shared-weight를 사용하기 때문에 같은 값이면 같은 특징이다라는 점을 활용할 수 있고,
locally connected하기 때문에 부분적인 특징을 보고 특징이 있는지 없는지 여부를 판단할 수 있다
(Locality를 잃지 않는다)
CNN의 가정
1. Stationarity of statistics
- 정상성
- 이미지에서의 정상성이란 이미지의 한 부분에 대한 통계가 다른 부분들과 동일하다는 가정을 한다
- 이미지에서 한 특징이 위치에 상관없이 여러 군데 존재할 수 있고 특정 부분에서 학습된 특징 파라미터를 이용해
다른 위치에서도 동일한 특징을 추출할 수 있다는 의미이다
2. Locality of pixel dependencies
- 이미지는 작은 특징들로 구성되어 있기 때문에 각 픽셀들의 종속성은 특징이 있는 작은 지역으로 한정된다.
- 이미지를 구성하는 특징들은 이미지 전체가 아닌 일부 지역에 근접한 픽셀들로만 구성되고
근접한 픽셀들끼리만 종속성을 가진다
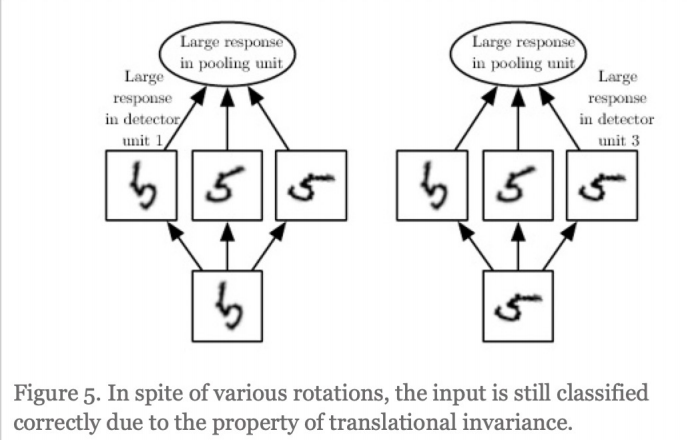
위 그림에서 왼쪽의 경우와 오른쪽의 경우는 같은 것이라 판단할 수 있지만
가운데의 것도 같은 것이라고 판단할 수 있을까?
convolutional layer를 한 번만 통과했다면 다른 것이라 판단할 수 있지만
layer를 여러번 통과한다면 세 가지 경우 모두 같은 특성이라고 볼수 있게 된다
=> layer가 많으면 많을 수록 좋은 점
TypeMarkdownand LaTeX:𝛼^2
import tensorflow as tf
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
tf.keras.layers.Dense
tf.keras.layers.LocallyConnected2D # weight를 공유하지 않는다 / 애매하기 때문에 이것도 저것도 아닌 상황에서 성능이 좋을 수 있다
tf.keras.layers.Conv2D
tf.keras.layers.MaxPool2D (tf.keras.layers.MaxPooling2D)
tf.keras.layers.AvgPool2D (tf.keras.layers.AveragePooling2D)
tf.keras.layers.Conv2D is tf.keras.layers.Convolution2D # 단축 표현
# True
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
data = load_digits()
padding
import numpy as np
import scipy
from scipy.ndimage import convolve
from scipy.signal import convolve, convolve2d
a = np.array([-1,0,1])
b = np.arange(5)
convolve(a, b, 'valid')
# array([-2, -2, -2])
a = np.array([[-1,0],[1,0]])
b = np.arange(9).reshape(3,3)
convolve2d(a,b,'full') # zero padding을 함으로써 값이 공평한 횟수로 연산된다 즉, 공평하게 특성을 검출할 수 있다
# array([[ 0, -1, -2, 0],
# [-3, -3, -3, 0],
# [-3, -3, -3, 0],
# [ 6, 7, 8, 0]])
import mglearn
# dtype이 uint8일 때 최대값은 255, 최소값은 0
# MinMaxScaler로 정규화 할 경우 0과 1사이로 값이 바뀌기 때문에 정사각형 형태로 데이터가 분포한다
# 따라서 방향에 대한 크기변화가 없기 때문에 빠른 학습속도와 정확한 학습결과를 기대할 수 있다
mglearn.plot_scaling.plot_scaling()
왜 convolution 연산에 대해서 합을 할까?
convolution 연산을 할때 element wise 연산을 하게되면(분리된 채널에서 합쳐질 때)특성을 알 수 없을 수도 있다
물론 depth wise convolution은 각각의 특성만 독립적으로 연산하는 경우도 있다
그러나 더하는 것이 성능이 더 좋고, convolution 연산 결과가 원본 이미지의 의미가 변하는 경우는 거의 나오지 않는다
왜 그런 경우가 나오지 않을까?
weight와 bias는 학습을 통해서 찾기 때문에 채널별로 서로 다른 결과가 나올수 있도록 학습이 되기 때문이다
(kernel은 특성을 잘 파악하도록 학습이 된다)
합하는 것이 왜 좋을까?
