Tensorflow는 numpy를 기반으로 autograd(자동 미분)을 지원하고 neural network에서 자주 사용하는 기능들을 지원해주는 라이브러리이다
뿐만 아니라 numpy는 연산이 복잡해지면 속도가 느려지는데 gpu연산이 가능하도록 지원하도록 만들어졌기 때문에 훨씬 효율적인 NN 프로그래밍을 도와준다 (GPU사용시 50배 이상 속도가 빨라진다)
import tensorflow as tf
tf.__version__ # 2.3버전 이후에 많이 바뀌었기 때문에 본 수업은 2.3버전 이상에서 진행된다
# '2.6.0'
tf.version.VERSION
# '2.6.0'
tf.executing_eagerly()
# True
Neural Network를 구성하는 6가지 방법
1.tf.keras.models.Sequential # 쉽지만 쓸모없는 방식
2.tf.keras.models.Model# 전문가적인 방식
3.subclass (tf.keras.models.Model) # 전문가적인 방식
4.tf.estimator.
5.tf.nn.
6.tf.Module# Meta class 방식
2,3번방식을집중적으로알아볼것이다
a = tf.constant([1,2,3]) # Tensor라고 나오면 상수 / immutable
b = tf.Variable([1,2,3]) # Varaible은 이름이 있다 / mutable => 가중치를 갱신할때 사용한다
a
# <tf.Tensor: shape=(3,), dtype=int32, numpy=array([1, 2, 3], dtype=int32)>
b
# <tf.Variable 'Variable:0' shape=(3,) dtype=int32, numpy=array([1, 2, 3], dtype=int32)>
b.assign([3,4,5])
# <tf.Variable 'UnreadVariable' shape=(3,) dtype=int32, numpy=array([3, 4, 5], dtype=int32)>
b
# <tf.Variable 'Variable:0' shape=(3,) dtype=int32, numpy=array([3, 4, 5], dtype=int32)>
tf.debugging.set_log_device_placement(True) # gpu연산을 하는지 확인할 수 있다 / colab에서 사용시 Runtime type을 GPU로 바꾼후 확인해 보세요
a = tf.constant([1,2,3])
Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
a + a
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# <tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 4, 6], dtype=int32)>
b = tf.Variable([1,2,3])
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
b+b
# Executing op ReadVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op ReadVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# <tf.Tensor: shape=(3,), dtype=int32, numpy=array([2, 4, 6], dtype=int32)>
d = tf.constant([3,4,5])
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
'__array_priority__' in dir(d) # numpy와 호환된다
# True
d.numpy()
# array([3, 4, 5], dtype=int32)
import numpy as np
a = tf.constant([1,2,3])
b = tf.Variable([1,2,3])
c = np.array([1,2,3])
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op DestroyResourceOp in device /job:localhost/replica:0/task:0/device:CPU:0
%timeit np.add(a,a) # numpy method에 tensor를 넣어도 된다 / tensor => numpy 변환 후 numpy operation을 한다 / 이때는 resource가 적게 들어간다
# The slowest run took 24.50 times longer than the fastest. This could mean that an intermediate result is being cached.
100000 loops, best of 5: 9.62 µs per loop
np.add(b,b)
# Executing op ReadVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op Identity in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op ReadVariableOp in device /job:localhost/replica:0/task:0/device:CPU:0
# Executing op Identity in device /job:localhost/replica:0/task:0/device:GPU:0
# array([2, 4, 6], dtype=int32)
%timeit tf.add(c,c) # tensor연산에 numpy를 넣으면 gpu를 사용하여 연산한다 / numpy에서 tensor로 타입을 바꾼 후 tensor operation을 한다 / 이때는 resource가 많이 들어간다
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
...
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# 100 loops, best of 5: 7.22 ms per loop
%timeit tf.add(a,a) # 데이터 양이 많다면 텐서데이터로 텐서 연산할 때가 가장 빠르다
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
...
