import pandas as pd
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 feature명을 새롭게 수정하는 get_new_feature_name_df()를 이용하여 새로운 feature명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()
학습/테스트 데이터로 분리하고 랜덤 포레스트로 학습/예측/평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))
# 랜덤 포레스트 정확도: 0.9253
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train , X_test , y_train , y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifer 학습.
dt_clf.fit(X_train , y_train)
# DecisionTreeClassifier(random_state=156)
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names , \
feature_names = iris_data.feature_names, impurity=True, filled=True)
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
import seaborn as sns
import numpy as np
%matplotlib inline
# feature importance 추출
print("Feature importances:\n{0}".format(np.round(dt_clf.feature_importances_, 3)))
# feature별 importance 매핑
for name, value in zip(iris_data.feature_names , dt_clf.feature_importances_):
print('{0} : {1:.3f}'.format(name, value))
# feature importance를 column 별로 시각화 하기
sns.barplot(x=dt_clf.feature_importances_ , y=iris_data.feature_names)
Feature importances:
[0.025 0. 0.555 0.42 ]
sepal length (cm) : 0.025
sepal width (cm) : 0.000
petal length (cm) : 0.555
petal width (cm) : 0.420
결정 트리(Decision TREE) 과적합(Overfitting)
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
# 2차원 시각화를 위해서 feature는 2개, 결정값 클래스는 3가지 유형의 classification 샘플 데이터 생성.
X_features, y_labels = make_classification(n_features=2, n_redundant=0, n_informative=2,
n_classes=3, n_clusters_per_class=1,random_state=0)
# plot 형태로 2개의 feature로 2차원 좌표 시각화, 각 클래스값은 다른 색깔로 표시됨.
plt.scatter(X_features[:, 0], X_features[:, 1], marker='o', c=y_labels, s=25, cmap='rainbow', edgecolor='k')
import numpy as np
# Classifier의 Decision Boundary를 시각화 하는 함수
def visualize_boundary(model, X, y):
fig,ax = plt.subplots()
# 학습 데이타 scatter plot으로 나타내기
ax.scatter(X[:, 0], X[:, 1], c=y, s=25, cmap='rainbow', edgecolor='k',
clim=(y.min(), y.max()), zorder=3)
ax.axis('tight')
ax.axis('off')
xlim_start , xlim_end = ax.get_xlim()
ylim_start , ylim_end = ax.get_ylim()
# 호출 파라미터로 들어온 training 데이타로 model 학습 .
model.fit(X, y)
# meshgrid 형태인 모든 좌표값으로 예측 수행.
xx, yy = np.meshgrid(np.linspace(xlim_start,xlim_end, num=200),np.linspace(ylim_start,ylim_end, num=200))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()]).reshape(xx.shape)
# contourf() 를 이용하여 class boundary 를 visualization 수행.
n_classes = len(np.unique(y))
contours = ax.contourf(xx, yy, Z, alpha=0.3,
levels=np.arange(n_classes + 1) - 0.5,
cmap='rainbow', clim=(y.min(), y.max()),
zorder=1)
