import pandas as pd
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
# ratings_noh.csv 파일로 unload 시 index 와 header를 모두 제거한 새로운 파일 생성.
ratings.to_csv('./ml-latest-small/ratings_noh.csv', index=False, header=False)
Reader클래스로 파일의 포맷팅 지정하고 Dataset의 load_from_file()을 이용하여 데이터셋 로딩
학습과 테스트 데이터 세트로 분할하고 SVD로 학습후 테스트데이터 평점 예측 후 RMSE평가
trainset, testset = train_test_split(data, test_size=.25, random_state=0)
# 수행시마다 동일한 결과 도출을 위해 random_state 설정
algo = SVD(n_factors=50, random_state=0)
# 학습 데이터 세트로 학습 후 테스트 데이터 세트로 평점 예측 후 RMSE 평가
algo.fit(trainset)
predictions = algo.test( testset )
accuracy.rmse(predictions)
RMSE: 0.8682
0.8681952927143516
판다스 DataFrame기반에서 동일하게 재 수행
import pandas as pd
from surprise import Reader, Dataset
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
reader = Reader(rating_scale=(0.5, 5.0))
# ratings DataFrame 에서 컬럼은 사용자 아이디, 아이템 아이디, 평점 순서를 지켜야 합니다.
data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
trainset, testset = train_test_split(data, test_size=.25, random_state=0)
algo = SVD(n_factors=50, random_state=0)
algo.fit(trainset)
predictions = algo.test( testset )
accuracy.rmse(predictions)
RMSE: 0.8682
0.8681952927143516
교차 검증(Cross Validation)과 하이퍼 파라미터 튜닝
cross_validate()를 이용한 교차 검증
from surprise.model_selection import cross_validate
# Pandas DataFrame에서 Surprise Dataset으로 데이터 로딩
ratings = pd.read_csv('./ml-latest-small/ratings.csv') # reading data in pandas df
reader = Reader(rating_scale=(0.5, 5.0))
data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
algo = SVD(random_state=0)
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
Evaluating RMSE, MAE of algorithm SVD on 5 split(s).
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Mean Std
RMSE (testset) 0.8754 0.8814 0.8744 0.8721 0.8688 0.8744 0.0042
MAE (testset) 0.6729 0.6750 0.6708 0.6693 0.6700 0.6716 0.0021
Fit time 3.07 3.02 3.00 3.00 3.03 3.02 0.03
Test time 0.08 0.08 0.13 0.08 0.08 0.09 0.02
{'test_rmse': array([0.87544159, 0.88138787, 0.87435511, 0.87208076, 0.86879243]),
'test_mae': array([0.67288462, 0.67500158, 0.67084065, 0.66932369, 0.67001214]),
'fit_time': (3.0681252479553223,
3.0193707942962646,
2.999852418899536,
2.9955246448516846,
3.032907009124756),
'test_time': (0.07512664794921875,
0.07816100120544434,
0.12555646896362305,
0.07763862609863281,
0.07547497749328613)}
GridSearchCV 이용
from surprise.model_selection import GridSearchCV
# 최적화할 파라미터들을 딕셔너리 형태로 지정.
param_grid = {'n_epochs': [20, 40, 60], 'n_factors': [50, 100, 200] }
# CV를 3개 폴드 세트로 지정, 성능 평가는 rmse, mse 로 수행 하도록 GridSearchCV 구성
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)
gs.fit(data)
# 최고 RMSE Evaluation 점수와 그때의 하이퍼 파라미터
print(gs.best_score['rmse'])
print(gs.best_params['rmse'])
0.8760298595393691
{'n_epochs': 20, 'n_factors': 50}
Surprise 를 이용한 개인화 영화 추천 시스템 구축
SVD 학습은 TrainSet 클래스를 이용해야 함
# 아래 코드는 train_test_split( )으로 분리되지 않는 Dataset에 fit( )을 호출하여 오류를 발생합니다.
data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
algo = SVD(n_factors=50, random_state=0)
algo.fit(data)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-30-33c08dace4bd> in <module>
2 data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
3 algo = SVD(n_factors=50, random_state=0)
----> 4 algo.fit(data)
~\anaconda3\lib\site-packages\surprise\prediction_algorithms\matrix_factorization.pyx in surprise.prediction_algorithms.matrix_factorization.SVD.fit()
~\anaconda3\lib\site-packages\surprise\prediction_algorithms\matrix_factorization.pyx in surprise.prediction_algorithms.matrix_factorization.SVD.sgd()
AttributeError: 'DatasetAutoFolds' object has no attribute 'global_mean'
DatasetAutoFolds를 이용한 전체 데이터를 TrainSet클래스 변환
from surprise.dataset import DatasetAutoFolds
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5))
# DatasetAutoFolds 클래스를 ratings_noh.csv 파일 기반으로 생성.
data_folds = DatasetAutoFolds(ratings_file='./ml-latest-small/ratings_noh.csv', reader=reader)
#전체 데이터를 학습데이터로 생성함.