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op AddV2 in device /job:localhost/replica:0/task:0/device:GPU:0
# 100 loops, best of 5: 2.42 ms per loop
numpy데이터를 tensor연산했을때가 tensor데이터를 numpy연산 했을 때 보다 훨씬 속도가 느리다
wrapper backend: theano interface: keras keras는 theano의 단점을 보완했다
- theory를 구현할 수 있게 문법을 만들었다 (이론과 실제의 간극을 줄였다)
theano다음으로 tensorflow가 출현했다
keras는 theano/tensorflow/cntk(microsoft)로 쉽게 전환 할 수 있도록 보완했다
tensorflow다음으로 torch(facebook)가 출현했다
keras만든 사람을 google로 스카웃 tensorflow 1.6부터 keras를 포함 시켰다
tensorflow 2.0부터는 tensorflow 1version 없애버렸다
tensorflow 2.6부터는 keras/tensorflow를 분리시켰다
backend개념은 keras에서 사용되는 개념이다.
즉, keras는 theano/tensorflow/cntk로 구동할 수 있고 껍데기 interface는 keras를 사용할 수 있다
model = tf.keras.models.Sequential() # 함성함수 껍데기
model2 = tf.keras.models.Model()
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
issubclass(model.__class__, model2.__class__) # model이 model2의 subclass이다
# Ture
model.__class__.__bases__ # 부모는 Functional
# (keras.engine.functional.Functional,)
model.__class__.mro()
# [keras.engine.sequential.Sequential,
keras.engine.functional.Functional,
keras.engine.training.Model,
keras.engine.base_layer.Layer,
tensorflow.python.module.module.Module,
tensorflow.python.training.tracking.tracking.AutoTrackable,
tensorflow.python.training.tracking.base.Trackable,
keras.utils.version_utils.LayerVersionSelector,
keras.utils.version_utils.ModelVersionSelector,
object]
model2.__class__.__bases__
# (keras.engine.base_layer.Layer, keras.utils.version_utils.ModelVersionSelector)
sample = np.array([[1,2]])
# layer 추가 방법1 (한개씩)
model.add(tf.keras.layers.Dense(2))
# layer 추가 방법2 (한꺼번에)
model2 = tf.keras.models.Sequential([
tf.keras.layers.Dense(2)
])
#
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op DestroyResourceOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op DestroyResourceOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op DestroyResourceOp in device /job:localhost/replica:0/task:0/device:GPU:0
model(sample) # Feed foward(predict) / 결과가 tensor / tensor연산 / 합성함수 방식 / 이론과 현실의 간극을 줄이기 위한 방법
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
...
# Executing op ReadVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op BiasAdd in device /job:localhost/replica:0/task:0/device:GPU:0
# <tf.Tensor: shape=(1, 2), dtype=float32, numpy=array([[ 0.44565853, -0.7990122 ]], dtype=float32)>
model.predict(sample) # numpy연산 / method 방식
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op RangeDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op RepeatDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op MapDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op PrefetchDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op FlatMapDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op TensorDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op RepeatDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op ZipDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op ParallelMapDatasetV2 in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op OptionsDataset in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op AnonymousIteratorV2 in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op MakeIterator in device /job:localhost/replica:0/task:0/device:CPU:0
Executing op __inference_predict_function_2745 in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op Identity in device /job:localhost/replica:0/task:0/device:GPU:0
Executing op DeleteIterator in device /job:localhost/replica:0/task:0/device:CPU:0
array([[ 0.44565853, -0.7990122 ]], dtype=float32)
model1.add(tf.keras.layers.Dense(2)) # 자동적으로 array형태로 맞춰준다 / input shape을 지정하지 않아도 된다
model1.summary() # input shape을 지정하지 않았기 때문에 어떤 모델인지 아직 불명확하다
# raise ValueError('This model has not yet been built. '
# ValueError: This model has not yet been built. Build the model first by calling `build()` or calling `fit()` with some data, or specify an `input_shape` argument in the first layer(s) for automatic build.
model1.built # 아직 만들어지지 않았다
# False
model1(sample) # sample 데이터구조를 받았기 때문에 자동적으로 만들어진다
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
# Executing op _EagerConst in device /job:localhost/replica:0/task:0/device:GPU:0
...
