from sklearn.model_selection import train_test_split # 2-way / 3-way는 train_test_split을 두 번 하면 된다
Modeling
모델이란 수많은 데이터를 통해 패턴을 발견하거나 예측을 수행하는 알고리즘의 표현식이다
따라서 모델링은 그러한 알고리즘을 만들어 내는 과정을 말한다
모델을 잘 만들기 위해서 모델링하기 전 데이터에 대한 이해가 필요하다 => EDA를 한다
모델링 하기 전에 알아둬야 할 키워드
1. Ad-hoc : 특별한 목적을 가진 것
- 데이터에 따라서 달라진다
- 일반적이지 않다
2. No free lunch <----> Master algorithm
- 공짜 점심은 없다
from sklearn.model_selection import cross_val_score # 데이터 양이 적을때 사용하는 방법
re # 데이터 양이 적을때 사용하는 방법
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape = (28,28)) # (28,28)인 2차원으로 만들어 준다
])
X_train[0].shape # 2차원 데이터
# (28, 28)
X_train.dtype
# dtype('uint8')
data = model(X_train) # 묵시적으로 데이터 타입이 uint8에서 float32로 바뀌었다 / 미분해야 하기 때문에 float타입이어야 한다
model.fit() # class_weight => 클래스에 가중치를 줌으로써 불균등한 데이터의 문제를 해결할 수 있다
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier
from sklearn.svm import SVC
Ir = LogisticRegression() # 가정이 성립되면 전통적인 머신러닝 알고리즘 사용 가능하다
Ir.fit(data.numpy(), y_train)
Ir.predict(X_test[0].reshape(1,-1))
y_test[0]
# 7
svm = SVC()
svm.fit(data.numpy(), y_train)
본 수업 용어 규칙
전통적인 머신러닝 모델 = end to end (feature extraction + model)이 아닌 모델
여기서 end to end 모델은 input이 들어가서 output이 나오는 과정을 오로지 데이터에 의존해서 찾아내는 모델을 말한다
end to end 모델이 성능이 좋을때가 많지만 충분한 학습 데이터가 없다면 굉장히 성능이 떨어지는 모델이 될 수 있다
그리고 end to end 모델은 중간 과정을 설명할 수 없기 때문에 중간 과정을 설명해야 하는 중요한 문제가 발생하는 부분에서는 사용하기가 쉽지 않다
i.i.d (independent identically distributed)
독립 항등 분포 column을 바꿔도 의미가 유지가 되어야 한다
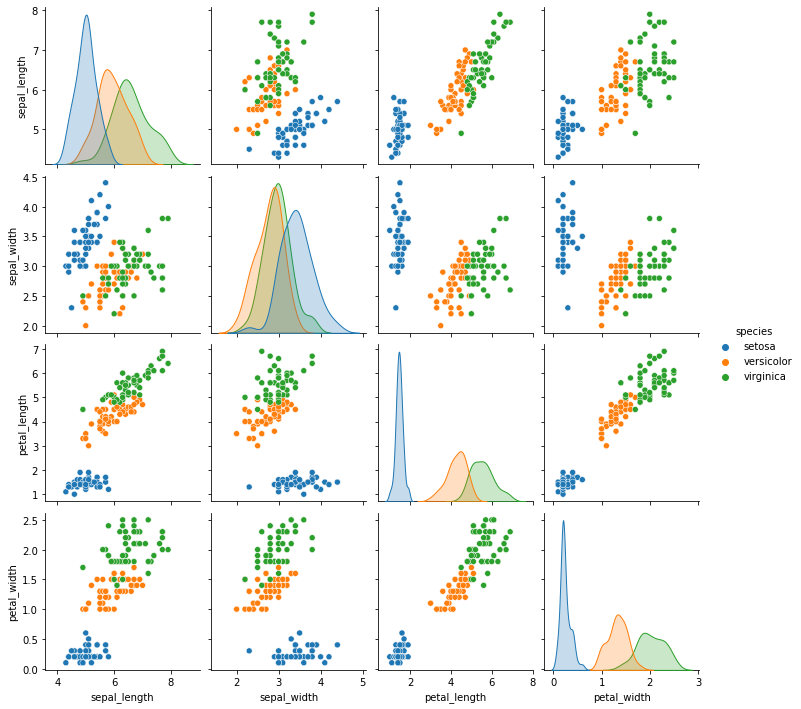