trainset = data_folds.build_full_trainset()
# 영화에 대한 상세 속성 정보 DataFrame로딩
movies = pd.read_csv('./ml-latest-small/movies.csv')
# userId=9 의 movieId 데이터 추출하여 movieId=42 데이터가 있는지 확인.
movieIds = ratings[ratings['userId']==9]['movieId']
if movieIds[movieIds==42].count() == 0:
print('사용자 아이디 9는 영화 아이디 42의 평점 없음')
print(movies[movies['movieId']==42])
사용자 아이디 9는 영화 아이디 42의 평점 없음
movieId title genres
38 42 Dead Presidents (1995) Action|Crime|Drama
def get_unseen_surprise(ratings, movies, userId):
#입력값으로 들어온 userId에 해당하는 사용자가 평점을 매긴 모든 영화를 리스트로 생성
seen_movies = ratings[ratings['userId']== userId]['movieId'].tolist()
# 모든 영화들의 movieId를 리스트로 생성.
total_movies = movies['movieId'].tolist()
# 모든 영화들의 movieId중 이미 평점을 매긴 영화의 movieId를 제외하여 리스트로 생성
unseen_movies= [movie for movie in total_movies if movie not in seen_movies]
print('평점 매긴 영화수:',len(seen_movies), '추천대상 영화수:',len(unseen_movies), \
'전체 영화수:',len(total_movies))
return unseen_movies
unseen_movies = get_unseen_surprise(ratings, movies, 9)
평점 매긴 영화수: 46 추천대상 영화수: 9696 전체 영화수: 9742
def recomm_movie_by_surprise(algo, userId, unseen_movies, top_n=10):
# 알고리즘 객체의 predict() 메서드를 평점이 없는 영화에 반복 수행한 후 결과를 list 객체로 저장
predictions = [algo.predict(str(userId), str(movieId)) for movieId in unseen_movies]
# predictions list 객체는 surprise의 Predictions 객체를 원소로 가지고 있음.
# [Prediction(uid='9', iid='1', est=3.69), Prediction(uid='9', iid='2', est=2.98),,,,]
# 이를 est 값으로 정렬하기 위해서 아래의 sortkey_est 함수를 정의함.
# sortkey_est 함수는 list 객체의 sort() 함수의 키 값으로 사용되어 정렬 수행.
def sortkey_est(pred):
return pred.est
# sortkey_est( ) 반환값의 내림 차순으로 정렬 수행하고 top_n개의 최상위 값 추출.
predictions.sort(key=sortkey_est, reverse=True)
top_predictions= predictions[:top_n]
# top_n으로 추출된 영화의 정보 추출. 영화 아이디, 추천 예상 평점, 제목 추출
top_movie_ids = [ int(pred.iid) for pred in top_predictions]
top_movie_rating = [ pred.est for pred in top_predictions]
top_movie_titles = movies[movies.movieId.isin(top_movie_ids)]['title']
top_movie_preds = [ (id, title, rating) for id, title, rating in zip(top_movie_ids, top_movie_titles, top_movie_rating)]
return top_movie_preds
unseen_movies = get_unseen_surprise(ratings, movies, 9)
top_movie_preds = recomm_movie_by_surprise(algo, 9, unseen_movies, top_n=10)
print('##### Top-10 추천 영화 리스트 #####')
for top_movie in top_movie_preds:
print(top_movie[1], ":", top_movie[2])
평점 매긴 영화수: 46 추천대상 영화수: 9696 전체 영화수: 9742
##### Top-10 추천 영화 리스트 #####
Usual Suspects, The (1995) : 4.306302135700814
Star Wars: Episode IV - A New Hope (1977) : 4.281663842987387
Pulp Fiction (1994) : 4.278152632122759
Silence of the Lambs, The (1991) : 4.226073566460876
Godfather, The (1972) : 4.1918097904381995
Streetcar Named Desire, A (1951) : 4.154746591122658
Star Wars: Episode V - The Empire Strikes Back (1980) : 4.122016128534504
Star Wars: Episode VI - Return of the Jedi (1983) : 4.108009609093436
Goodfellas (1990) : 4.083464936588478
Glory (1989) : 4.07887165526957
실제 행렬에서 널이 아닌 값의 위치에 있는 값만 예측 행렬의 값과 비교하여 RMSE값을 계산하고 반환
from sklearn.metrics import mean_squared_error
def get_rmse(R, P, Q, non_zeros):
error = 0
# 두개의 분해된 행렬 P와 Q.T의 내적으로 예측 R 행렬 생성
full_pred_matrix = np.dot(P, Q.T)
# 실제 R 행렬에서 널이 아닌 값의 위치 인덱스 추출하여 실제 R 행렬과 예측 행렬의 RMSE 추출
x_non_zero_ind = [non_zero[0] for non_zero in non_zeros]
y_non_zero_ind = [non_zero[1] for non_zero in non_zeros]
R_non_zeros = R[x_non_zero_ind, y_non_zero_ind]
full_pred_matrix_non_zeros = full_pred_matrix[x_non_zero_ind, y_non_zero_ind]
mse = mean_squared_error(R_non_zeros, full_pred_matrix_non_zeros)
rmse = np.sqrt(mse)
return rmse
경사하강법에 기반하여 P와 Q의 원소들을 업데이트 수행
# R > 0 인 행 위치, 열 위치, 값을 non_zeros 리스트에 저장.
non_zeros = [ (i, j, R[i,j]) for i in range(num_users) for j in range(num_items) if R[i,j] > 0 ]
