728x90
반응형
서울지역 대학교 위치.xlsx
0.01MB
Library.csv
0.03MB
경기도인구데이터.xlsx
0.01MB
경기도행정구역경계.json
0.11MB
import folium
seoul_map = folium.Map(location=[37.55, 126.98], zoom_start=12)
seoul_map.save('seoul.html')# tiles : 지도 스타일 설정
# openstreetmap, cartodbdark_matter, cartodbpositron, stamenterrain,
seoul_map2 = folium.Map(location=[37.55, 126.98], zoom_start=12, tiles = "openstreetmap")
seoul_map2.save('seoul2.html')import pandas as pd
import folium
df = pd.read_excel('서울지역 대학교 위치.xlsx', index_col=0,engine='openpyxl')
print(df.head())
위도 경도
KAIST 서울캠퍼스 37.592573 127.046737
KC대학교 37.548345 126.854797
가톨릭대학교(성신교정) 37.585922 127.004328
가톨릭대학교(성의교정) 37.499623 127.006065
감리교신학대학교 37.567645 126.961610
print(df.index)
Index(['KAIST 서울캠퍼스 ', 'KC대학교', '가톨릭대학교(성신교정)', '가톨릭대학교(성의교정)', '감리교신학대학교',
'건국대학교', '경기대학교 서울캠퍼스 ', '경희대학교 서울캠퍼스 ', '고려대학교', '광운대학교', '국민대학교',
'덕성여자대학교', '동국대학교', '동덕여자대학교', '명지대학교 서울캠퍼스 ', '삼육대학교', '상명대학교 서울캠퍼스 ',
'서강대학교', '서경대학교', '서울과학기술대학교', '서울교육대학교', '서울기독대학교', '서울대학교', '서울시립대학교',
'서울여자대학교', '서울한영대학교', '성공회대학교', '성균관대학교 서울캠퍼스 ', '성신여자대학교', '세종대학교',
'숙명여자대학교', '숭실대학교', '연세대학교', '육군사관학교', '이화여자대학교', '장로회신학대학교',
'중앙대학교 서울캠퍼스 ', '총신대학교', '추계예술대학교', '한국방송통신대학교', '한국성서대학교', '한국예술종합학교',
'한국외국어대학교', '한국체육대학교', '한성대학교', '한양대학교', '홍익대학교'],
dtype='object')seoul_map = folium.Map(location=[37.55, 126.98], zoom_start=12, tiles = "openstreetmap")
for name, lat, lng in zip(df.index, df.위도, df.경도) :
# marker = w지도 표시 객체 , popup 마커 표시내용\
# tooltip 마커에 커서가 들어온 경우 표시됨
folium.Marker([lat, lng], popup=name, tooltip=name).add_to(seoul_map)
seoul_map.save('seoul_colleges.html')seoul_map3 = folium.Map(location=[37.55, 126.98], zoom_start=12, tiles = "openstreetmap")
for name, lat, lng in zip(df.index, df.위도, df.경도) :
folium.CircleMarker([lat, lng], # 위경도
radius = 10, # 반지름
color = 'brown', # 색
fill= True, # 원 둘레 색
fillcolor= 'coral', # 원을 채우는 색
fill_opacity=0.7,# 투명도
popup=name
).add_to(seoul_map)