import seaborn as sns
iris = sns.load_dataset('iris')
이미지는 column이 바뀌면 의미가 유지되지 않는다
그래서 전통적인 방식의 머신러닝으로 이미지 데이터 사용하기 쉽지 않다
단, 가설(가정)을 통해서 가능하게 할 수 있다
Assumption
이미지 데이터를 사용하여 전통적인 머신러닝 방식 해결하려면 가정이 필요하다
가정이 잘못 되면 모든 것이 잘 못 될 경우가 있다
이미지 데이터를 사용할 경우 data leakage문제가 발생하지 않는다 라는 가정을 갖고 학습을 하게 되면 전통적인 머신러닝 방식으로도 사용할 수 있다
가정을 많이 할 수록 사용할 수 있는 것이 한정적이게 된다
data leakage 문제: 학습 데이터 밖에서 유입된 데이터가 모델을 만드는데 사용되어 overfitting이 되거나 underfitting이 되는 경우를 말한다
%timeit im*im
# 1000 loops, best of 5: 202 µs per loop
%timeit im**2
# 1000 loops, best of 5: 227 µs per loop
cv2.useOptimized() # opencv연산에 최적화 되어 있다
# True
%timeit cv2.medianBlur(im, 49) # 최적화 되어 있을 때 (최적화 되어 있을 때 일반적으로 20% 빠르다 / colab에서 medianBlur연산은 최적화 해도 그렇게 빠르지 않다)
# 10 loops, best of 5: 37.5 ms per loop
cv2.setUseOptimized(False)
cv2.useOptimized()
# False
%timeit cv2.medianBlur(im, 49) # 최적화 되지 않을 때
# 10 loops, best of 5: 37.8 ms per loop
cv2.setUseOptimized(True)
cv2.useOptimized()
# True
%timeit im*im*im
# The slowest run took 20.40 times longer than the fastest. This could mean that an intermediate result is being cached.
# 1000 loops, best of 5: 292 µs per loop
%timeit im**3 # 연산량이 많아지면서 im*im*im연산보다 im**3이 훨씬 느려졌다
# 100 loops, best of 5: 3.24 ms per loop
EqualizeHist
im = cv2.imread('people.jpg', 0)
im2 = cv2.equalizeHist(im)
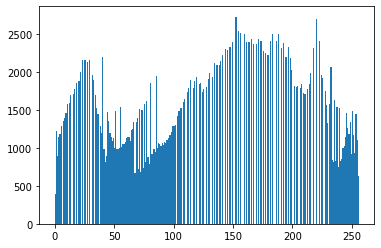
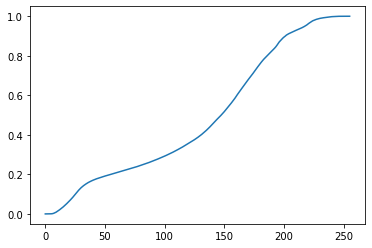
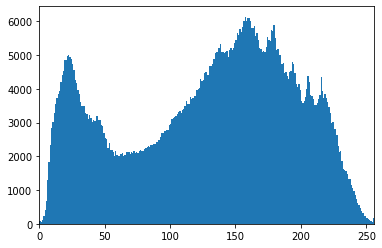
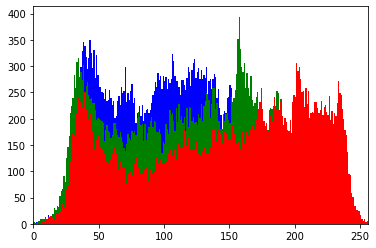