전통적인 NN에 영향을 받아서 hierarchy한 것을 고려했기 때문에 hierarchy 특징을 학습할 수 있다
image = data.images.reshape(1797,8,8,1) # CNN에서 사용하는 연산하기 위해서 데이터 하나가 3차원이 되도록 데이터를 변화 시켰다
layer1 = tf.keras.layers.Conv2D(2, (3,3)) # filter 개수, filter 모양(단축 표현 가능 (3,3)=>3)
layer1.built # 일시키기 전까지 초기화가 안된다 => lazy Evaluation / 내부적으로 im2col
# False
layer1(image[0]) # 동시에 여러개 연산하기 때문에 안된다 / 데이터를 하나 연산하더라도 4차원 형태로 만들어 줘야 한다
# ValueError: Input 0 of layer conv2d_1 is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: (8, 8, 1)
from skimage.util import view_as_blocks, view_as_windows
import matplotlib.pyplot as plt
import skimage
from skimage.data import camera
import numpy as np
sns.pairplot(wine.frame, hue='target') #
# 원본 데이터를 그 특성에 제일 잘 맞게 다른 형태의 데이터로 변화 시킬 필요가 있다 => Featured data 형태로 바꾼다
# min-max 또는 standard scaling을 사용해서 비정상적으로 영향력이 커지는 경우를 방지하기도 한다
wine.frame.boxplot(figsize=(20,8))
- filter를 사용하면 가장 특징이 잘 나타나게 data를 변형 할 수 있다 (특징의 존재 여부로 문제를 변형한다)
- filter를 사용하여 이미지의 특성을 뚜렷하게 만든다
- filter를 사용하면 특징을 유지한체 크기가 줄어들기 때문에 데이터의 차원이 줄어드는 효과를 기대할 수 있다
- filter는 feature cross와 유사하다
Feature cross
feature를 합성해서 본래 갖고 있던 의미를 잃지 않은 채로 차원을 축소시키는 방법
filter를 사용하면 image 데이터의 문제점을 보완해주기 때문에 굉장히 좋은 방법이지만,
어떤 filter를 사용해야 하는지 선택하는 문제는 어려운 문제이다
결국 어떤 필터를 적용할지 학습을 통해서 찾을수 있지 않을까? 하는 의문으로 해결하게 된다
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
wine.frame.iloc[:,:-1] = ss.fit_transform(wine.frame.iloc[:,:-1])
wine.frame.boxplot(figsize=(20,8)) # 데이터가 다른 형태로 바뀌었다
이때 loss function은 예측값이 실제값에 가까워지는지 판단하는 척도가 되는 함수이다
tf.keras.losses.binary_crossentropy # parameter 변경 불가능, decorator로 기능을 확장할 수 있다 / 그대로 사용할 때 편리함
tf.keras.losses.BinaryCrossentropy() # instance 하면서 완전히 다른 값을 가질 수 있다, subclass 상속을 통해서 다른 값을 가질 수 있다 / 인자를 바꾸거나 원하는 형태로 바꿀 때는 클래스 방식을 쓴다
tf.keras.losses.categorical_crossentropy
tf.keras.losses.CategoricalCrossentropy
tf.keras.losses.SparseCategoricalCrossentropy # one-hot-encoding을 내부적으로 해준다
tf.keras.losses.sparse_categorical_crossentropy # partial을 굳이 사용하지 않고 one-hot-encoding을 할 수 있도록 클래스를 제공한다
from functools import partial
def x(a,b):
return a+b
x2 = partial(x, b=1) # 기존의 함수기능을 변경할 수 있다
x2(3)
# 4
# compile은 내부적으로 computational graph로 바꾸어 lose function를 효율적으로 자동 미분하도록 도와준다
# tf.keras.losses.categorical_crossentropy의 단축 표현 => categorical_crossentropy 단, 단축표현은 parameter 변경 불가능
model.compile(loss=tf.keras.losses.categorical_crossentropy)
compile(학습설계) 할때필요한파라미터3가지
1.lossfunction
2.optimizer=>자동미분을할때사용하는방법설정
3.metrics=>평가기준설정
# 내가 원하는 값의 형태로 바꾸지 않는 지점까지를 logit이라고 한다 / from_logits=True는 logits으로 부터 실제값 - 예측값을 구하는 방법을 사용하겠다는 의미이다
model.compile(loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), optimizer='adam')
'adam' # parameter 변경 불가능
tf.keras.optimizers.Adam() # parameter 변경 가능
Softmax
softmax는 numerical stability하지 않는 문제가 발생할 수 있다
def softmax(logits):
exp = tf.exp(logits)
return exp / tf.reduce_sum(exp)
softmax([10000.,0.]) # softmax는 지수연산을 하기 때문에 큰 값이 들어오면 쉽게 오버플로우가 발생한다
# <tf.Tensor: shape=(2,), dtype=float32, numpy=array([nan, 0.], dtype=float32)>
softmax([1.,3.,2.])