seoul_map3.save('seoul_colleges.html')# 아이콘 마커표시3
seoul_map4 = folium.Map(location=[37.55, 126.98], zoom_start=12, tiles = "openstreetmap")
for name, lat, lng in zip(df.index, df.위도, df.경도) :
folium.CircleMarker([lat, lng], # 위경도
popup=name,
# icon home, flag, bookmark, star
icon = folium.Icon(color = 'blue', icon='star')
).add_to(seoul_map)
seoul_map4.save('seoul_colleges.html')
library.csv
import pandas as pd
import folium
from folium import Marker
library = pd.read_csv('library.csv')
lib_map = folium.Map(location=[37.55, 126.98], zoom_start=12)
print(df1.head())
고유번호 구명 법정동명 산지여부 주지번 부지번 새주소명 시설명 \
0 21 구로구 구로3동 1 777 1 구로구 디지털로 27다길 65 2층 꿈마을 도서관
1 22 용산구 후암동 1 30 84 용산구 후암동 30-84 남산 도서관
2 23 중구 신당동 1 844 중구 다산로 32 남산타운 문화체육센터 어린이도서관
3 24 노원구 상계10동 1 686 노원구 온곡길 21 노원 정보도서관
4 25 노원구 중계3동 1 508 노원구 중계3동 508 노원 평생학습관
운영기관 설립주체 시설구분 개관일 면적 홈페이지주소 \
0 구로구 시설관리공단 구립도서관 2007-04-05 476.0 lib.guro.go.kr/dreamtown/
1 교육청도서관 1922-10-05 0.0 lib.sen.go.kr/lib_index.jsp
2 시설관리공단 구립도서관 2010-04-01 273.8 www.e-junggulib.or.kr
3 노원 교육복지재단 구립도서관 2006-02-15 6526.0 www.nowonlib.kr
4 교육청도서관 1990-05-08 0.0 lib.sen.go.kr/lib_index.jsp
print(df1.index)
연락처 생성일 경도 위도
0 830-5807 126.890115 37.487220
1 126.981375 37.552664
2 02-2280-8520 127.009297 37.549020
3 02-950-0029 127.064177 37.660927
4 127.067120 37.640120
RangeIndex(start=0, stop=123, step=1)color='blue'
# color='blue'
for name, lat, lng, kbn in zip(library['시설명'],library['위도'],library['경도'],library['시설구분']) :
if kbn == '구립도서관' :
color ='green'
else :
color = 'blue'
Marker(location = [lat, lng],
popup = kbn,
tooltip=name,
icon = folium.Icon(color=color,icon='bookmark')
).add_to(lib_map)
lib_map.save('library.html')markercluster 기능
# markercluster 기능
from folium.plugins import MarkerCluster
lib_map = folium.Map(location=[37.55, 126.98], zoom_start=12)
# add points to the map
mc = MarkerCluster()
# 데이터 중 한개 레코드씩 조회 row 따고 그중 하나씩
# _ 인덱스값 저장, 사용안하지만 절차상 피룡
for _, row in library.iterrows():