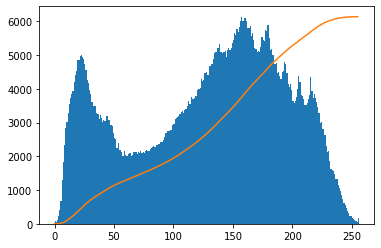
plt.hist(im2.ravel(), 256,[0,256]); # 정규 분포 처럼 분포를 균일하게 만들어 준다
plt.imshow(cv2.equalizeHist(im), cmap='gray') # 평탄화 => contrast가 낮아진다 => 분포가 균일해진다 => 밝고 어두운 정도가 구분하기 힘들어진다
from skimage.exposure import cumulative_distribution
len(cumulative_distribution(im))
# 2
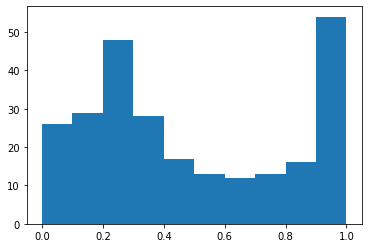
y, x = cumulative_distribution(im)
plt.hist(y);
# (array([ 26., 29., 48., 28., 17., 13., 12., 13., 16., 54.]),
# array([ 2.74348422e-05, 1.00024691e-01, 2.00021948e-01,
# 3.00019204e-01, 4.00016461e-01, 5.00013717e-01,
# 6.00010974e-01, 7.00008230e-01, 8.00005487e-01,
# 9.00002743e-01, 1.00000000e+00]),
# <a list of 10 Patch objects>)
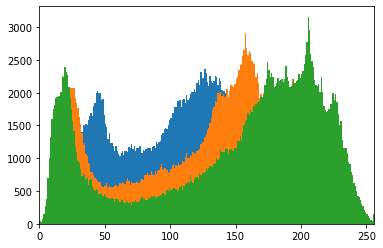
# 각각 점의 컬러 분포
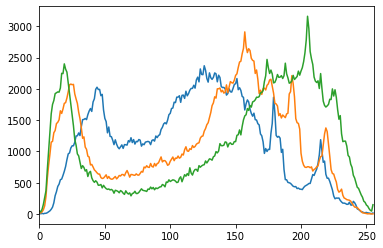
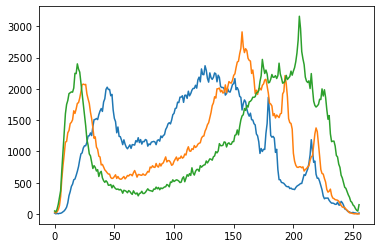
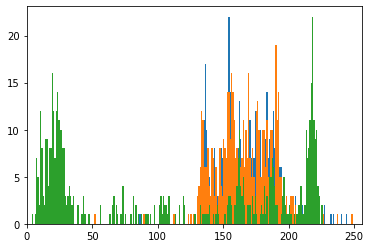
plt.hist(im[...,0].ravel(), 256, [0, 256]); # B
plt.hist(im[...,1].ravel(), 256, [0, 256]); # G
plt.hist(im[...,2].ravel(), 256, [0, 256]); # R
plt.xlim([0,256])
np.bincount(np.arange(5)) # 각각 몇개 있는지 세는 함수
# array([1, 1, 1, 1, 1])
np.bincount(np.array([0,1,1,3,2,1,7]))
# array([1, 3, 1, 1, 0, 0, 0, 1])
from itertools import count, groupby
t = groupby([1,1,1,2,2])
b = count()
next(b)
# 3
next(t) # 그룹으로 묶어서 몇개 있는지 확인
# (2, <itertools._grouper at 0x7fa251080ad0>)
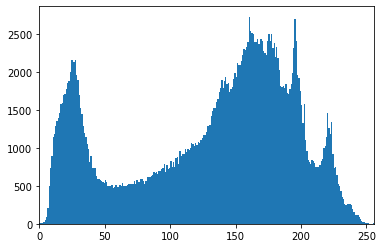
얼굴부분 crop해서 색 분포 확인하기
face = im[50:300,50:200]
plt.imshow(face[...,::-1])