# 아래 식과 똑같은 식임
# non_zeroes=[]
# for j in range(num_items) :
# for i in range(num_users):
# if R[i, j] > 0:
# non_zeros
steps=1000
learning_rate=0.01
r_lambda=0.01
# SGD 기법으로 P와 Q 매트릭스를 계속 업데이트.
for step in range(steps):
for i, j, r in non_zeros:
# 실제 값과 예측 값의 차이인 오류 값 구함
eij = r - np.dot(P[i, :], Q[j, :].T)
# Regularization을 반영한 SGD 업데이트 공식 적용
P[i,:] = P[i,:] + learning_rate*(eij * Q[j, :] - r_lambda*P[i,:])
Q[j,:] = Q[j,:] + learning_rate*(eij * P[i, :] - r_lambda*Q[j,:])
rmse = get_rmse(R, P, Q, non_zeros)
if (step % 50) == 0 :
print("### iteration step : ", step," rmse : ", rmse)
# rnse가 계속 줄어드는 결과가 나옴
### iteration step : 0 rmse : 3.2388050277987723
### iteration step : 50 rmse : 0.4876723101369648
### iteration step : 100 rmse : 0.1564340384819247
### iteration step : 150 rmse : 0.07455141311978046
### iteration step : 200 rmse : 0.04325226798579314
### iteration step : 250 rmse : 0.029248328780878973
### iteration step : 300 rmse : 0.022621116143829466
### iteration step : 350 rmse : 0.019493636196525135
### iteration step : 400 rmse : 0.018022719092132704
### iteration step : 450 rmse : 0.01731968595344266
### iteration step : 500 rmse : 0.016973657887570753
### iteration step : 550 rmse : 0.016796804595895633
### iteration step : 600 rmse : 0.01670132290188466
### iteration step : 650 rmse : 0.01664473691247669
### iteration step : 700 rmse : 0.016605910068210026
### iteration step : 750 rmse : 0.016574200475705
### iteration step : 800 rmse : 0.01654431582921597
### iteration step : 850 rmse : 0.01651375177473524
### iteration step : 900 rmse : 0.01648146573819501
### iteration step : 950 rmse : 0.016447171683479155
사용자아이템평점 행렬 속 잠재요인 추출 .. svd 6장참고경사하강법 기반의 행렬 분해 함수 생성
def matrix_factorization(R, K, steps=200, learning_rate=0.01, r_lambda = 0.01):
num_users, num_items = R.shape
# P와 Q 매트릭스의 크기를 지정하고 정규분포를 가진 랜덤한 값으로 입력합니다.
np.random.seed(1)
P = np.random.normal(scale=1./K, size=(num_users, K))
Q = np.random.normal(scale=1./K, size=(num_items, K))
break_count = 0
# R > 0 인 행 위치, 열 위치, 값을 non_zeros 리스트 객체에 저장.
non_zeros = [ (i, j, R[i,j]) for i in range(num_users) for j in range(num_items) if R[i,j] > 0 ]
# SGD기법으로 P와 Q 매트릭스를 계속 업데이트.
for step in range(steps):
for i, j, r in non_zeros:
# 실제 값과 예측 값의 차이인 오류 값 구함
eij = r - np.dot(P[i, :], Q[j, :].T)
# Regularization을 반영한 SGD 업데이트 공식 적용
P[i,:] = P[i,:] + learning_rate*(eij * Q[j, :] - r_lambda*P[i,:])
Q[j,:] = Q[j,:] + learning_rate*(eij * P[i, :] - r_lambda*Q[j,:])
rmse = get_rmse(R, P, Q, non_zeros)
if (step % 10) == 0 :
print("### iteration step : ", step," rmse : ", rmse)
return P, Q
import pandas as pd
import numpy as np
movies = pd.read_csv('./ml-latest-small/movies.csv')
ratings = pd.read_csv('./ml-lat est-small/ratings.csv')
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
ratings_pred_matrix = pd.DataFrame(data=pred_matrix, index= ratings_matrix.index,
columns = ratings_matrix.columns)
ratings_pred_matrix.head(3)
title '71 (2014) 'Hellboy': The Seeds of Creation (2004) 'Round Midnight (1986) 'Salem's Lot (2004) 'Til There Was You (1997) 'Tis the Season for Love (2015) 'burbs, The (1989) 'night Mother (1986) (500) Days of Summer (2009) *batteries not included (1987) ... Zulu (2013) [REC] (2007) [REC]² (2009) [REC]³ 3 Génesis (2012) anohana: The Flower We Saw That Day - The Movie (2013) eXistenZ (1999) xXx (2002) xXx: State of the Union (2005) ¡Three Amigos! (1986) À nous la liberté (Freedom for Us) (1931)
userId
1 3.055084 4.092018 3.564130 4.502167 3.981215 1.271694 3.603274 2.333266 5.091749 3.972454 ... 1.402608 4.208382 3.705957 2.720514 2.787331 3.475076 3.253458 2.161087 4.010495 0.859474
2 3.170119 3.657992 3.308707 4.166521 4.311890 1.275469 4.237972 1.900366 3.392859 3.647421 ... 0.973811 3.528264 3.361532 2.672535 2.404456 4.232789 2.911602 1.634576 4.135735 0.725684
3 2.307073 1.658853 1.443538 2.208859 2.229486 0.780760 1.997043 0.924908 2.970700 2.551446 ... 0.520354 1.709494 2.281596 1.782833 1.635173 1.323276 2.887580 1.042618 2.293890 0.396941
3 rows × 9719 columns
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 잠재요인 기반 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies
pred_score
title
Rear Window (1954) 5.704612
South Park: Bigger, Longer and Uncut (1999) 5.451100
Rounders (1998) 5.298393
Blade Runner (1982) 5.244951
Roger & Me (1989) 5.191962
Gattaca (1997) 5.183179
Ben-Hur (1959) 5.130463