mc.add_child(
Marker(location = [row['위도'], row['경도']],
popup = row['시설구분'],
tooltip = row['시설명']
)
)
lib_map.add_child(mc)
lib_map.save('library2.html')# 경기도 인구데이텉와 위치정보를 가지고 지도 표시
import pandas as pd
import folium
import json
file_path = './경기도인구데이터.xlsx'
df = pd.read_excel(file_path, index_col = '구분', engine = 'openpyxl')
df.columns = df.columns.map(str)
geo_path = './경기도행정구역경계.json'try :
geo_data = json.load(open(geo_path, encoding = 'utf-8')) # 이게 안되면
except :
geo_data = json.load(open(geo_path, encoding = 'utf-8-sig')) # 이걸로
print(type(geo_data)) # dict
g_map = folium.Map(location=[37.5502, 126.982], zoom_start=9)
year = '2017'
# <class 'dict'># choropleth 클래스로 단계구분 표시
# fill_color BuGn, PuRd, BuPu, GnBu, OrRd, PuBu, PuBuGn
folium.Choropleth(geo_data = geo_data, # 지도 경계
data = df[year], # 표시하려는 데이터
columns = [df.index, df[year]],
fill_color = 'YlOrRd', # 면적 색깔
fill_opacity=0.7, # 면적 투명도
line_opacity=0.3, # 선 투명도
threshold_scale = [10000,100000,300000,500000,700000], # 색깔구분
key_on ='feature.properties.name', # 이름으로 구분
).add_to(g_map) # 에 추가하자
g_map.save('./gyonggi_population_'+year+'.html')gyonggi_population_2017.html
0.07MB
# json
import pandas as pd
import folium
import json
file_path = './US_Unemployment_Oct2012.csv'
df = pd.read_csv(file_path)
df.columns = df.columns.map(str)
geo_path = './us-states.json'try :
geo_data = json.load(open(geo_path, encoding = 'utf-8')) # 이게 안되면
except :
geo_data = json.load(open(geo_path, encoding = 'utf-8-sig')) # 이걸로
print(type(geo_data)) # dict
g_map = folium.Map(location=[37, -100], zoom_start=3, tiles="stamentoner")
# <class 'dict'># choropleth 클래스로 단계구분 표시
# fill_color BuGn, PuRd, BuPu, GnBu, OrRd, PuBu, PuBuGn
folium.Choropleth(geo_data = geo_data, # 지도 경계
data = df, # 표시하려는 데이터
columns = ['State','Unemployment'],
fill_color = 'YlGn', # 면적 색깔
fill_opacity=0.7, # 면적 투명도
line_opacity=0.3, # 선 투명도