# Executing op BiasAdd in device /job:localhost/replica:0/task:0/device:GPU:0
# <tf.Tensor: shape=(1, 2), dtype=float32, numpy=array([[1.4473007, 1.210985 ]], dtype=float32)>
model1.summary()
# Model: "sequential_2"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense_3 (Dense) (1, 2) 6
# _________________________________________________________________
# dense_4 (Dense) (1, 2) 6
# =================================================================
# Total params: 12
# Trainable params: 12
# Non-trainable params: 0
# _________________________________________________________________
sample_test = np.array([[1,2]])
model_test1 = tf.keras.models.Sequential()
model_test1.add(tf.keras.layers.Dense(2, input_shape=(2,))) # 데이터가 몇개가 들어올지 지정되지 않는다 / input shape은 data sample 1개의 모양이다
# Executing op VarHandleOp in device /job:localhost/replica:0/task:0/device:GPU:0
...
# Executing op AssignVariableOp in device /job:localhost/replica:0/task:0/device:GPU:0
model_test1.built
# True
model_test1.summary() # None은 데이터의 갯수 상관없이 받을 수 있다는 의미이다 / input shape을 지정하면 데이터의 갯수 상관없이 받을 수 있는 형태로 만들어진다
# Model: "sequential_7"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# dense_11 (Dense) (None, 2) 6
# =================================================================
# Total params: 6
# Trainable params: 6
# Non-trainable params: 0
# _________________________________________________________________
가정이 많아지면 많아질 수록 가정을 만족하는 데이터에 대해서는 성능이 좋아지지만, 일반성은 떨어진다
즉, 잘 정제된 데이터를 학습해서 좋은 데이터에서는 성능이 좋지만, 정제되지 않은 현실 데이터에 적용하기에는 좋지 않은 모델이 만들어질 수 있다
import tensorflow as tf
import matplotlib.pyplot as plt
(X_train,y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
plt.imshow(X_train[0], cmap='gray') # 패턴이 뚜렷하게, 크기를 일치하는 가정을 둔 사례
대체적으로 성능 좋은 알고리즘 (대세)
1980 - 1990 ANN
1990 - 2000 SVM
2000 - 2010 Ensemble (Random Forest)
- Structured data => Boosting
- XGBoosting, LightGBM
- ETC (Deep Learning)
데이터가 작을 때에는 SVM부터 사용하는 것이 좋다
왜냐하면 Ensemble, Boosting, Deep Learning은 데이터가 많을 때라는 가정이 있어야 성능이 좋기 때문이다
Neural Network
Neural network는 뉴런에서 영감을 얻어 데이터를 통해 스스로 학습이 가능하도록 설계된 알고리즘, 네트워크 또는 모델이라고 한다
모델의 구조를 먼저 정하고
그 구조에 있는 파라미터를 찾는 모델 방식을 가진다
구조도 학습을 통해서 알아낼 수 있다 (NAS/Neural Architecture Search)
Hypothesis
가설은 어떤 현상을 해결하기 위한 함수이고 사실과 비슷하다고 믿는 함수이다
Model
머신러닝에서는 가설 = 모델이다
정의 자체에서 모델은 항상 틀릴 수 있다