plt.imshow(cv2.bitwise_and(im,mask)) # 차원이 달라서 연산이 안된다
# error: OpenCV(4.1.2) /io/opencv/modules/core/src/arithm.cpp:229: error: (-209:Sizes of input arguments do not match) The operation is neither 'array op array' (where arrays have the same size and type), nor 'array op scalar', nor 'scalar op array' in function 'binary_op'
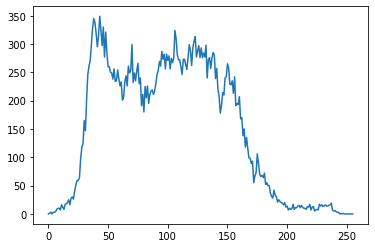
cv2.calcHist([im], [0], mask, [256], [0,256]) # mask외 분포 구할 때
plt.plot(cv2.calcHist([im], [0], mask, [256], [0,256]))
전통적인 머신러닝에서는 contrast가 높으면 이미지 분류가 잘 안되기 때문에 contrast 분포를 평평하게 만들었었다 (contrast normalization)
from skimage.exposure import histogram, rescale_intensity, equalize_hist
from skimage.util import img_as_float, img_as_ubyte
im = cv2.imread('people.jpg')
plt.imshow(img_as_float(im)[...,::-1])
# 이미지는 float나 int 둘다 사람이 볼때는 상관 없다 / 하지만 컴퓨터는 float로 바꾸면 연속적이기 때문에 미분이 가능해진다
x = [1,2,3,4,5,6]
y = np.array(x)
y.cumsum() # 누적합을 빠르게 구하는 방법
# array([ 1, 3, 6, 10, 15, 21])
np.add.accumulate(y)
# array([ 1, 3, 6, 10, 15, 21])
np.add.reduce(y)
# 21
import tensorflow as tf
tf.reduce_sum(y)
# <tf.Tensor: shape=(), dtype=int64, numpy=21>
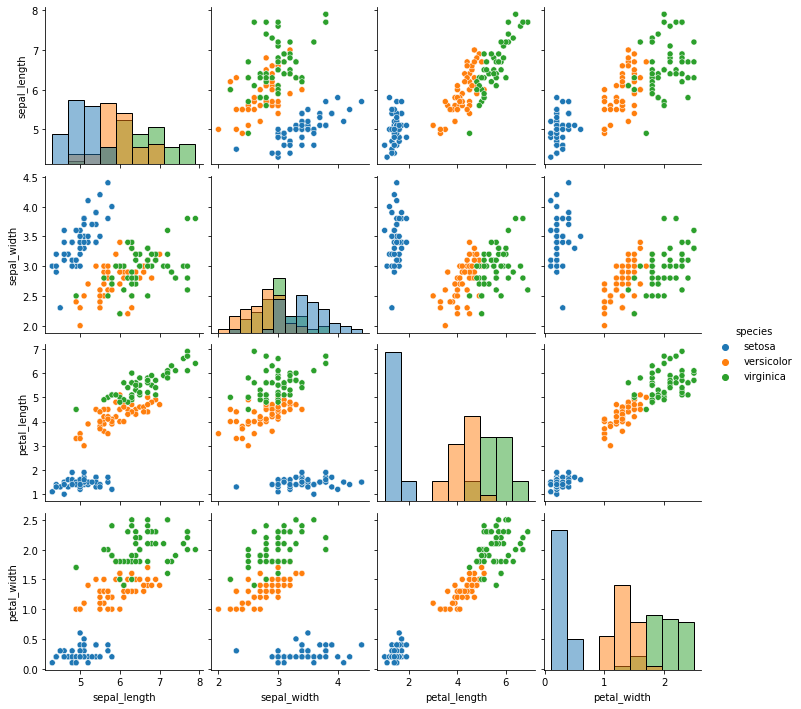
# import seaborn as sns
iris = sns.load_dataset('iris')
sns.pairplot(iris, hue='species', diag_kind='hist') # 데이터에 분포에 따라서 옳바른 데이터인지 아닌지 확인할 수 있기 때문에 그래프를 확인한다
이미지 데이터를 활용하여 어떠한 목적을 달성해야 할때 (머신러닝, 딥러닝을 활용하여 문제 해결을 해야 할때)
충분하지 못한 이미지 데이터를 갖고 있거나, 데이터 품질이 좋지 못할때, 데이터에 표시를 해야 할때등
여러가지 이유에서 목적을 수월하게 달성할 수 있다.