from sklearn.tree import DecisionTreeClassifier
# 특정한 트리 생성 제약없는 결정 트리의 Decsion Boundary 시각화.
dt_clf = DecisionTreeClassifier().fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
# min_samples_leaf=6 으로 트리 생성 조건을 제약한 Decision Boundary 시각화
dt_clf = DecisionTreeClassifier( min_samples_leaf=6).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
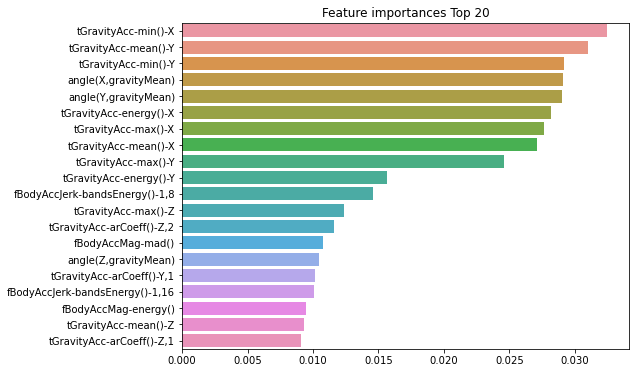
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고, 시본(Seaborn)의 막대그래프로 쉽게 표현하기 위해 Series변환
ftr_importances = pd.Series(ftr_importances_values, index=X_train.columns )
# 중요도값 순으로 Series를 정렬
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()
# 0값을 검사할 피처명 리스트 객체 설정
zero_features = ['Glucose', 'BloodPressure','SkinThickness','Insulin','BMI']
# 전체 데이터 건수
total_count = diabetes_data['Glucose'].count()
# 피처별로 반복 하면서 데이터 값이 0 인 데이터 건수 추출하고, 퍼센트 계산
for feature in zero_features:
zero_count = diabetes_data[diabetes_data[feature] == 0][feature].count()
print('{0} 0 건수는 {1}, 퍼센트는 {2:.2f} %'.format(feature, zero_count, 100*zero_count/total_count))
Glucose 0 건수는 5, 퍼센트는 0.65 %
BloodPressure 0 건수는 35, 퍼센트는 4.56 %
SkinThickness 0 건수는 227, 퍼센트는 29.56 %
Insulin 0 건수는 374, 퍼센트는 48.70 %
BMI 0 건수는 11, 퍼센트는 1.43 %
0값을 평균값으로 대체
# zero_features 리스트 내부에 저장된 개별 피처들에 대해서 0값을 평균 값으로 대체
diabetes_data[zero_features]=diabetes_data[zero_features].replace(0, diabetes_data[zero_features].mean())
StandardScaler 클래스를 이용해 피처 데이터 세트에 일괄적으로 스케일링 적용하고 0값을 평균값으로 대체한 데이터 세트로 학습/예측
X = diabetes_data.iloc[:, :-1]
y = diabetes_data.iloc[:, -1]
# StandardScaler 클래스를 이용해 피처 데이터 세트에 일괄적으로 스케일링 적용
scaler = StandardScaler( )
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size = 0.2, random_state = 156, stratify=y)
# 로지스틱 회귀로 학습, 예측 및 평가 수행.
lr_clf = LogisticRegression()
lr_clf.fit(X_train , y_train)
pred = lr_clf.predict(X_test)
# roc_auc_score 수정에 따른 추가
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
get_clf_eval(y_test , pred, pred_proba)
# 오차 행렬
# [[90 10]
# [21 33]]
# 정확도: 0.7987, 정밀도: 0.7674, 재현율: 0.6111, F1: 0.6804, AUC:0.8433
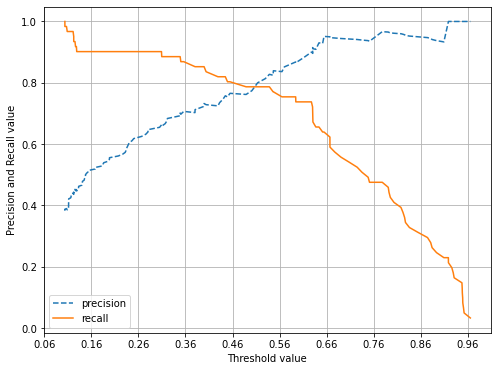
분류결정 임곗값을 변경하면서 성능 측정
from sklearn.preprocessing import Binarizer
def get_eval_by_threshold(y_test , pred_proba_c1, thresholds):
# thresholds 리스트 객체내의 값을 차례로 iteration하면서 Evaluation 수행.
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print('임곗값:',custom_threshold)
# roc_auc_score 관련 수정
get_clf_eval(y_test , custom_predict, pred_proba_c1)
import numpy as np
from sklearn.base import BaseEstimator
class MyDummyClassifier(BaseEstimator):
# fit( ) 메소드는 아무것도 학습하지 않음.
def fit(self, X , y=None):
pass
# predict( ) 메소드는 단순히 Sex feature가 1 이면 0 , 그렇지 않으면 1 로 예측함.
def predict(self, X):
pred = np.zeros( ( X.shape[0], 1 ))
for i in range (X.shape[0]) :
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else :
pred[i] = 1
return pred
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 머신러닝 알고리즘에 불필요한 속성 제거
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
# 레이블 인코딩 수행.
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 앞에서 설정한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 원본 데이터를 재로딩, 데이터 가공, 학습데이터/테스트 데이터 분할.