모델은 시스템 관점에서 머신러닝 알고리즘을 사용해서 데이터로 학습시킨 것을 머신러닝 모델이라고 한다
※ scikit-learn에서 학습 안된 알고리즘을 estimator라고 한다
모델의 4가지 관점
1. 수학적으로 표현할 수 있어야 한다
2. 그림 또는 그래프로 표현할 수 있어야 한다
3. 통계치를 통해서 표현할 수 있어햐 한다
4. 코드를 통해서 표현할 수 있어야 한다
모델 분류 기준들
1. Linear vs Nonlinear
- Linear는 aX+b에서 a와 b를 찾는데 집중한다
- Nonlinear는 회귀식이 비선형 함수로 나타내는 경우를 말한다
2. Generative vs Discriminative
- Generative는 입력값과 결과값이 주어질때, 일정한 분포 규칙속에 존재한다는 가정을 하는 모델
- Discriminative는 입력 데이터가 있을 때 label data를 구별해내는 모델
3. Black box vs Descriptive
- Black box는 설명 불가능
- Descriptive는 설명 가능
4. First-principle vs Data-driven
- First-principle은 원리, 규칙에 기반한 모델인가
- Data-driven은 데이터에 기반한 모델인가
5. Stochastic vs Deterministic
- Stochastic는 확률론적인 방법
- Deterministic 결정론적인 방법
6. Flat vs Hierarchical
7. Parametric vs Non-parametric
- Parametric는 고정된 개수의 파라미터들을 학습하여 튜닝하는 것
- Non-parametric는 학습해서 튜닝할 파라미터가 명시적으로 존재하지 않거나 정확히 셀 수 없는 경우
Data modeling vs Algorithmic Modeling
Data modeling
- 데이터를 바탕으로 파라미터를 찾는 것에 집중하는 모델
- 데이터를 해당 모델에 얼마나 잘 적합시키는 가에 초점이 있다
- 모델 자체를 가정하기 때문에 모델이 잘 못될 경우 잘 못된 결과를 도출 할 수 있다
Algorithmic modeling
- 알고리즘을 모르는 상태에서 데이터를 통해 모델을 새로 만드는 방법
Perceptron
뉴런을 모방한 알고리즘 또는 모델
Perceptron과 linear model의 차이점은 선형 함수의 기울기와 bias를 찾는 방법이 다르다
perceptron은 delta rule에 의해서 학습을 한다
delta rule은 기대값과 실제값의 차이를 줄여 나가는 방식으로 싱글 레이어 퍼셉트론에서 인공 뉴런들의 연결 강도를 갱신하는데 쓰인다
from sklearn.linear_model import Perceptron
per = Perceptron() # linear model
per.fit(X_train, y_train)
# Perceptron(alpha=0.0001, class_weight=None, early_stopping=False, eta0=1.0,
# fit_intercept=True, max_iter=1000, n_iter_no_change=5, n_jobs=None,
# penalty=None, random_state=0, shuffle=True, tol=0.001,
# validation_fraction=0.1, verbose=0, warm_start=False)
per.score(X_test, y_test)
# 0.8947368421052632
MLP(Multi Layer Perceptron)
MLP는 perceptron를 쌓기 위해서 Layer 개념을 도입하고 여러 layer를 연결한 형태를 말한다
neural network는 기본적으로 fully connected여야 한다
Memorization Capacity
Layer가 많으면 많을 수록 성능이 좋아진다
그러나 ML에서 feature처럼 layer가 많으면 많을 수록 데이터가 많이 필요하다
전통적인 머신러닝 알고리즘에서는 데이터가 아무리 많아도 더 이상 성능이 올라가지 않는 plateau라는 현상이 생긴다
Universal Approximation Theorem
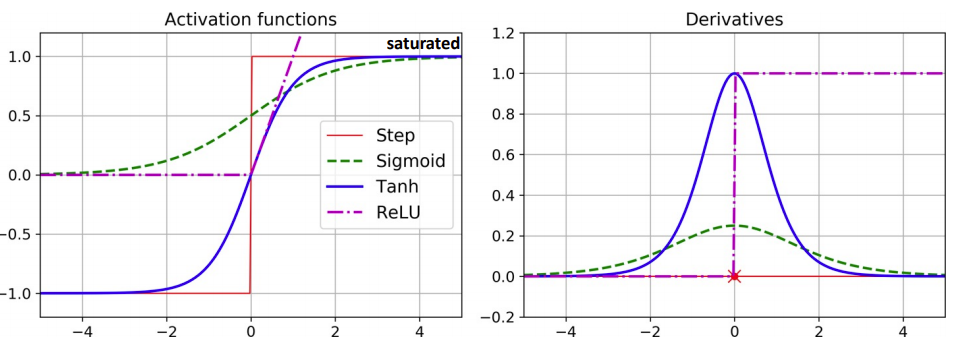
이론적으로 activation 함수가 비선형 일때 레이어가 많으면 어떠한 형태의 함수도 만들어 낼 수 있다
따라서 어떠한 데이터 셋도 분류 할 수 있다
단, activation function을 sigmoid나 tanh같은 함수를 사용하면 gradient vanishing현상이 생긴다
iris.corr() # petal_length, petal_width 두 가지 feature가 서로 연관되어 있기 때문에 둘 중 하나를 택한다
