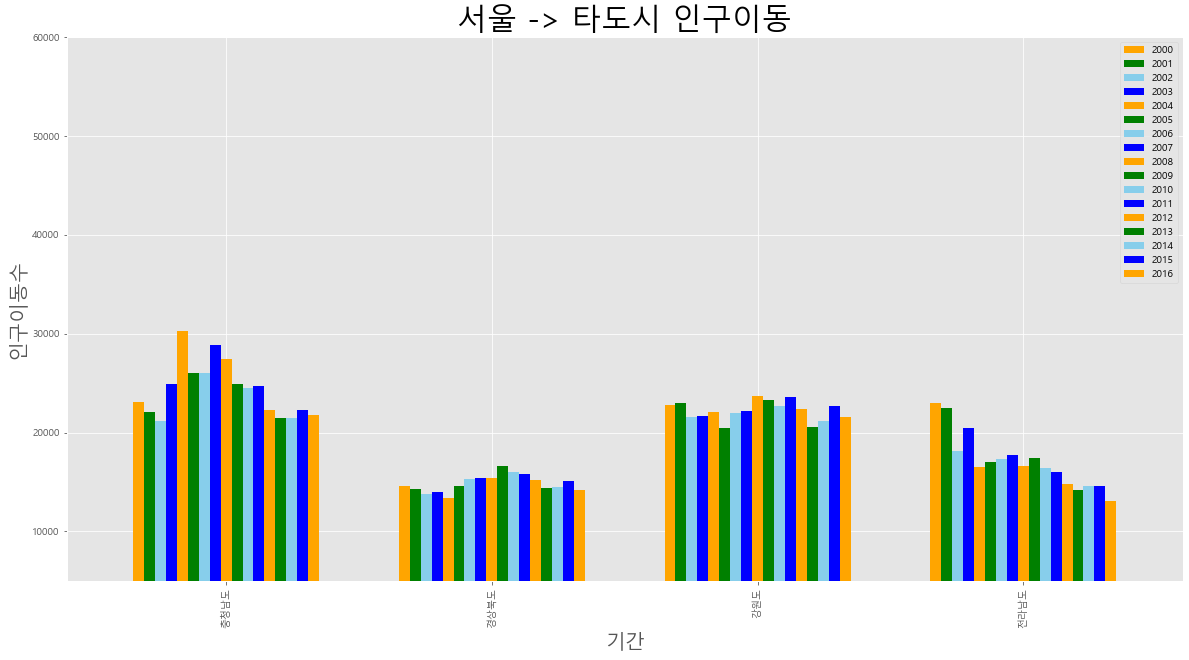
# 그림판 여러개 그래프 작성
col_years = list(map(str, range(2000, 2017))) # 문자열 리스트
sr5 = df_seoul.loc[['충청남도','경상북도', '강원도', '전라남도'], col_years]
print(sr3)
전입지
충청남도 23083
경상북도 14576
강원도 22832
전라남도 22969
Name: 2000, dtype: object
# 막대그래프
plt.style.use('ggplot')
# area 그래프 작성 // 메모리 구조 스택 LIFO T 쌓여진 형태 // F 겹쳐진 혀애
sr5.plot(kind = 'bar', figsize = (20,10), width = 0.7, color=['orange','green','skyblue','blue']) # alpha 투명도
plt.title('서울 -> 타도시 인구이동', size= 30)
plt.ylabel('인구이동수',size = 20)
plt.xlabel('기간',size = 20)
plt.ylim(5000,60000)
plt.legend(loc='best')
plt.show()
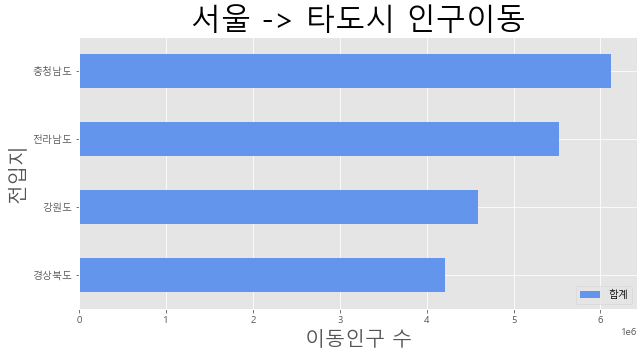
#가로 막대그래프
# print(sr3.sum(axis=1))
sr3['합계'] = sr3.sum(axis=1)
print(sr3['합계'])
# 합계 내림차순
sr3_tot = sr3[['합계']].sort_values(by='합계', ascending=True)
print(sr3_tot)
전입지
충청남도 6117092.0
경상북도 4208700.0
강원도 4585100.0
전라남도 5526628.0
Name: 합계, dtype: float64
합계
전입지
경상북도 4208700.0
강원도 4585100.0
전라남도 5526628.0
충청남도 6117092.0
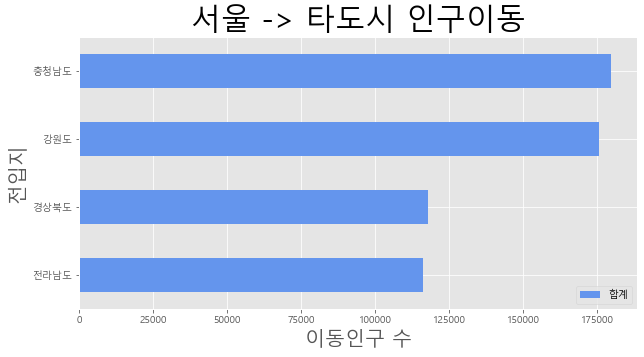
# 그림판 여러개 그래프 작성
col_years = list(map(str, range(2010, 2018))) # 문자열 리스트
sr6 = df_seoul.loc[['충청남도','경상북도', '강원도', '전라남도'], col_years]
sr6['합계'] = sr6.sum(axis=1)
# print(sr6[['합계']]) 데이터 프레임 여러개 중에 한개
# print(sr6['합계']) 시리즈 한열
# 합계 내림차순
sr6_tot = sr6[['합계']].sort_values(by='합계', ascending=True)
print(sr6_tot)
전입지
충청남도 179533.0
경상북도 117740.0
강원도 175731.0
전라남도 116035.0
Name: 합계, dtype: float64
합계
전입지
전라남도 116035.0
경상북도 117740.0
강원도 175731.0
충청남도 179533.0