Rosencrantz and Guildenstern Are Dead (1990) 5.087375
Big Lebowski, The (1998) 5.038690
Star Wars: Episode V - The Empire Strikes Back (1980) 4.989601
import pandas as pd
import numpy as np
movies = pd.read_csv('./ml-latest-small/movies.csv')
ratings = pd.read_csv('./ml-latest-small/ratings.csv')
print(movies.shape)
print(ratings.shape)
(9742, 3)
(100836, 4)
movies.head()
movieId title genres
0 1 Toy Story (1995) Adventure|Animation|Children|Comedy|Fantasy
1 2 Jumanji (1995) Adventure|Children|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama|Romance
4 5 Father of the Bride Part II (1995) Comedy
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
ratings_matrix.head(3)
movieId 1 2 3 4 5 6 7 8 9 10 ... 193565 193567 193571 193573 193579 193581 193583 193585 193587 193609
userId
1 4.0 NaN 4.0 NaN NaN 4.0 NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
3 rows × 9724 columns
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0 으로 변환 // null 이니깐 ... 희소행렬로 처리
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head(3)
itle '71 (2014) 'Hellboy': The Seeds of Creation (2004) 'Round Midnight (1986) 'Salem's Lot (2004) 'Til There Was You (1997) 'Tis the Season for Love (2015) 'burbs, The (1989) 'night Mother (1986) (500) Days of Summer (2009) *batteries not included (1987) ... Zulu (2013) [REC] (2007) [REC]² (2009) [REC]³ 3 Génesis (2012) anohana: The Flower We Saw That Day - The Movie (2013) eXistenZ (1999) xXx (2002) xXx: State of the Union (2005) ¡Three Amigos! (1986) À nous la liberté (Freedom for Us) (1931)
userId
1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 4.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 rows × 9719 columns
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head(3)
(9719, 9719)
title '71 (2014) 'Hellboy': The Seeds of Creation (2004) 'Round Midnight (1986) 'Salem's Lot (2004) 'Til There Was You (1997) 'Tis the Season for Love (2015) 'burbs, The (1989) 'night Mother (1986) (500) Days of Summer (2009) *batteries not included (1987) ... Zulu (2013) [REC] (2007) [REC]² (2009) [REC]³ 3 Génesis (2012) anohana: The Flower We Saw That Day - The Movie (2013) eXistenZ (1999) xXx (2002) xXx: State of the Union (2005) ¡Three Amigos! (1986) À nous la liberté (Freedom for Us) (1931)
title
'71 (2014) 1.0 0.000000 0.000000 0.0 0.0 0.0 0.000000 0.0 0.141653 0.0 ... 0.0 0.342055 0.543305 0.707107 0.0 0.0 0.139431 0.327327 0.0 0.0
'Hellboy': The Seeds of Creation (2004) 0.0 1.000000 0.707107 0.0 0.0 0.0 0.000000 0.0 0.000000 0.0 ... 0.0 0.000000 0.000000 0.000000 0.0 0.0 0.000000 0.000000 0.0 0.0
'Round Midnight (1986) 0.0 0.707107 1.000000 0.0 0.0 0.0 0.176777 0.0 0.000000 0.0 ... 0.0 0.000000 0.000000 0.000000 0.0 0.0 0.000000 0.000000 0.0 0.0
3 rows × 9719 columns
item_sim_df["Godfather, The (1972)"].sort_values(ascending=False)[:6]
title
Godfather, The (1972) 1.000000
Godfather: Part II, The (1974) 0.821773
Goodfellas (1990) 0.664841
One Flew Over the Cuckoo's Nest (1975) 0.620536
Star Wars: Episode IV - A New Hope (1977) 0.595317
Fargo (1996) 0.588614
Name: Godfather, The (1972), dtype: float64
item_sim_df["Inception (2010)"].sort_values(ascending=False)[1:6] # 자기자신 빼고
title
Dark Knight, The (2008) 0.727263
Inglourious Basterds (2009) 0.646103
Shutter Island (2010) 0.617736
Dark Knight Rises, The (2012) 0.617504
Fight Club (1999) 0.615417
Name: Inception (2010), dtype: float64
ratings_matrix.head(3)
title '71 (2014) 'Hellboy': The Seeds of Creation (2004) 'Round Midnight (1986) 'Salem's Lot (2004) 'Til There Was You (1997) 'Tis the Season for Love (2015) 'burbs, The (1989) 'night Mother (1986) (500) Days of Summer (2009) *batteries not included (1987) ... Zulu (2013) [REC] (2007) [REC]² (2009) [REC]³ 3 Génesis (2012) anohana: The Flower We Saw That Day - The Movie (2013) eXistenZ (1999) xXx (2002) xXx: State of the Union (2005) ¡Three Amigos! (1986) À nous la liberté (Freedom for Us) (1931)
userId
1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 4.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 rows × 9719 columns
ratings_pred = predict_rating(ratings_matrix.values , item_sim_df.values)
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
print(ratings_pred_matrix.shape)
ratings_pred_matrix.head(3)
(610, 9719)