# <tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.09003057, 0.66524094, 0.24472848], dtype=float32)>
def softmax2(logits): # 큰 값이 들어갔을 때 오버플로우를 방지하는 방법 그러나 이 또한 문제가 있다
exp = tf.exp(logits-tf.reduce_max(logits))
return exp / tf.reduce_sum(exp)
softmax2([100000., 0.])
# <tf.Tensor: shape=(2,), dtype=float32, numpy=array([1., 0.], dtype=float32)>
softmax2([100.,3.,0.]) # 가장 큰값만 값을 가지고 나머지는 값을 못갖게 되는 일도 발생한다
# <tf.Tensor: shape=(3,), dtype=float32, numpy=array([1., 0., 0.], dtype=float32)>
softmax2([100.,300.,200.])
# <tf.Tensor: shape=(3,), dtype=float32, numpy=array([0., 1., 0.], dtype=float32)>
softmax2([0.00011,0.000012,0.000014]) # 너무 작은 값이 들어가도 언더플로우가 발생하여 모두 동일한 비율로 들어가게 된다
# <tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.3333549 , 0.33332223, 0.3333229 ], dtype=float32)>
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
knn = KNeighborsClassifier(n_neighbors=5)
GridSearchCV(KNeighborsClassifier(), {'n_neighbors':[5,6,7,8,9,10]}) # 사용자가 지정한 파라미터를 반복문을 사용하는 것처럼 구해주는 방법
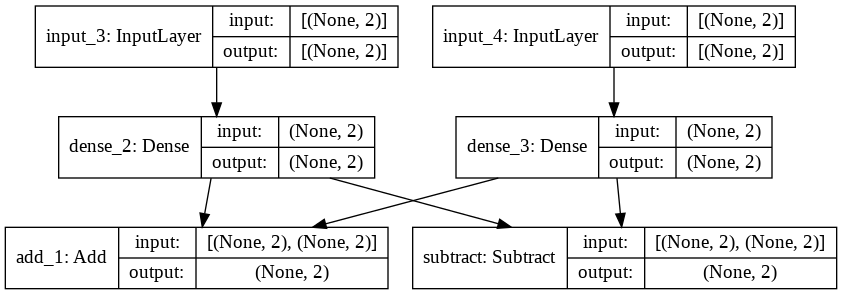
inputs = tf.keras.layers.InputLayer(input_shape=(2,)) # layer
x = tf.keras.layers.Dense(2)(inputs) # tensor를 인자로 받아야 한다
outputs = tf.keras.layers.Dense(2)(x)
# TypeError: Inputs to a layer should be tensors. Got: <keras.engine.input_layer.InputLayer object at 0x7f09f68a56d0>
# Sequential이 아닌 Model을 사용하는 것은 inputlayer를 표시하여서 조금더 복잡한 모델을 만들수있기 때문
se = tf.keras.models.Sequential([
tf.keras.layers.Dense(2),
tf.keras.layers.Dense(2)
])
inputs_ = tf.keras.Input(shape=(3,))
outputs = se(inputs_)
model = tf.keras.models.Model(inputs_, outputs)
model
# <keras.engine.functional.Functional at 0x7f73508eef10>
model.summary() # 모델 안에 모델을 넣지는 않지만 단순화 하기 위해서 모델 안에 sequential을 넣는 방법을 사용하는 경우는 많다
# Model: "model_2"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_6 (InputLayer) [(None, 3)] 0
# _________________________________________________________________
# sequential (Sequential) (None, 2) 14
# =================================================================
# Total params: 14
# Trainable params: 14
# Non-trainable params: 0
# _________________________________________________________________
X_train_bw.flatten().shape
# (47040000,)
# 그냥 하면 depth 까지 다 flat해짐
numpy에서 flatten은 모든 것을 1차원으로 만들어 준다