threshold_scale = [0, 2, 4, 6, 8, 10, 12], # 색깔구분
legend_name='Unemployment Rate (%)',
key_on ='feature.id', # 이름으로 구분
).add_to(g_map) # 에 추가하자
g_map.save('./US_Unemployment_Oct_'+'11'+'.html')US_Unemployment_Oct2012.csv
0.00MB
import pandas as pd
import folium
import json
file_path='US_Unemployment_Oct2012.csv'
df=pd.read_csv(file_path)
df.head()
df.columns=df.columns.map(str)
geo_path='us-states.json'
try:
geo_data=json.load(open(geo_path,encoding='utf-8'))
except:
geo_data=json.load(open(geo_path,encoding='utf-8-sig'))
print(type(geo_data))
g_map = folium.Map(location=[37,-102],zoom_start=3)
folium.Choropleth(geo_data=geo_data, #지도 경계
data=df,
columns=['State','Unemployment'], #열 지정
fill_color='YlGn',fill_opacity=0.7,line_opacity=0.3,
legent_name="Unemployment Rate (%)",
key_on='feature.id',
).add_to(g_map)
g_map.save('US_Unemployment.html')
crime_in_Seoul_final.csv
0.01MB
skorea_municipalities_geo_simple.json
0.01MB
import pandas as pd
import folium
import json
file_path='crime_in_Seoul_final.csv'
df=pd.read_csv(file_path,index_col='구별')
df.head()
df.columns=df.columns.map(str)
geo_path='skorea_municipalities_geo_simple.json'
try:
geo_data=json.load(open(geo_path,encoding='utf-8'))
except:
geo_data=json.load(open(geo_path,encoding='utf-8-sig'))
print(type(geo_data))
g_map = folium.Map(location=[37.5502,126.978],zoom_start=10)
typ='강간'
folium.Choropleth(geo_data=geo_data,
data=df[typ],
columns=[df.index,df[typ]],
fill_color='YlOrRd',fill_opacity=0.7,line_opacity=0.3,
key_on='feature.properties.name',
).add_to(g_map)
g_map.save('crime_Seoul3.html')
반응형
'Data_Science > Data_Analysis_Py' 카테고리의 다른 글
| 12. titanic (2 (0) | 2021.10.26 |
|---|---|
| 11. 행정안전부, 연령별 인구 분석 (0) | 2021.10.26 |
| 9. tips || '21.06.28. (0) | 2021.10.26 |
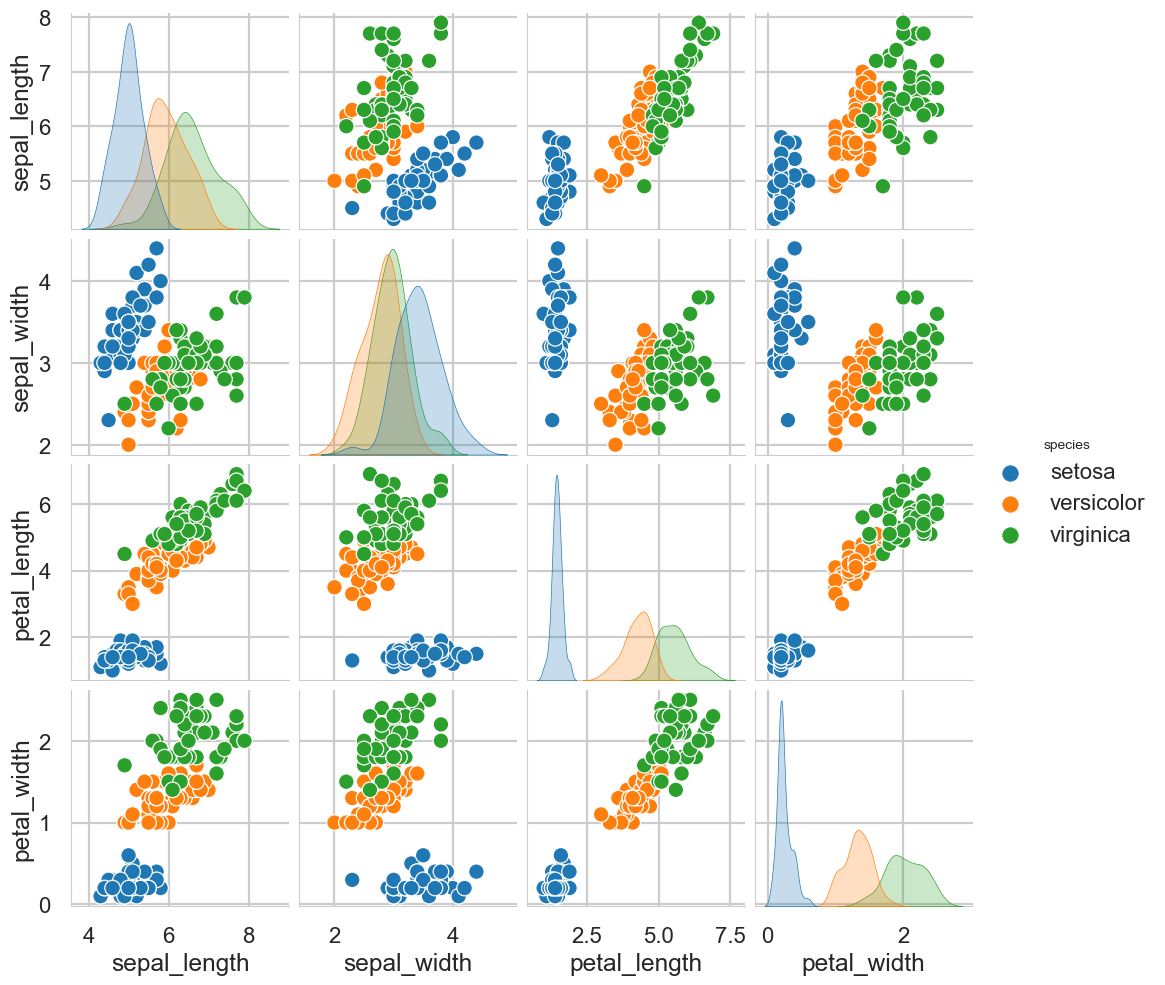
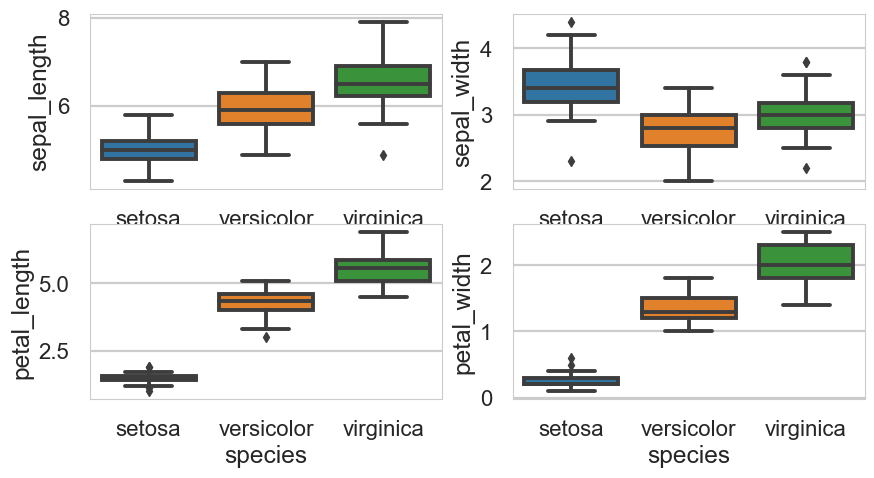
| 8. iris || '21.06.28. (0) | 2021.10.26 |
| 7. folium || '21.06.24. (0) | 2021.10.26 |