titanic_df = pd.read_csv('./titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df= titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test=train_test_split(X_titanic_df, y_titanic_df, \
test_size=0.2, random_state=0)
# 위에서 생성한 Dummy Classifier를 이용하여 학습/예측/평가 수행.
myclf = MyDummyClassifier()
myclf.fit(X_train ,y_train)
mypredictions = myclf.predict(X_test)
print('Dummy Classifier의 정확도는: {0:.4f}'.format(accuracy_score(y_test , mypredictions)))
# Dummy Classifier의 정확도는: 0.7877
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.base import BaseEstimator
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
class MyFakeClassifier(BaseEstimator):
def fit(self,X,y):
pass
# 입력값으로 들어오는 X 데이터 셋의 크기만큼 모두 0값으로 만들어서 반환
def predict(self,X):
return np.zeros( (len(X), 1) , dtype=bool)
# 사이킷런의 내장 데이터 셋인 load_digits( )를 이용하여 MNIST 데이터 로딩
digits = load_digits()
print(digits.data)
print("### digits.data.shape:", digits.data.shape)
print(digits.target)
print("### digits.target.shape:", digits.target.shape)
[[ 0. 0. 5. ... 0. 0. 0.]
[ 0. 0. 0. ... 10. 0. 0.]
[ 0. 0. 0. ... 16. 9. 0.]
...
[ 0. 0. 1. ... 6. 0. 0.]
[ 0. 0. 2. ... 12. 0. 0.]
[ 0. 0. 10. ... 12. 1. 0.]]
### digits.data.shape: (1797, 64)
[0 1 2 ... 8 9 8]
### digits.target.shape: (1797,)
# digits번호가 7번이면 True이고 이를 astype(int)로 1로 변환, 7번이 아니면 False이고 0으로 변환.
y = (digits.target == 7).astype(int)
X_train, X_test, y_train, y_test = train_test_split( digits.data, y, random_state=11)
# 불균형한 레이블 데이터 분포도 확인.
print('레이블 테스트 세트 크기 :', y_test.shape)
print('테스트 세트 레이블 0 과 1의 분포도')
print(pd.Series(y_test).value_counts())
# Dummy Classifier로 학습/예측/정확도 평가
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train , y_train)
fakepred = fakeclf.predict(X_test)
print('모든 예측을 0으로 하여도 정확도는:{:.3f}'.format(accuracy_score(y_test , fakepred)))
# 2진분류에서 정확도는 애매함# 2진분류에서 정확도는 애매함
# 레이블 테스트 세트 크기 : (450,)
# 테스트 세트 레이블 0 과 1의 분포도
# 0 405
# 1 45
# dtype: int64
# 모든 예측을 0으로 하여도 정확도는:0.900
Confusion Matrix
2진분류 예측오류가 얼마인지 4분면으로 predicted Class X actual class => negative & positive 예측기준 실제가 같은지
pred_proba = lr_clf.predict_proba(X_test)
pred = lr_clf.predict(X_test)
print('pred_proba()결과 Shape : {0}'.format(pred_proba.shape))
print('pred_proba array에서 앞 3개만 샘플로 추출 \n:', pred_proba[:3])
# 예측 확률 array 와 예측 결과값 array 를 concatenate 하여 예측 확률과 결과값을 한눈에 확인
pred_proba_result = np.concatenate([pred_proba , pred.reshape(-1,1)],axis=1)
print('두개의 class 중에서 더 큰 확률을 클래스 값으로 예측 \n',pred_proba_result[:3])
# pred는 1차원이기 때문에 reshape(-1, 1)2차원으로 바꿔줌
#첫번째 열이 0이 될 확률, 2번째 열이 1이 될 확률 // 임계값 몇일까??