'__call__' in dir(tf.keras.layers.Flatten()) # instance => Function
# True
MLP를 만드는 다양한 방법
input_ = tf.keras.Input(shape=(28,28))
x = tf.keras.layers.Flatten()(input_) # 1차가 되었기 때문에 fully conntected 모델을 사용할 수 있다
x = tf.keras.layers.Dense(128, activation='relu')(x) # Dense에는 하나의 데이터가 1차원인 경우에만 집어 넣을 수 있다
x
# <KerasTensor: shape=(None, 128) dtype=float32 (created by layer 'dense_6')>
input_ = tf.keras.Input(shape=(28,28))
x = tf.keras.layers.Dense(128, activation='relu')(input_) # 2차원 값을 Dense에 넣으면 원하는 output을 만들어 낼 수 없다
x
# <KerasTensor: shape=(None, 28, 128) dtype=float32 (created by layer 'dense_7')>
Option1
input_ = tf.keras.Input(shape=(28,28))
x = tf.keras.layers.Flatten()(input_)
x = tf.keras.layers.Dense(2)(x)
x = tf.keras.layers.Activation('relu')(x) # 또는 x = tf.keras.layers.ReLU()(x)
# Activation layer를 따로 두는 이유는 Batch Normalization을 하기 위해서 이다
Option2
input_ = tf.keras.Input(shape=(28,28))
x = tf.keras.layers.Flatten()(input_)
x= tf.keras.layers.Dense(128, activation='relu')(x)
input_ = tf.keras.Input(shape=(28,28))
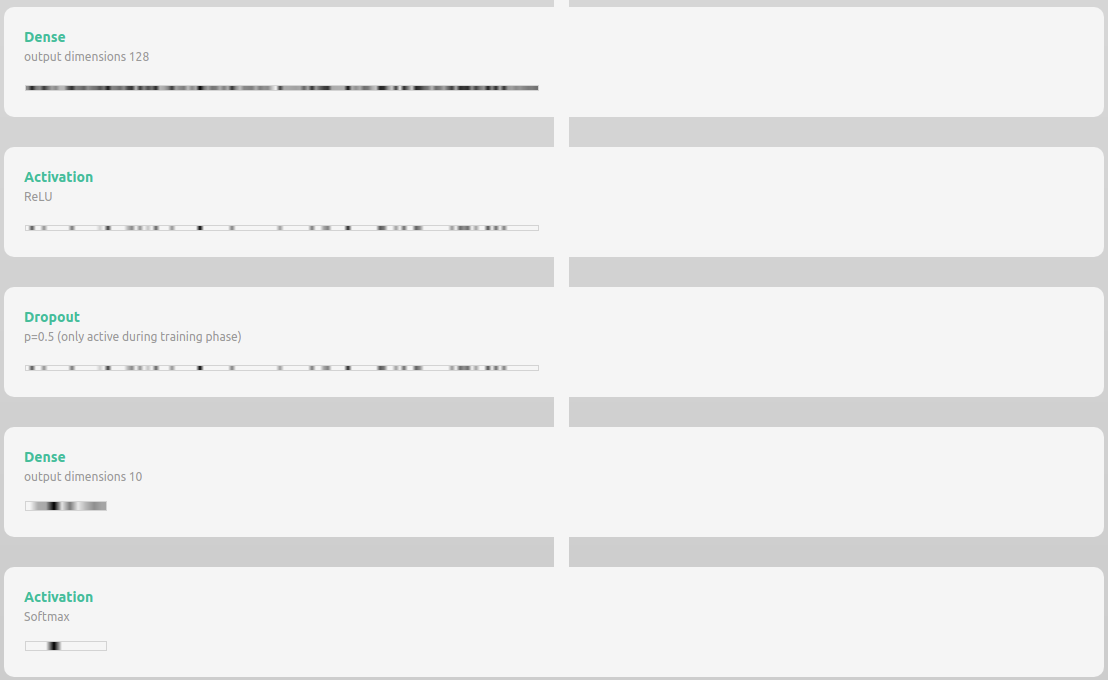
x = tf.keras.layers.Flatten()(input_)
x = tf.keras.layers.Dense(128)(x)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Dropout(0.2)(x)
output = tf.keras.layers.Dense(10, activation='softmax')(x)
# Batch Normalization과 상관 없기 때문에 관례상 마지막은 단축 표현을 쓴다
model = tf.keras.models.Model(input_, output)
model.summary() # param이 0인 경우 학습하지 않아도 되는 단순한 연산이다
# Model: "model_3"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# input_9 (InputLayer) [(None, 28, 28)] 0
# _________________________________________________________________
# flatten_1 (Flatten) (None, 784) 0
# _________________________________________________________________
# dense_8 (Dense) (None, 128) 100480
# _________________________________________________________________
# re_lu (ReLU) (None, 128) 0
# _________________________________________________________________
# dropout (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_9 (Dense) (None, 10) 1290
# =================================================================
# Total params: 101,770
# Trainable params: 101,770
# Non-trainable params: 0
# _________________________________________________________________