title '71 (2014) 'Hellboy': The Seeds of Creation (2004) 'Round Midnight (1986) 'Salem's Lot (2004) 'Til There Was You (1997) 'Tis the Season for Love (2015) 'burbs, The (1989) 'night Mother (1986) (500) Days of Summer (2009) *batteries not included (1987) ... Zulu (2013) [REC] (2007) [REC]² (2009) [REC]³ 3 Génesis (2012) anohana: The Flower We Saw That Day - The Movie (2013) eXistenZ (1999) xXx (2002) xXx: State of the Union (2005) ¡Three Amigos! (1986) À nous la liberté (Freedom for Us) (1931)
userId
1 0.070345 0.577855 0.321696 0.227055 0.206958 0.194615 0.249883 0.102542 0.157084 0.178197 ... 0.113608 0.181738 0.133962 0.128574 0.006179 0.212070 0.192921 0.136024 0.292955 0.720347
2 0.018260 0.042744 0.018861 0.000000 0.000000 0.035995 0.013413 0.002314 0.032213 0.014863 ... 0.015640 0.020855 0.020119 0.015745 0.049983 0.014876 0.021616 0.024528 0.017563 0.000000
3 0.011884 0.030279 0.064437 0.003762 0.003749 0.002722 0.014625 0.002085 0.005666 0.006272 ... 0.006923 0.011665 0.011800 0.012225 0.000000 0.008194 0.007017 0.009229 0.010420 0.084501
3 rows × 9719 columns
가중치 평점 부여뒤에 예측 성능 평가 MSE를 구함
from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 영화에 대해서만 예측 성능 평가 MSE 를 구함.
def get_mse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
print('아이템 기반 모든 인접 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
# 아이템 기반 모든 인접 이웃 MSE: 9.895354759094706
top-n 유사도를 가진 데이터들에 대해서만 예측 평점 계산
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행.
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return pred
top-n 유사도 기반의 예측 평점 및 MSE 계산
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, n=20)
print('아이템 기반 인접 TOP-20 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
# 계산된 예측 평점 데이터는 DataFrame으로 재생성
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
# 아이템 기반 인접 TOP-20 이웃 MSE: 3.69501623729494
user_rating_id = ratings_matrix.loc[9, :]
user_rating_id[ user_rating_id > 0].sort_values(ascending=False)[:10]
title
Adaptation (2002) 5.0
Austin Powers in Goldmember (2002) 5.0
Lord of the Rings: The Fellowship of the Ring, The (2001) 5.0
Lord of the Rings: The Two Towers, The (2002) 5.0
Producers, The (1968) 5.0
Citizen Kane (1941) 5.0
Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) 5.0
Back to the Future (1985) 5.0
Glengarry Glen Ross (1992) 4.0
Sunset Blvd. (a.k.a. Sunset Boulevard) (1950) 4.0
Name: 9, dtype: float64
사용자가 관람하지 않은 영화 중에서 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
아이템 기반 유사도로 평점이 부여된 데이터 세트에서 해당 사용자가 관람하지 않은 영화들의 예측 평점이 가장 높은 영화를 추천
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies
pred_score
title
Shrek (2001) 0.866202
Spider-Man (2002) 0.857854
Last Samurai, The (2003) 0.817473
Indiana Jones and the Temple of Doom (1984) 0.816626
Matrix Reloaded, The (2003) 0.800990
Harry Potter and the Sorcerer's Stone (a.k.a. Harry Potter and the Philosopher's Stone) (2001) 0.765159
Gladiator (2000) 0.740956
Matrix, The (1999) 0.732693
Pirates of the Caribbean: The Curse of the Black Pearl (2003) 0.689591
Lord of the Rings: The Return of the King, The (2003) 0.676711
import pandas as pd
import numpy as np
import warnings; warnings.filterwarnings('ignore')
movies =pd.read_csv('./tmdb-5000-movie-dataset/tmdb_5000_movies.csv')
print(movies.shape)
movies.head(1)
(4803, 20)
budget genres homepage id keywords original_language original_title overview popularity production_companies production_countries release_date revenue runtime spoken_languages status tagline title vote_average vote_count
0 237000000 [{"id": 28, "name": "Action"}, {"id": 12, "nam... http://www.avatarmovie.com/ 19995 [{"id": 1463, "name": "culture clash"}, {"id":... en Avatar In the 22nd century, a paraplegic Marine is di... 150.437577 [{"name": "Ingenious Film Partners", "id": 289... [{"iso_3166_1": "US", "name": "United States o... 2009-12-10 2787965087 162.0 [{"iso_639_1": "en", "name": "English"}, {"iso... Released Enter the World of Pandora. Avatar 7.2 11800
movies_df['genres'] = movies_df['genres'].apply(lambda x : [ y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [ y['name'] for y in x])
movies_df[['genres', 'keywords']][:1]
genres keywords
0 [Action, Adventure, Fantasy, Science Fiction] [culture clash, future, space war, space colony, society, space travel, futuristic, romance, spa...
장르 콘텐츠 필터링을 이용한 영화 추천. 장르 문자열을 Count 벡터화 후에 코사인 유사도로 각 영화를 비교
장르 문자열의 Count기반 피처 벡터화
type(('*').join(['test', 'test2']))
str
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer를 적용하기 위해 공백문자로 word 단위가 구분되는 문자열로 변환.