sepal_length sepal_width petal_length petal_width
sepal_length 1.000000 -0.117570 0.871754 0.817941
sepal_width -0.117570 1.000000 -0.428440 -0.366126
petal_length 0.871754 -0.428440 1.000000 0.962865
petal_width 0.817941 -0.366126 0.962865 1.000000
Wrapper
알고리즘과 데이터의 feature에 따른 경우의 수를 고려하여 계산하는 방식
from sklearn.feature_selection import RFE # Recursive feature extraction
from sklearn.linear_model import LogisticRegression
rfe = RFE(LogisticRegression(), n_features_to_select=2) # 4개 중에 2개 선택 (iris feature가 4개 이기 때문에)
rfe.fit_transform(iris.iloc[:,:-1], iris.species) # fit_transform
from sklearn.decomposition import PCA
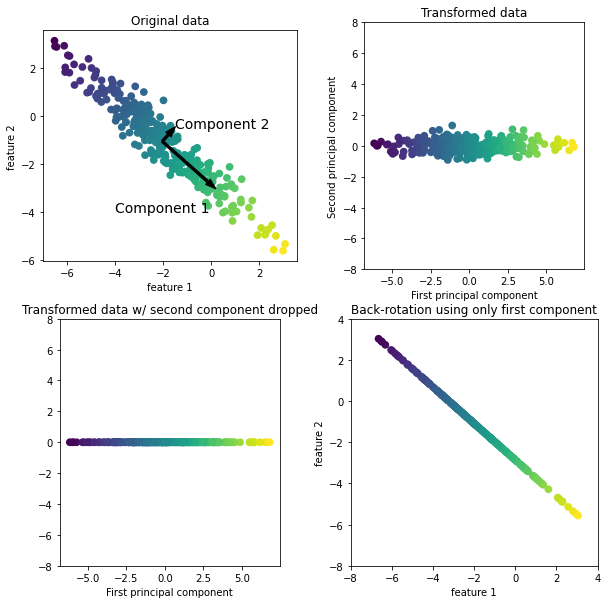
pca = PCA(2) # 2차원으로 줄인다
pca.fit_transform(iris.iloc[:,:-1], iris.species) # 4차원 -> 2차원 / 공간이 왜곡 되었다
# array([[-2.68412563, 0.31939725],
[-2.71414169, -0.17700123],
[-2.88899057, -0.14494943],
[-2.74534286, -0.31829898],
Feature selection vs Dimension reduction
Feature selection은 데이터 값을 그대로 유지하면서 feature를 축소 했지만,
Dimension reduction은 데이터 값을 변형하면서 차원을 축소 한다 => 공간을 왜곡시킨다
!pip install mglearn
import mglearn
mglearn.plot_pca.plot_pca_illustration() # 차원이 축소 되어도 의미를 잃지 않았다 / 고차원의 특성이 저차원에서도 유지가 되었다 / manifold
Manifold
고차원의 데이터를 공간상에 표현하면 각 데이터들은 점의 형태로 찍혀지는데,
이러한 점들을 잘 아우르는 subspace를 manifold라고 한다
Path
import cv2
import os # 운영체제별로 결과가 상이할 수 있다
from pathlib import Path # 운영체제 별로 상이하지 않게 범용적으로 사용 가능
os.listdir('flower_photos/daisy')[:10]
['7410356270_9dff4d0e2e_n.jpg',
'7568630428_8cf0fc16ff_n.jpg',
'10770585085_4742b9dac3_n.jpg',
'4286053334_a75541f20b_m.jpg',
'8759177308_951790e00d_m.jpg',
'4131565290_0585c4dd5a_n.jpg',
'8710109684_e2c5ef6aeb_n.jpg',
'3504430338_77d6a7fab4_n.jpg',
'2612704455_efce1c2144_m.jpg',
'8021540573_c56cf9070d_n.jpg']
path = 'flower_photos/daisy'
images = [cv2.imread(os.path.join(path,i)) for i in os.listdir(path)] # os.listdir : 특정 디렉토리를 리스트로 만들어 준다
!pwd
# /content/drive/My Drive/Colab Notebooks/고급시각반 정리/flower_photos
path = Path('flower_photos/daisy') # path 객체로 불러온다
images = [cv2.imread(str(i)) for i in path.iterdir()]
len(images)
# 633
Pattern
path 객체는 pattern을 사용할 수 있다
import glob # 패턴을 활용할 수 있는 패키지
image = [cv2.imread(i) for i in glob.glob('flower_photos/daisy/*.jpg')] # glob 모듈의 glob 함수는 사용자가 제시한 조건에 맞는 파일명을 리스트 형식으로 반환한다.