이미지 처리를 위한 python library
1.Scikit-image=>Numpystyle
2.OpenCV=>Cstyle
3.PIL=>Pythonstyle
Scikit-Image
scikit-learn과 비슷한 명명 규칙을 따른다
skimage의 중분류
1. color # 색 변환
2. draw # 이미지내 그림 표시, 문자 표시, 좌표 그리기
from skimage.draw import line, rectangle, circle
from skimage.io import imread
import matplotlib.pyplot as plt
import numpy as np
len(line(0,0,100,100))
# 2
x = np.arange(24).reshape(4,6)
x[[0,1,2],[1,2,3]] # 1, 8, 15 방향의 직선 => a, b = line(0,0,100,200) 와 유사한 인덱싱
# array([ 1, 8, 15])
x
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
h, w = rectangle((20,20),(100,100))
im[h,w] = 0
# 직선과 직사각형이 이미지에 같이 표시되는 이유는 im 객체가 mutable이기 때문에 line함수와 rectangle함수가 적용된 결과가 누적된다
plt.figure(figsize=(6,6))
plt.imshow(im)
h, w = rectangle((300,300),(100,100))
im[h,w] = 0
plt.figure(figsize=(6,6))
plt.imshow(im)
import numpy as np
import cv2 # opencv
im = cv2.imread('people.jpg')
type(im) # opencv로 불러올 때도 im객체가 ndarray이기 때문에 mutable이다
# numpy.ndarray
# im객체가 rectangel이라는 함수를 사용하면 결과가 누적된다 (mutable)
im_r = cv2.rectangle(im, (100,100), (250,250), (255,0,0), 10) # 두번째 인자는 직사각형에서 왼쪽 위 좌표, 오른쪽 아래 좌표 / 세번째 인자는 RGB / 네번째 인자는 테두리 크기
plt.figure(figsize=(6,6))
plt.imshow(im_r);
텍스트 그리기
opencv에서는 font변경이 한정적이기 때문에 기본적으로 한글 사용 불가하다
opencv를 font를 바꾸고 나서 compile하면 한글 사용할 수 있다
beatmap형태를 지원한다
im = cv2.imread('people.jpg')
cv2.putText(im, 'moon', (200,100), 1, 6, (255,0,0), 2) # 이미지 / 텍스트 / 위치 / 폰트 / 폰트크기 / RGB / 두께
for i in dir(cv2):
if 'FONT' in i:
print(i, getattr(cv2, i))
im1 = cv2.imread('people.jpg')
im2 = cv2.imread('apple.jpg')
cv2.addWeighted(im1, 0.7, im2, 0.3, 0) # im1의 불투명도를 70% im2의 불투명도를 30% / 두 개 이미지 shape이 같아야 한다
# error: OpenCV(4.1.2) /io/opencv/modules/core/src/arithm.cpp:663: error: (-209:Sizes of input arguments do not match) The operation is neither 'array op array' (where arrays have the same size and the same number of channels), nor 'array op scalar', nor 'scalar op array' in function 'arithm_op'
im1.shape, im2.shape
((540, 540, 3), (1000, 816, 3))
im2[:540,:540].shape
im2 = im2[250:790,150:690]
blend = cv2.addWeighted(im1, 0.7, im2, 0.3, 0) # 합성 이미지 / blending => 크기와 채널이 같아야 한다 / 두 이미지를 합 할때 가중치를 두고 연산한다 (가중합)
plt.imshow(blend)
Bitwise 연산
a = 20
bin(a)
# '0b10100'
a.bit_length()
# 5
a = 20
b = 21
# 10100
# 10101
# ↓
# 10100
a&b # bitwise and 연산 / 둘 다 1일 때 1, 둘 중 하나라도 0이면 0
# 20
# 10100
# 10101
# ↓
# 10101
a|b # bitwise or 연산 / 둘 중 하나라도 1이면 1, 둘 다 0이면 0
# 21
bin(a),bin(b)
# ('0b10100', '0b10101')
a >> 2 # 두 칸 뒤로 / 10100 => 00101
# 5
a << 2 # 두 칸 앞으로 / 10100 => 1010000
# 80
from PIL import Image, ImageDraw, ImageDraw2, ImageOps
import PIL
im_pil = Image.open('people.jpg')
type(im_pil)
# PIL.JpegImagePlugin.JpegImageFile
dir(PIL.JpegImagePlugin.JpegImageFile)