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' ').join(x))
count_vect = CountVectorizer(min_df=0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
print(genre_mat.shape)
#개별장르가 276개
# (4803, 276)
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
# df, 기준인덱스, 기준영화, 10개 추천영화, 10개 추천
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_movie = df[df['title'] == title_name]
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고
# sorted_ind 인자로 입력된 genre_sim_sorted_ind 객체에서 유사도 순으로 top_n 개의 index 추출
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
# 추출된 top_n index들 출력. top_n index는 2차원 데이터 임.
#dataframe에서 index로 사용하기 위해서 1차원 array로 변경
print(similar_indexes) # 코사인유사도가 가장 높은
similar_indexes = similar_indexes.reshape(-1)
return df.iloc[similar_indexes]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average']]
# 장르만 같으니 goodfellas같은 영화가 뒤로 밀려남
[[2731 1243 3636 1946 2640 4065 1847 4217 883 3866]]
title vote_average
2731 The Godfather: Part II 8.3
1243 Mean Streets 7.2
3636 Light Sleeper 5.7
1946 The Bad Lieutenant: Port of Call - New Orleans 6.0
2640 Things to Do in Denver When You're Dead 6.7
4065 Mi America 0.0
1847 GoodFellas 8.2
4217 Kids 6.8
883 Catch Me If You Can 7.7
3866 City of God 8.1
평점이 높은 영화 정보 확인
movies_df[['title','vote_average','vote_count']].sort_values('vote_average', ascending=False)[:10]
# 평점수(votecount)가 낮으면 신뢰도가 떨어짐, vs shawshank redemption은 카운트도 높고 평점도 높고
title vote_average vote_count
3519 Stiff Upper Lips 10.0 1
4247 Me You and Five Bucks 10.0 2
4045 Dancer, Texas Pop. 81 10.0 1
4662 Little Big Top 10.0 1
3992 Sardaarji 9.5 2
2386 One Man's Hero 9.3 2
2970 There Goes My Baby 8.5 2
1881 The Shawshank Redemption 8.5 8205
2796 The Prisoner of Zenda 8.4 11
3337 The Godfather 8.4 5893
평가 횟수에 대한 가중치가 부여된 평점(Weighted Rating) 계산 가중 평점(Weighted Rating) = (v/(v+m)) * R + (m/(v+m)) * C
■ v: 개별 영화에 평점을 투표한 횟수 ■ m: 평점을 부여하기 위한 최소 투표 횟수 ■ R: 개별 영화에 대한 평균 평점. ■ C: 전체 영화에 대한 평균 평점
C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
print('C:',round(C,3), 'm:',round(m,3))
# C: 6.092 m: 370.2
percentile = 0.6
m = movies_df['vote_count'].quantile(percentile)
C = movies_df['vote_average'].mean()
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C )
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)
movies_df[['title','vote_average','weighted_vote','vote_count']].sort_values('weighted_vote',
ascending=False)[:10]
title vote_average weighted_vote vote_count
1881 The Shawshank Redemption 8.5 8.396052 8205
3337 The Godfather 8.4 8.263591 5893
662 Fight Club 8.3 8.216455 9413
3232 Pulp Fiction 8.3 8.207102 8428
65 The Dark Knight 8.2 8.136930 12002
1818 Schindler's List 8.3 8.126069 4329
3865 Whiplash 8.3 8.123248 4254
809 Forrest Gump 8.2 8.105954 7927
2294 Spirited Away 8.3 8.105867 3840
2731 The Godfather: Part II 8.3 8.079586 3338
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
# top_n의 2배에 해당하는 쟝르 유사성이 높은 index 추출
similar_indexes = sorted_ind[title_index, :(top_n*2)] # 20개
similar_indexes = similar_indexes.reshape(-1)
# 기준 영화 index는 제외
similar_indexes = similar_indexes[similar_indexes != title_index]
# top_n의 2배에 해당하는 후보군에서 weighted_vote 높은 순으로 top_n 만큼 추출
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather',10)
similar_movies[['title', 'vote_average', 'weighted_vote']]
title vote_average weighted_vote
2731 The Godfather: Part II 8.3 8.079586
1847 GoodFellas 8.2 7.976937
3866 City of God 8.1 7.759693
1663 Once Upon a Time in America 8.2 7.657811
883 Catch Me If You Can 7.7 7.557097
281 American Gangster 7.4 7.141396
4041 This Is England 7.4 6.739664
1149 American Hustle 6.8 6.717525
1243 Mean Streets 7.2 6.626569
2839 Rounders 6.9 6.530427
from sklearn.linear_model import Ridge , LogisticRegression
from sklearn.model_selection import train_test_split , cross_val_score
from sklearn.feature_extraction.text import CountVectorizer , TfidfVectorizer
import pandas as pd
mercari_df= pd.read_csv('mercari_train.tsv',sep='\t')
print(mercari_df.shape)
mercari_df.head(3)
(1482535, 8)
train_id name item_condition_id category_name brand_name price shipping item_description
0 0 MLB Cincinnati Reds T Shirt Size XL 3 Men/Tops/T-shirts NaN 10.0 1 No description yet
1 1 Razer BlackWidow Chroma Keyboard 3 Electronics/Computers & Tablets/Components & P... Razer 52.0 0 This keyboard is in great condition and works ...