pred_proba()결과 Shape : (179, 2)
pred_proba array에서 앞 3개만 샘플로 추출
: [[0.4616653 0.5383347 ]
[0.87862763 0.12137237]
[0.87727002 0.12272998]]
두개의 class 중에서 더 큰 확률을 클래스 값으로 예측
[[0.4616653 0.5383347 1. ]
[0.87862763 0.12137237 0. ]
[0.87727002 0.12272998 0. ]]
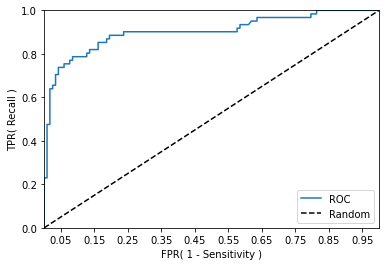
Receiver Operation Characteristic Curve(무선통신장비 측정 툴)기반 AUC(Area Under Curve)값은 roc 곡선 면적으로 1에 가까울수록 좋은 수치 FPR(False Positive Rate)와 TPR(True Positive Rate) 관계 의학분야에 사용
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
titanic_df = pd.read_csv('./titanic_train.csv')
titanic_df.head(3) # 데이터 테이블 상태 확인
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
Passengerid: 탑승자 데이터 일련번호
survived: 생존 여부, 0 = 사망, 1 = 생존 // target 값
Pclass: 티켓의 선실 등급, 1 = 일등석, 2 = 이등석, 3 = 삼등석
sex: 탑승자 성별
name: 탑승자 이름
Age: 탑승자 나이
sibsp: 같이 탑승한 형제자매 또는 배우자 인원수
parch: 같이 탑승한 부모님 또는 어린이 인원수
ticket: 티켓 번호
fare: 요금
cabin: 선실 번호
embarked: 중간 정착 항구 C = Cherbourg, Q = Queenstown, S = Southampton
print('\n ### train 데이터 정보 ### \n')
print(titanic_df.info())
# 데이터 정보 null 대체, object drop 전처리
### train 데이터 정보 ###
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
** NULL 컬럼들에 대한 처리 **
# null 전처리
titanic_df['Age'].fillna(titanic_df['Age'].mean(),inplace=True)
titanic_df['Cabin'].fillna('N',inplace=True)
titanic_df['Embarked'].fillna('N',inplace=True)
print('데이터 세트 Null 값 갯수 ',titanic_df.isnull().sum().sum()) # 전체칼럼의 null이 있는지 확인 마무리
# 데이터 세트 Null 값 갯수 0
print('데이터 세트 Null 값 갯수 ',titanic_df.isnull().sum())
데이터 세트 Null 값 갯수 PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
titanic_df['Cabin'] = titanic_df['Cabin'].str[:1] # str이라고 표시를 해줘야 함
print(titanic_df['Cabin'].head(3))
titanic_df['Cabin'].value_counts() # 분포확인
0 N
1 C
2 N
Name: Cabin, dtype: object
N 687
C 59
B 47
D 33
E 32
A 15
F 13
G 4
T 1
Name: Cabin, dtype: int64
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
iris = load_iris()
dt_clf = DecisionTreeClassifier()
train_data = iris.data
train_label = iris.target
# 학습 fit
dt_clf.fit(train_data, train_label)
# 학습 데이터 셋으로 예측 수행
pred = dt_clf.predict(train_data)
print('예측 정확도:',accuracy_score(train_label,pred))
# 예측 정확도 1.0 : 100% => 잘못된 결과 => train_data 학습 후 예측도 동일 데이터
# 좋은 모델, 좋은 실력은 학습, 테스트 내용이 달라도 결과가 거의 동일해야 함
# 예측 정확도: 1.0
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
dt_clf = DecisionTreeClassifier( )
iris_data = load_iris()
# x feature, y label
# 학습, 테스트 분리 함수 train_test_split(featureset, target, 학7:테3, 시드번호)
X_train, X_test,y_train, y_test= train_test_split(iris_data.data, iris_data.target,
test_size=0.3, random_state=121)
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_))
# refit=True로 설정된 GridSearchCV 객체가 fit()을 수행 시 학습이 완료된 Estimator를 내포하고 있으므로 predict()를 통해 예측도 가능.
pred = grid_dtree.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
# GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
# GridSearchCV 최고 정확도: 0.9750
# 테스트 데이터 세트 정확도: 0.9667
# GridSearchCV의 refit으로 이미 학습이 된 estimator 반환
estimator = grid_dtree.best_estimator_ #
# GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
# 테스트 데이터 세트 정확도: 0.9667