PIL.JpegImagePlugin.JpegImageFile.__class__
# type
im_pil
type(ImageDraw.ImageDraw) # Class
# type
type(ImageDraw.Draw) # function
# function
draw = ImageDraw.ImageDraw(im_pil) # composition 방식
draw2 = ImageDraw.Draw(im_pil) # function 방식 / function 방식이지만 return이 instacne이기 때문에 헷갈려서 대문자로 만들었다
draw.rectangle(((0,0),(100,100))) # mutable 방식
draw2.rectangle(((100,100),(200,200)))
im_pil
type(ImageOps)
# module
ImageOps.expand(im_pil, 20) # composition 함수 / im_pil이라는 인스턴스를 인자로 넣고 사용하기 때문에 composition 방식이다 / 결과가
텍스트 그리기
im_pil = Image.open('people.jpg')
from PIL import ImageFont
draw = ImageDraw.ImageDraw(im_pil)
draw2 = ImageDraw.Draw(im_pil)
draw.text((120,100),'Chim') # mutable 방식
im_pil
draw.text((100,120),'한글') # 기본적인 방식에서는 한글 지원 안한다
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 0-1: ordinal not in range(256)
!sudo apt-get install -y fonts-nanum # colab에서 사용시 폰트를 다운 받아야 한다
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
for i in dir(cv2):
if 'BORDER_' in i :
print(i, getattr(cv2, i))
BORDER_CONSTANT 0
BORDER_DEFAULT 4
BORDER_ISOLATED 16
BORDER_REFLECT 2
BORDER_REFLECT101 4
BORDER_REFLECT_101 4
BORDER_REPLICATE 1
BORDER_TRANSPARENT 5
BORDER_WRAP 3
im4 = Image.open('people.jpg') # mutable 방식 지원
plt.imshow(im4)
b = np.array(im4)
Image.fromarray(b)
type(b)
# numpy.ndarray
type(im4) # 데이터 구조 자체가 numpy와 다르다 하지만 Numpy와 호환이 된다
# PIL.JpegImagePlugin.JpegImageFile
im4.format_description
# 'JPEG (ISO 10918)'
im4.getexif().keys()
# KeysView(<PIL.Image.Exif object at 0x7f424eb895d0>)
im_pil = Image.open('people.jpg')
R, G, B = im_pil.split() # method 방식
Image.merge('RGB', (R,G,B))
Image.merge('RGB', (B,G,R))
'ImageMode' in dir(PIL) # composition 방식으로 만들어짐
# True
from PIL import ImageMode
ImageMode._modes # Image.merge(mode, bands) 모드 자리에 들어 갈 수 있는 키값들
{'1': <PIL.ImageMode.ModeDescriptor at 0x7f4249d1b350>,
'CMYK': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45bd0>,
'F': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45d50>,
'HSV': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45590>,
'I': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45d90>,
'I;16': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45a50>,
'I;16B': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45f50>,
'I;16BS': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45e90>,
'I;16L': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45410>,
'I;16LS': <PIL.ImageMode.ModeDescriptor at 0x7f4249d450d0>,
'I;16N': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45390>,
'I;16NS': <PIL.ImageMode.ModeDescriptor at 0x7f4249d31610>,
'I;16S': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45ad0>,