2 2 AVA-VIV Blouse 1 Women/Tops & Blouses/Blouse Target 10.0 1 Adorable top with a hint of lace and a key hol...
train_id: 데이터 id
name: 제품명
item_condition_id: 판매자가 제공하는 제품 상태
category_name: 카테고리 명
brand_name: 브랜드 이름
price: 제품 가격. 예측을 위한 타깃 속성
shipping: 배송비 무료 여부. 1이면 무료(판매자가 지불), 0이면 유료(구매자 지불)
mercari_df[['cat_dae','cat_jung','cat_so']].head()
cat_dae cat_jung cat_so
0 Men Tops T-shirts
1 Electronics Computers & Tablets Components & Parts
2 Women Tops & Blouses Blouse
3 Home Home Décor Home Décor Accents
4 Women Jewelry Necklaces
print('brand name 의 유형 건수 :', mercari_df['brand_name'].nunique())
print('brand name sample 5건 : \n', mercari_df['brand_name'].value_counts()[:5])
brand name 의 유형 건수 : 4810
brand name sample 5건 :
Other_Null 632682
PINK 54088
Nike 54043
Victoria's Secret 48036
LuLaRoe 31024
Name: brand_name, dtype: int64
print('name 의 종류 갯수 :', mercari_df['name'].nunique())
print('name sample 7건 : \n', mercari_df['name'][:7])
name 의 종류 갯수 : 1225273
name sample 7건 :
0 MLB Cincinnati Reds T Shirt Size XL
1 Razer BlackWidow Chroma Keyboard
2 AVA-VIV Blouse
3 Leather Horse Statues
4 24K GOLD plated rose
5 Bundled items requested for Ruie
6 Acacia pacific tides santorini top
Name: name, dtype: object
item_description의 문자열 개수 확인
pd.set_option('max_colwidth', 200)
# item_description의 평균 문자열 개수
print('item_description 평균 문자열 개수:',mercari_df['item_description'].str.len().mean())
mercari_df['item_description'][:2]
item_description 평균 문자열 개수: 145.7113889385411
0 No description yet
1 This keyboard is in great condition and works like it came out of the box. All of the ports are tested and work perfectly. The lights are customizable via the Razer Synapse app on your PC.
Name: item_description, dtype: object
import gc
gc.collect()
# 120
name은 Count로, item_description은 TF-IDF로 피처 벡터화
# name 속성에 대한 feature vectorization 변환
cnt_vec = CountVectorizer(max_features=30000)
X_name = cnt_vec.fit_transform(mercari_df.name)
# item_description 에 대한 feature vectorization 변환
tfidf_descp = TfidfVectorizer(max_features = 50000, ngram_range= (1,3) , stop_words='english')
X_descp = tfidf_descp.fit_transform(mercari_df['item_description'])
print('name vectorization shape:',X_name.shape)
print('item_description vectorization shape:',X_descp.shape)
name vectorization shape: (1482535, 30000)
item_description vectorization shape: (1482535, 50000)
사이킷런의 LabelBinarizer를 이용하여 원-핫 인코딩 변환 후 희소행렬 최적화 형태로 저장
피처 벡터화된 희소 행렬과 원-핫 인코딩된 희소 행렬을 모두 scipy 패키지의 hstack()함수를 이용하여 결합
from scipy.sparse import hstack
import gc
sparse_matrix_list = (X_name, X_descp, X_brand, X_item_cond_id,
X_shipping, X_cat_dae, X_cat_jung, X_cat_so)
# 사이파이 sparse 모듈의 hstack 함수를 이용하여 앞에서 인코딩과 Vectorization을 수행한 데이터 셋을 모두 결합.
X_features_sparse= hstack(sparse_matrix_list).tocsr()
print(type(X_features_sparse), X_features_sparse.shape)
# 데이터 셋이 메모리를 많이 차지하므로 사용 용도가 끝났으면 바로 메모리에서 삭제.
del X_features_sparse
gc.collect()
<class 'scipy.sparse.csr.csr_matrix'> (1482535, 85812)
20
import re
train_df = train_df.fillna(' ')
# 정규 표현식을 이용하여 숫자를 공백으로 변경(정규 표현식으로 \d 는 숫자를 의미함.)
train_df['document'] = train_df['document'].apply( lambda x : re.sub(r"\d+", " ", x) )
train_df.drop('id', axis=1, inplace=True)
# 테스트 데이터 셋을 로딩하고 동일하게 Null 및 숫자를 공백으로 변환
test_df = pd.read_csv('ratings_test.txt', sep='\t')
test_df = test_df.fillna(' ')
test_df['document'] = test_df['document'].apply( lambda x : re.sub(r"\d+", " ", x) )
test_df.drop('id', axis=1, inplace=True)
from konlpy.tag import Twitter
twitter = Twitter()
def tw_tokenizer(text):
# 입력 인자로 들어온 text 를 형태소 단어로 토큰화 하여 list 객체 반환
tokens_ko = twitter.morphs(text)
return tokens_ko
tw_tokenizer('첫째')
# ['첫째']
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# Twitter 객체의 morphs( ) 객체를 이용한 tokenizer를 사용. ngram_range는 (1,2)
tfidf_vect = TfidfVectorizer(tokenizer=tw_tokenizer, ngram_range=(1,2), min_df=3, max_df=0.9)
tfidf_vect.fit(train_df['document'])
tfidf_matrix_train = tfidf_vect.transform(train_df['document'])