len(image)
# 633
import imageio
imageio.volread(path) # s mode를 알아야 한다?
path = 'flower_photos/daisy'
imageio.mimread(path, format='jpg') # multiple image를 불러들일 수 있다. 단, jpeg는 multi-image 불러들일 수 없다
# RuntimeError: Format JPEG-PIL cannot read in mode 'I'
from skimage.io import imread_collection
imc = imread_collection('flower_photos/daisy/*.jpg') # 패턴을 정확히 이해해야 한다
imc.files[:10]
['flower_photos/daisy/5547758_eea9edfd54_n.jpg',
'flower_photos/daisy/5673551_01d1ea993e_n.jpg',
'flower_photos/daisy/5673728_71b8cb57eb.jpg',
'flower_photos/daisy/5794835_d15905c7c8_n.jpg',
'flower_photos/daisy/5794839_200acd910c_n.jpg',
'flower_photos/daisy/11642632_1e7627a2cc.jpg',
'flower_photos/daisy/15207766_fc2f1d692c_n.jpg',
'flower_photos/daisy/21652746_cc379e0eea_m.jpg',
'flower_photos/daisy/25360380_1a881a5648.jpg',
'flower_photos/daisy/43474673_7bb4465a86.jpg']
w = os.walk('flower_photos/daisy')
for _, _, files in os.walk('flower_photos/daisy'):
for i in range(10):
print(files[i])
7410356270_9dff4d0e2e_n.jpg
7568630428_8cf0fc16ff_n.jpg
10770585085_4742b9dac3_n.jpg
4286053334_a75541f20b_m.jpg
8759177308_951790e00d_m.jpg
4131565290_0585c4dd5a_n.jpg
8710109684_e2c5ef6aeb_n.jpg
3504430338_77d6a7fab4_n.jpg
2612704455_efce1c2144_m.jpg
8021540573_c56cf9070d_n.jpg
import tensorflow as tf
img = tf.keras.preprocessing.image_dataset_from_directory('flower_photos/')
# Found 3670 files belonging to 5 classes.
type(img)
# tensorflow.python.data.ops.dataset_ops.BatchDataset
for i in img:
print(i[0].numpy()) # float형태로 한꺼번에 불러온다 단, 범용적으로 사용하지 못하는 단점이 있다
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.neural_network import MLPClassifier, MLPRegressor
from sklearn.svm import SVC, SVR
from sklearn.neighbors import KNeighborsClassifier
t = cross_val_score(dt, data.data, data.target, cv = 10)
t
# array([0.79444444, 0.86666667, 0.85 , 0.8 , 0.78333333,
# 0.87222222, 0.90555556, 0.81005587, 0.81564246, 0.82681564])
t.mean() # 전처리가 잘 되어 있기 때문에 성능이 좋다
# 0.8324736188702669
data.data = data.data.astype('float32')
knn1 = cv2.ml.KNearest_create()
knn1.train(data.data, cv2.ml.ROW_SAMPLE ,data.target) # 데이터가 연속이라는 가정을 두고 학습을 해야 하기 때문에 데이터 타입이 float이어야 한다
# True
knn2.predict(data.data[3][np.newaxis])
# array([3])
%timeit knn1.findNearest(data.data, 5)
# 10 loops, best of 5: 148 ms per loop
%timeit knn2.predict(data.data)
# 1 loop, best of 5: 417 ms per loop
- RPN Bounding Box Regression은 Anchor Box를 Reference로 이용하여 Ground truth와 예측 Bbox의 중심좌표 x, y 그리고 w, h 의 차이가 Anchor box와 Ground Truth 간의 중심 좌표 x,y,w,h 차이와 최대한 동일하게 예측 될 수 있어야 함.