'L': <PIL.ImageMode.ModeDescriptor at 0x7f4249d1bd10>,
'LA': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45190>,
'LAB': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45110>,
'La': <PIL.ImageMode.ModeDescriptor at 0x7f4249d457d0>,
'P': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45e50>,
'PA': <PIL.ImageMode.ModeDescriptor at 0x7f4249d452d0>,
'RGB': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45850>,
'RGBA': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45210>,
'RGBX': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45e10>,
'RGBa': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45510>,
'YCbCr': <PIL.ImageMode.ModeDescriptor at 0x7f4249d45a90>}
im_pil.convert('L')
im = tf.io.read_file('people.jpg')
im = tf.image.decode_jpeg(im)
im = imageio.imread('people.jpg') # Array (array 상속) / 다양한 포맷 지원 / 여러 이미지 불러올 수 있다
im = cv2.imread('people.jpg') # c/c++ style / array가 BGR로 구성되어 있다 / opencv는 gpu도 지원하기 때문에 속도가 가장 빠르다
im = Image.open('people.jpg') # numpy와 호환이 되지만 numpy format은 아니다 / PIL이 가장 느리다
plt.imread('people.jpg') # png파일 불러오지 못함
array([[[201, 189, 177],
[203, 191, 179],
[204, 192, 180],
...,
[194, 158, 126],
from skimage import io
im = io.imread('people.jpg')
plt.imshow(im)
im = Image.open('people.jpg')
im2 = im.getdata()
type(im2)
# ImagingCore
list(im2)
'__iter__' in dir(im2)
# False
im2.__class__.mro() # ImagingCore에 __iter__가 있기때문에 반복, 순회 가능
# [ImagingCore, object]
im = Image.open('people.jpg').convert('1') # meta data를 갖고 있기때문에 가능한 방법
im.getcolors()
# [(142786, 0), (148814, 255)]
복습
Stride
a = np.arange(24).reshape(6,4) # 내부적으로는 일렬로 저장된다
a.flags # Information about the memory layout of the array.
# C_CONTIGUOUS : True
# F_CONTIGUOUS : False
# OWNDATA : False
# WRITEABLE : True
# ALIGNED : True
# WRITEBACKIFCOPY : False
# UPDATEIFCOPY : False
a.dtype
# dtype('int64')
a.strides # 1차원의 array를 조립하는 가이드 라인
# (32, 8)
a.itemsize # memory 크기가 8인 정육각형
# 8
a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
a.shape
# (6, 4)
a.sum(0) # axis = 0 기준으로 더한다
# array([60, 66, 72, 78])
a.sum(1) # axis = 1 기준으로 더한다
# array([ 6, 22, 38, 54, 70, 86])
b = np.arange(24).reshape(2,3,4)
b.shape
# (2, 3, 4)
b.sum(axis=1) # shape에서 index 1을 지우면 결과는 (2,4)
array([[12, 15, 18, 21],
[48, 51, 54, 57]])
b.sum(axis=2) # shape에서 index 2를 지우면 결과는 (2,3)
array([[ 6, 22, 38],
[54, 70, 86]])
with open('Elon.jpg', 'rb') as f: # 기본 옵션 r은 unicode형식으로 불러온다 / rb는 바이너리로 불러온다
print(f.read()) # 파이썬에서는 이미지는 불러올수는 있지만 각각의 값이 어떤 색을 표현하는지 해석할 수 없다
# b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00II*\x00\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xff\xec\x00\x11Ducky\x00\x01\x00\x04...