# Logistic Regression 을 이용하여 감성 분석 Classification 수행.
lg_clf = LogisticRegression(random_state=0)
# Parameter C 최적화를 위해 GridSearchCV 를 이용.
params = { 'C': [1 ,3.5, 4.5, 5.5, 10 ] }
grid_cv = GridSearchCV(lg_clf , param_grid=params , cv=3 ,scoring='accuracy', verbose=1 )
grid_cv.fit(tfidf_matrix_train , train_df['label'] )
print(grid_cv.best_params_ , round(grid_cv.best_score_,4))
# {'C': 3.5} 0.8593
from sklearn.metrics import accuracy_score
# 학습 데이터를 적용한 TfidfVectorizer를 이용하여 테스트 데이터를 TF-IDF 값으로 Feature 변환함.
tfidf_matrix_test = tfidf_vect.transform(test_df['document'])
# classifier 는 GridSearchCV에서 최적 파라미터로 학습된 classifier를 그대로 이용
best_estimator = grid_cv.best_estimator_
preds = best_estimator.predict(tfidf_matrix_test)
print('Logistic Regression 정확도: ',accuracy_score(test_df['label'],preds))
# Logistic Regression 정확도: 0.86172
from sklearn.feature_extraction.text import TfidfVectorizer
doc_list = ['if you take the blue pill, the story ends' ,
'if you take the red pill, you stay in Wonderland',
'if you take the red pill, I show you how deep the rabbit hole goes']
tfidf_vect_simple = TfidfVectorizer()
feature_vect_simple = tfidf_vect_simple.fit_transform(doc_list)
print(feature_vect_simple.shape)
# (3, 18)
from sklearn.metrics.pairwise import cosine_similarity
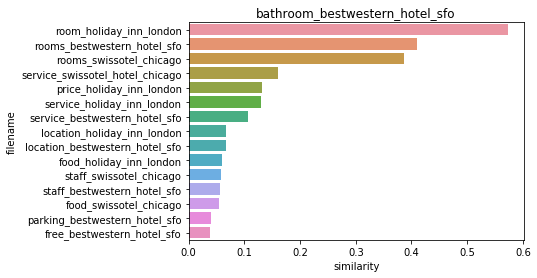
# cluster_label=1인 데이터는 호텔로 클러스터링된 데이터임. DataFrame에서 해당 Index를 추출
hotel_indexes = document_df[document_df['cluster_label']==1].index
print('호텔로 클러스터링 된 문서들의 DataFrame Index:', hotel_indexes)
# 호텔로 클러스터링된 데이터 중 첫번째 문서를 추출하여 파일명 표시.
comparison_docname = document_df.iloc[hotel_indexes[0]]['filename']
print('##### 비교 기준 문서명 ',comparison_docname,' 와 타 문서 유사도######')
''' document_df에서 추출한 Index 객체를 feature_vect로 입력하여 호텔 클러스터링된 feature_vect 추출
이를 이용하여 호텔로 클러스터링된 문서 중 첫번째 문서와 다른 문서간의 코사인 유사도 측정.'''
similarity_pair = cosine_similarity(feature_vect[hotel_indexes[0]] , feature_vect[hotel_indexes])
print(similarity_pair)
호텔로 클러스터링 된 문서들의 DataFrame Index: Int64Index([1, 13, 14, 15, 20, 21, 24, 28, 30, 31, 32, 38, 39, 40, 45, 46], dtype='int64')
##### 비교 기준 문서명 bathroom_bestwestern_hotel_sfo 와 타 문서 유사도######
[[1. 0.05907195 0.05404862 0.03739629 0.06629355 0.06734556
0.04017338 0.13113702 0.41011101 0.3871916 0.57253197 0.10600704
0.13058128 0.1602411 0.05539602 0.05839754]]
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# argsort()를 이용하여 앞예제의 첫번째 문서와 타 문서간 유사도가 큰 순으로 정렬한 인덱스 반환하되 자기 자신은 제외.
sorted_index = similarity_pair.argsort()[:,::-1]
sorted_index = sorted_index[:, 1:]
print(sorted_index)
# 유사도가 큰 순으로 hotel_indexes를 추출하여 재 정렬.
print(hotel_indexes)
hotel_sorted_indexes = hotel_indexes[sorted_index.reshape(-1,)]
# 유사도가 큰 순으로 유사도 값을 재정렬하되 자기 자신은 제외
hotel_1_sim_value = np.sort(similarity_pair.reshape(-1,))[::-1]
hotel_1_sim_value = hotel_1_sim_value[1:]
# 유사도가 큰 순으로 정렬된 Index와 유사도값을 이용하여 파일명과 유사도값을 Seaborn 막대 그래프로 시각화
hotel_1_sim_df = pd.DataFrame()
hotel_1_sim_df['filename'] = document_df.iloc[hotel_sorted_indexes]['filename']
hotel_1_sim_df['similarity'] = hotel_1_sim_value
sns.barplot(x='similarity', y='filename',data=hotel_1_sim_df)
plt.title(comparison_docname)
[[10 8 9 13 7 12 11 5 4 1 15 14 2 6 3]]
Int64Index([1, 13, 14, 15, 20, 21, 24, 28, 30, 31, 32, 38, 39, 40, 45, 46], dtype='int64')
Text(0.5,1,'bathroom_bestwestern_hotel_sfo')