import tensorflow as tf
im = tf.io.read_file('Elon.jpg') # vectorization으로 불러온다 / array연산을 최적화 하도록 불러온다
im
# <tf.Tensor: shape=(), dtype=string, numpy=b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00II*\x00\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x0
# .numpy() 하면 기타정보 빼고 내용만 보여줌
im.numpy()
# b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00II*\x00\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xff\xec\x00\x11Ducky\x00\x01\x00\x04
이미지를 불러올 때 tensor가 좋은 점은 gpu연산이 가능하기 때문에 대용량 이미지를 더 빠르게 불러올 수 있다
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
plt.imshow(t) # array를 image로 해석하는 방법을 제공한다 / version 때문에 tensor를 직접 표현 못할 수 있다. 혹시 안된다면 colabd으로 사용해 보는 것을 추천한다
plt.colorbar(); # 컬러바 표시하기
plt.axis('off'); # 좌표 축 없애기
# 같은 셀안에서 실행하면
plt.figure();
plt.axes([0.5,0.5,1,1]); # figure 안에서 좌표형태로 보여준다
plt.plot([4,5,4]);
plt.axes([0,0,0.5,0.5]);
plt.plot([4,5,4]);
plt.axes([0,0,0.5,0.5])
# plt.figure()
# plt.axes()
plt.plot([1,2,3]) # plot만 하면 figure, axes default값으로 자동 지정된다
s = t / 255
t.dtype
# tf.uint8
s.dtype
# tf.float32
plt.imshow(s) # 이미지를 구성하는 값들은 상대적인 개념이기 때문에 특정 값을 기준으로 나누어도 사람이 볼때는 똑같은 이미지로 볼 수 있다
im = tf.io.read_file('Elon.jpg')
t = tf.image.decode_image(im)
ss = tf.cast(t, 'float32')
ss.dtype
# tf.float32
sss = (ss/127.5) -1 # -1에서 1 사이로 변환해주는 방법 / 가장 큰 값이 255이기 때문에 절반으로 나누고 1을 빼면 -1과 1 사이의 값으로 구성된다
import numpy as np
np.min(sss)
# -1.0
plt.imshow(sss) # imshow는 -1값은 표현하지 못하기 때문에 달라 보인다
def visualize_bw(img):
w, h = img.shape
plt.figure(figsize=(10,10))
plt.imshow(img, cmap='binary') # binary는 작은 숫자가 밝게 / gray는 큰 숫자가 밝게
for i in range(w):
for j in range(h):
x = img[j,i]
plt.annotate(x, xy=(i,j), horizontalalignment='center', verticalalignment='center', color = 'black' if x <= 128 else 'white') # 점 하나당 대체 시킨다
visualize_bw(X_train[0])
Image processing
input image가 어떠한 함수에 의해 새로운 image가 output으로 나오는 것
array연산을 통해서 새로운 형태의 image를 만들어 내는 것
visualize_bw(X_train[5][::-1])
# 뒤집기
visualize_bw(X_train[5][4:24,4:24])
# 잘라내기
visualize_bw(np.flipud(X_train[5])) # flipud => 이미지 뒤집기
# 크기가 (20,20)인 흑백 이미지 생성
visualize_bw(np.ones((20,20)))
# pascal voc 2012 데이터를 다운로드 후 /content/data 디렉토리에 압축 해제
# DOWNLOAD시 약 3분정도 시간 소요. 아래 디렉토리가 잘 동작하지 않을 경우 https://web.archive.org/web/20140815141459/http://pascallin.ecs.soton.ac.uk/challenges/VOC/voc2012/VOCtrainval_11-May-2012.tar
!mkdir ./data
!wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
!tar -xvf VOCtrainval_11-May-2012.tar -C /content/data
import cv2
import matplotlib.pyplot as plt
import os
%matplotlib inline
# 코랩 버전은 상대 경로를 사용하지 않습니다. /content 디렉토리를 기준으로 절대 경로를 이용합니다.
# default_dir 은 /content/data 로 지정하고 os.path.join()으로 상세 파일/디렉토리를 지정합니다.
default_dir = '/content/data'
img = cv2.imread(os.path.join(default_dir, 'VOCdevkit/VOC2012/JPEGImages/2007_000032.jpg'))
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print('img shape:', img.shape)
plt.figure(figsize=(8, 8))
plt.imshow(img_rgb)
plt.show()
img shape : (281, 500, 3)
# annotation 확인하면 object 설정 상태 확인 =>aeroplane, aeroplane, person, person